本篇说明
1.我们应该设计一种什么样的评估方法? 2.我们要评估哪些指标? 3.我们怎么比较评估指标的优劣?
经验误差与过拟合
按照上一章所说的,由训练集得出的模型可能是不同的假设。除了利用归纳偏好之外,我们还可以用一些指标来进行评估和选择不同的模型。通常我们有:
- 错误率:分类任务中分类错误的样本数占样本总数的比例 。
- 精度: 。
- 误差:模型实际预测输出的结果和真实样本输出之间的差异。
- 训练误差:模型在训练集上的误差。
- 泛化误差:模型在新样本上的误差,但难以获得新样本的整体,泛化误差不能够计算出来。
- 过拟合:模型在训练集上预测的很好,从而导致泛化能力变弱。常见原因有模型学习能力过强、数据太简单等。过拟合是无法避免的,我们只能“缓解”过拟合。
- 欠拟合:模型难以在训练集和新样本上预测的很好,往往是模型学习能力低下、训练轮次不足等。
- 测试集:从真实样本分布中 i.i.d. 采样出的测试样本集合。测试集和训练集应该保持互斥 。
- 测试误差:使用测试集来测试模型的误差作为泛化误差的近似。
数据集的划分
训练集 和测试集 的区分是我们人为规定出来的,面对从 i.i.d. 假设中采样出来的海量数据,我们可以通过留出法、K 折交叉检验法、自助法等来划分数据集。一般的我们的数据可以分成三组:
- 训练集:用于训练模型。
- 测试集:估计模型在实际使用中的泛化性能。
- 验证集:模型选择和超参数调整。
留出法(hold-out)
留出法只需要设定训练集和测试集的比例即可划分,除了随机按比例划分,我们应当尽可能保持训练集和测试集的数据分布的一致性。例如分类问题中要保持不同类别比例相似,也可以说这是 “分层采样” 。但是留出法也存在一些问题:
- 留出法的使用会导致训练集和测试集可能不尽相同,导致结果偏差不够稳定,我们也可以通过多次划分、重复实验求平均的方式来缓解,将平均指标作为模型的评估结果。
- 留出法中训练/测试集比例的划分会影响评估结果的准确性、保真性。
K 折交叉验证法(K-fold)
交叉验证法将数据集划分为 个大小相似的互斥子集,每个子集尽量保持数据分布的一致性。然后选定 组为测试集,其余 组为训练集,就可以得到 组训练/测试集。最后我们将 组测试结果的均值作为模型的评估结果。通常我们选取 。
由于将数据分成 组存在多种划分,也可以采取多次 K 折交叉验证,例如“10次10折交叉验证”。特殊的,当 时,则称为留一法(LOO)。留一法由于训练样本的充足,往往认为其评估结果比较准确,但是当数据量较大时,训练时则会加大计算开销。同时考虑到NFL定理,其结果也未必永远是准确的。
自助法(Bootstrapping)
自助法相当于对包含 个样本的数据集 进行 次可重复无放回的采样得到数据集 。这样一来样本在 次采样中始终不被采到的概率是 ,由某重要极限可以知道,初始数据集中约 36.8% 的数据没有出现在 。则 用作训练集, 用作测试集。
性能度量
错误率与精度
查准率(准确率)、查全率(召回率)和F1分数
对于二分类问题,样例可以按照真实类别和预测类别组合成真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)。查准率(Precision)定义为: ,查全率(Recall)定义为: 。一般来说P、R是一对相互矛盾的度量,为了综合考量两者,我们常用 PR曲线:
绘图过程:
- 模型对测试数据进行预测;
- 将测试结果按照预测为正类的概率排序;
- 设定概率阈值为1逐渐降低,依次将每一个样本纳入“预测为正样本”的队伍,计算此时的P、R;
- 以查准率作为纵轴、查全率作为横轴,画出PR曲线。
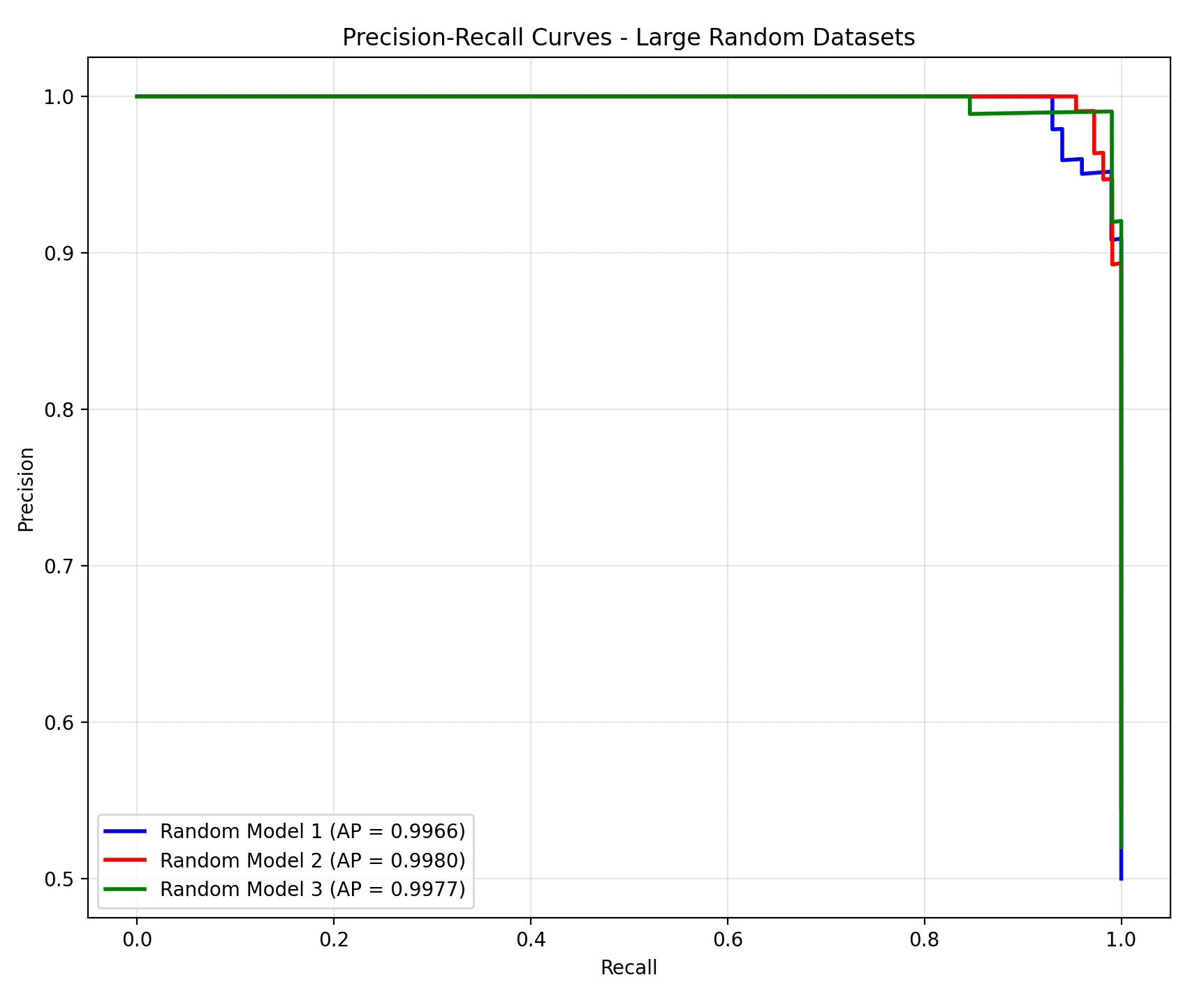
对于 PR 曲线我们可以通过以下几种方式判断模型的优劣:
- 曲线下面积(AP):越大越好。
- 平衡点(BEP):是 的点,越大越好。
- F1-Score:是 P 和 R 的调和平均数, ,越大越好。
- 除此之外,针对不同的任务场景,还有 、 、 、 、 、 、 。
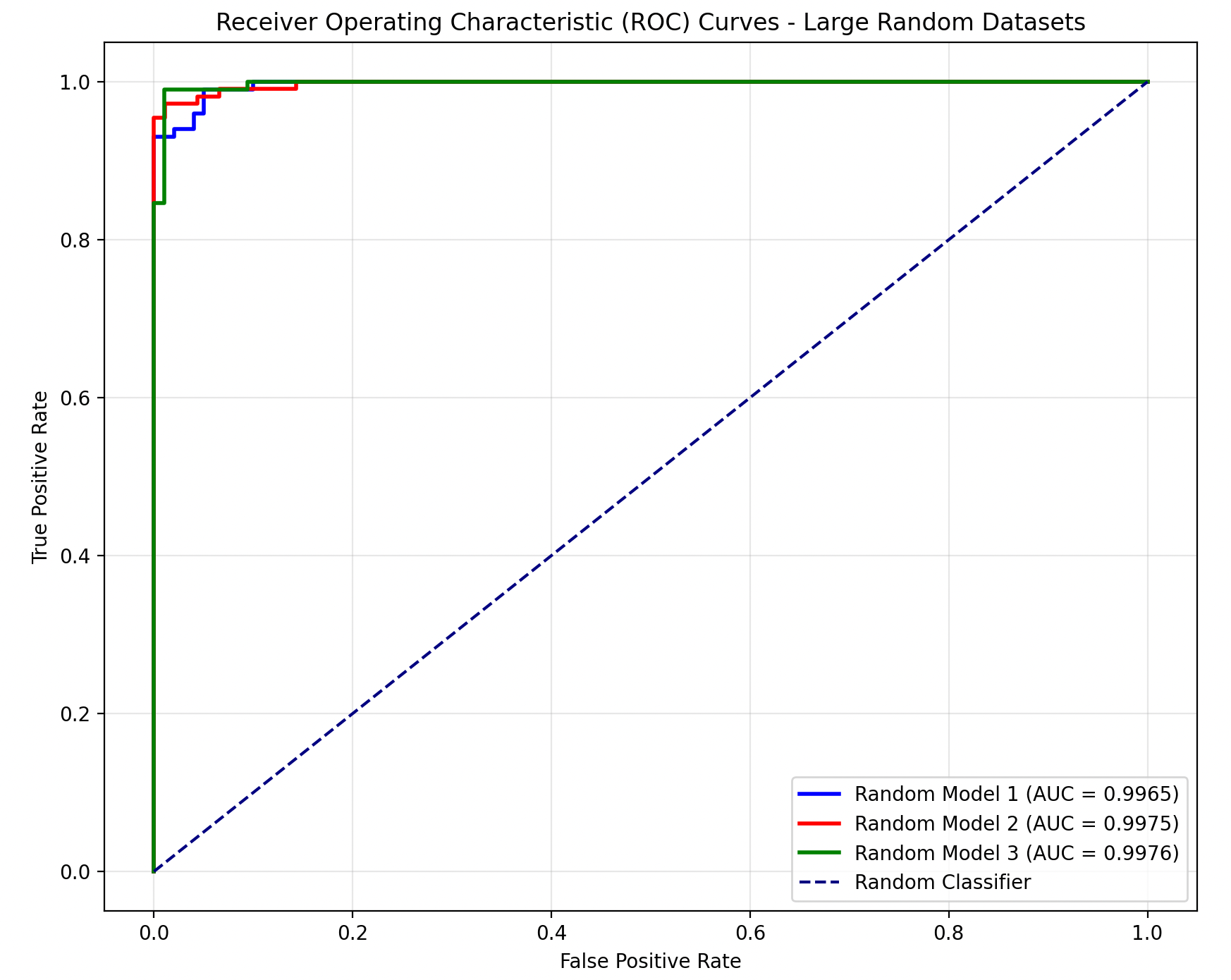
ROC 和 AUC
ROC 曲线全称是“受试者工作特征”,其计算方法和 PR 曲线一致,不过是计算以下两个指标:真正例率 、假正例率 。这时其曲线下的面积就是 AUC,比较方法和 PR 曲线类似。
比较检验
偏差与方差
在基于均方误差的回归任务中,我们得以推到出:泛化误差可以分解为偏差、方差和噪声之和。
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力。
- 方差:度量了同样大小的训练集的变动导致的学习性能的变化,刻画了数据扰动所造成的影响。
- 噪声:表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
这一分解说明了泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。
结语