一、问题
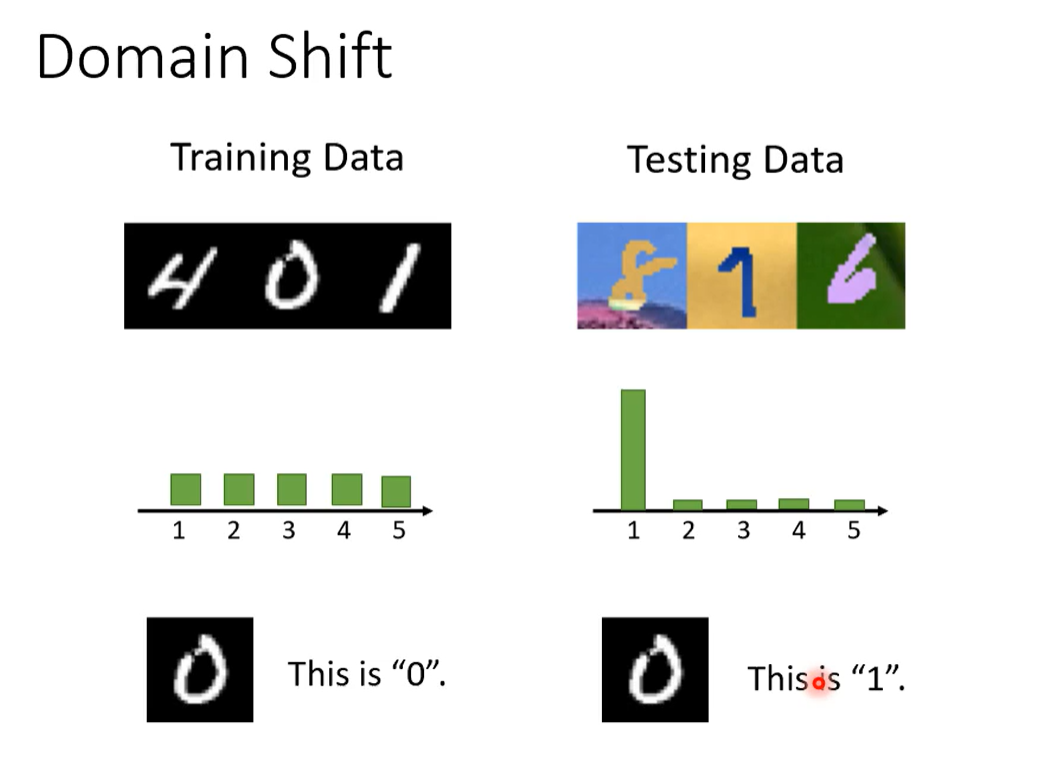
我们再训练集上进行训练,在测试集上进行测试。
当测试集的数据不和训练集上的数据一致时,我们的结果反而不会好。
训练资料和测试资料的分布不同。

也可以看做迁移学习的一种。
问题:
- 输出的分布也不一样。
- 概念变化。
二、领域自适应
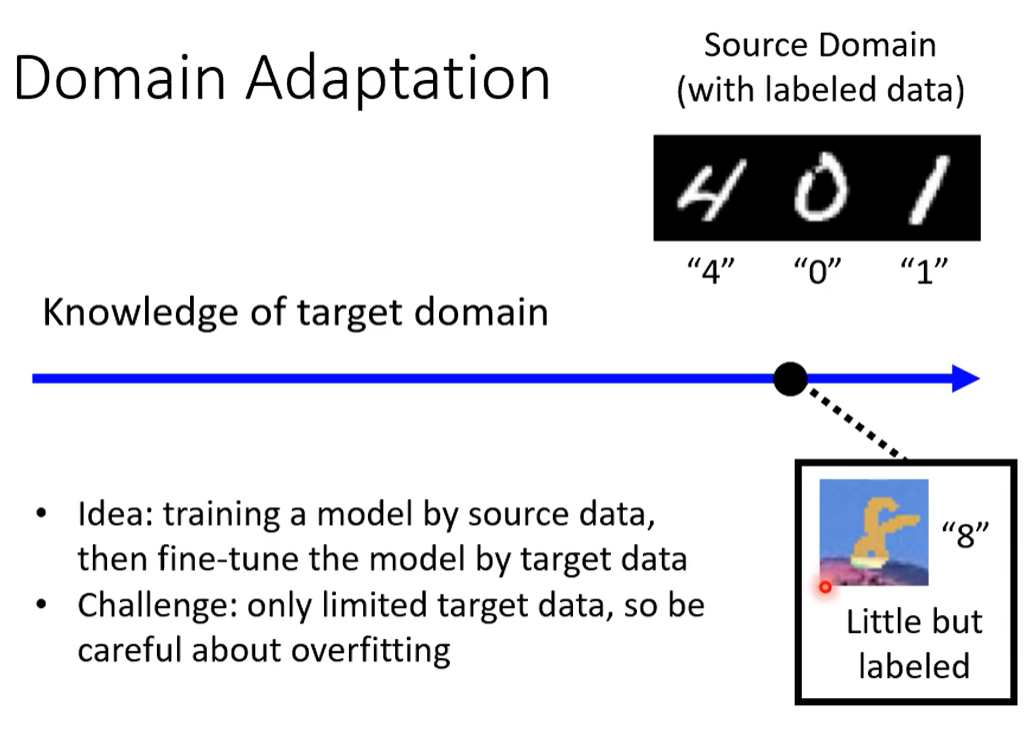
情况一:小量但标注
原来训练资料上进行训练,在目标数据上进行微调。
问题:目标数据过少时,可能过拟合。
情况二:大量未标注
做法:
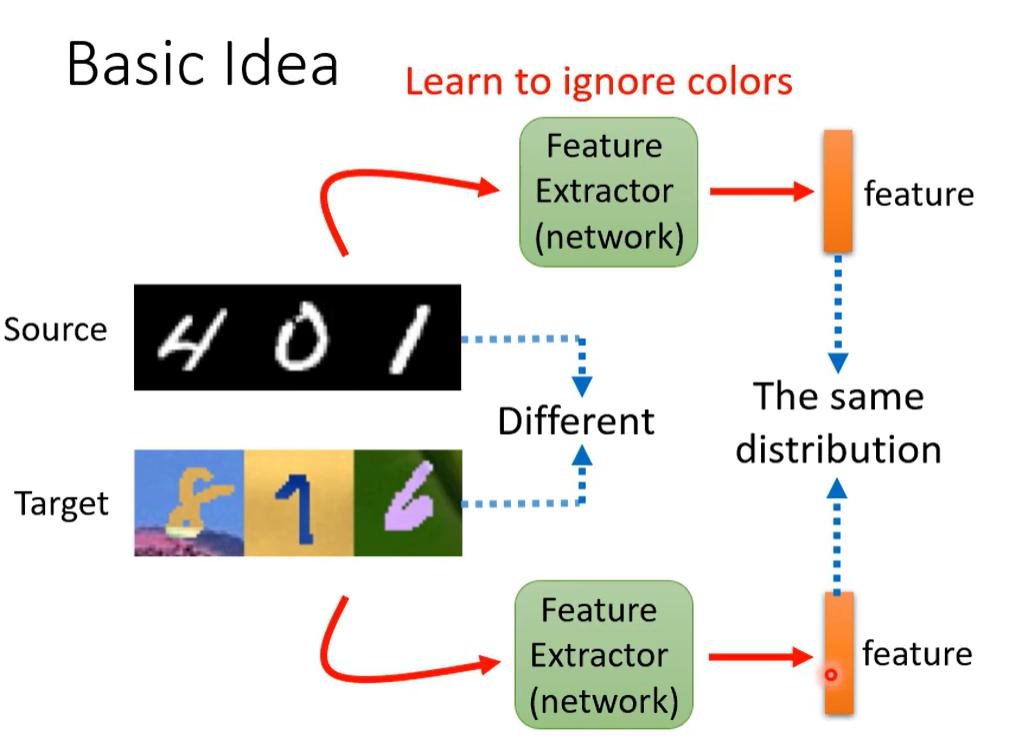
领域自适应学习:
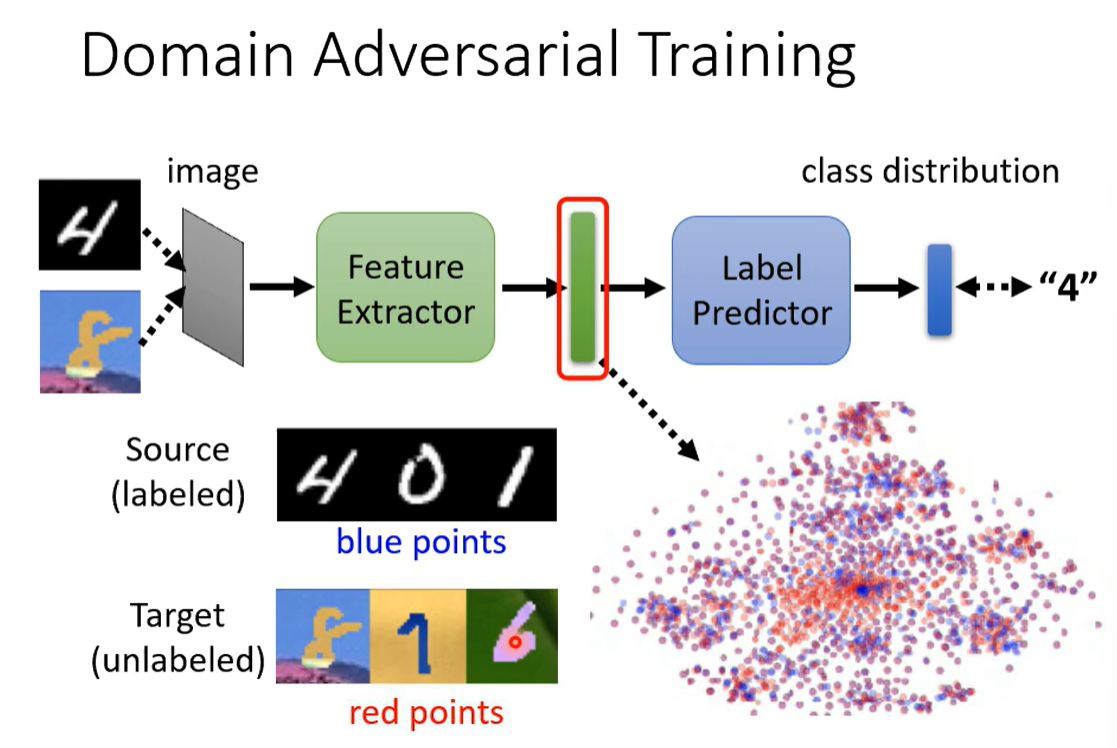
使得原有资料和目标资料的特征分布差异不大。
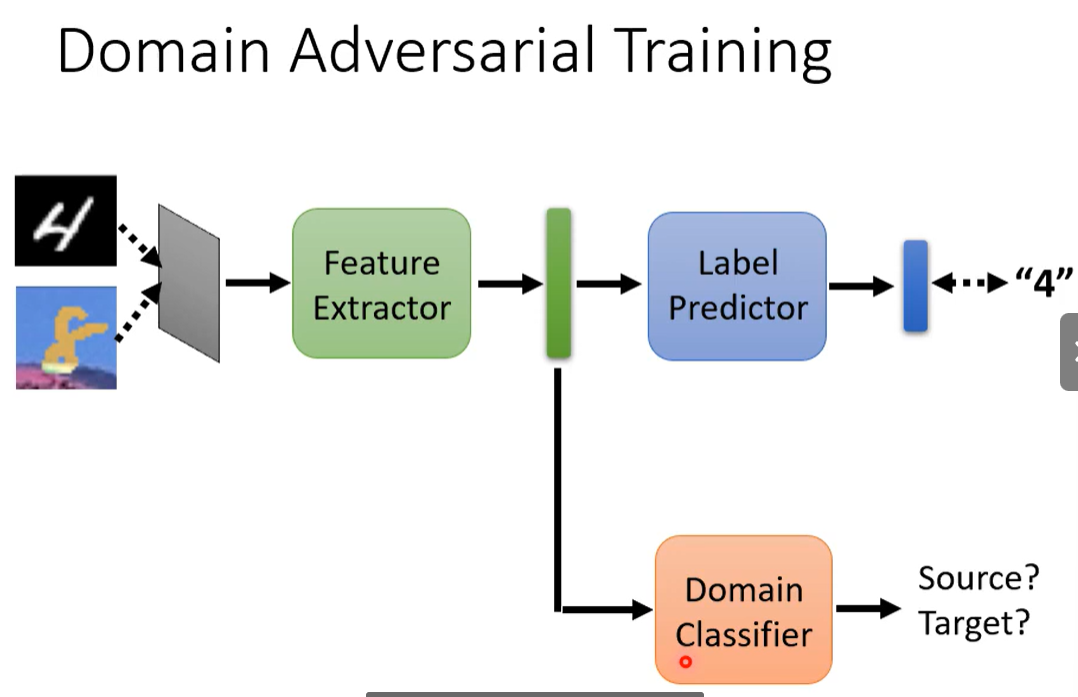
所以训练一个
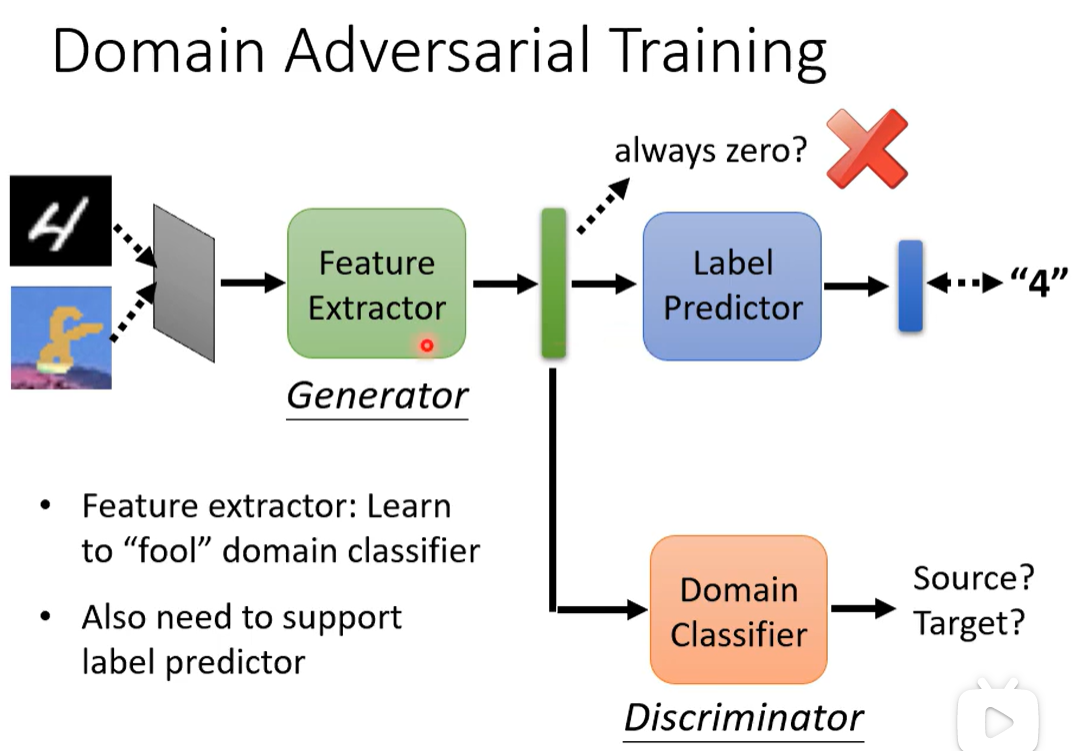
领域分类器。Like GAN。
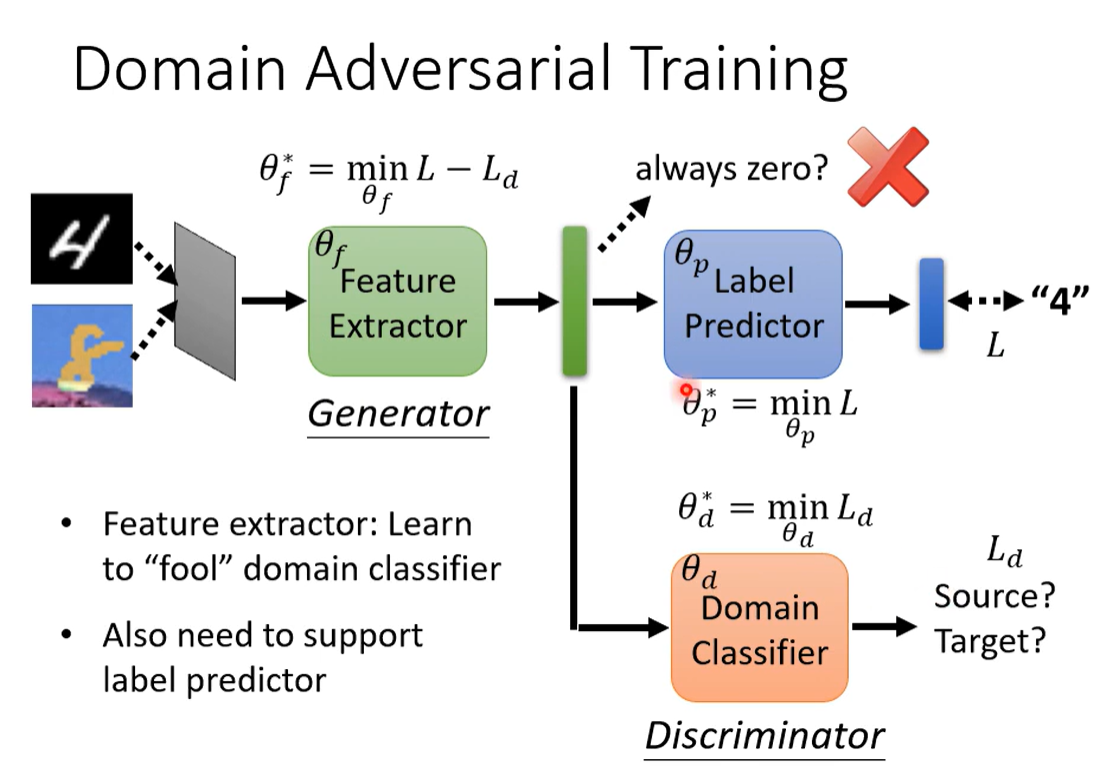
也需要去支持标签预测器,所以不会出现全零。
情况三:
小量未标注
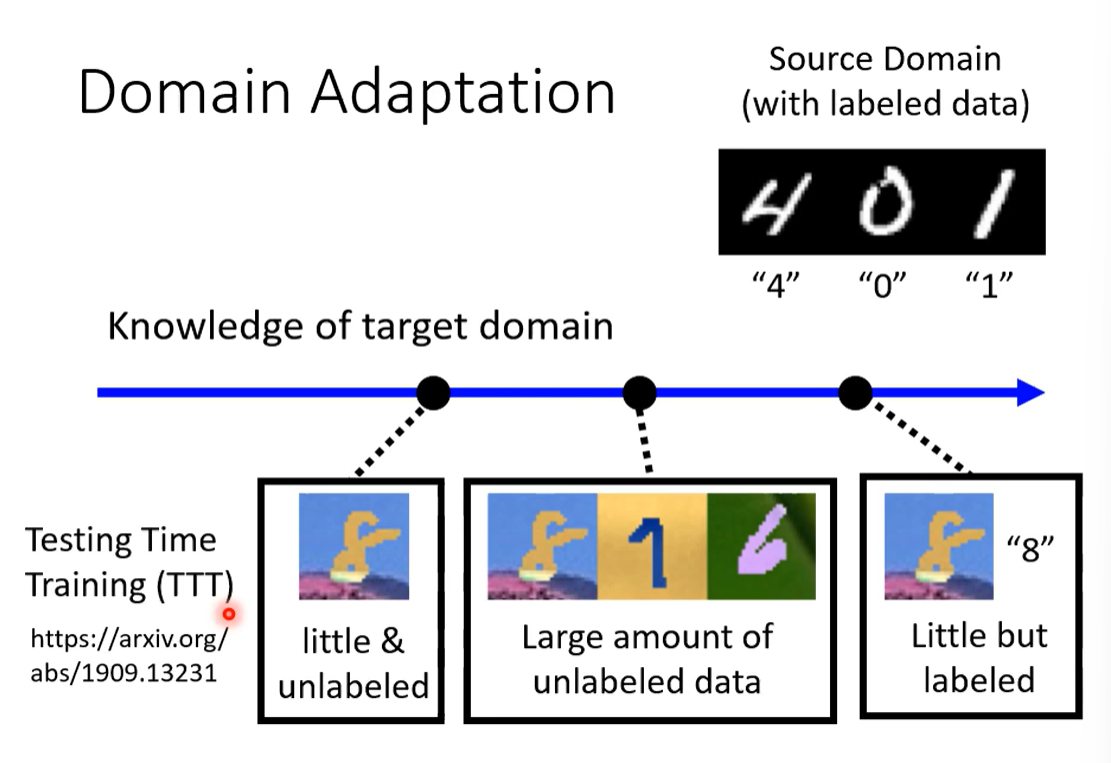
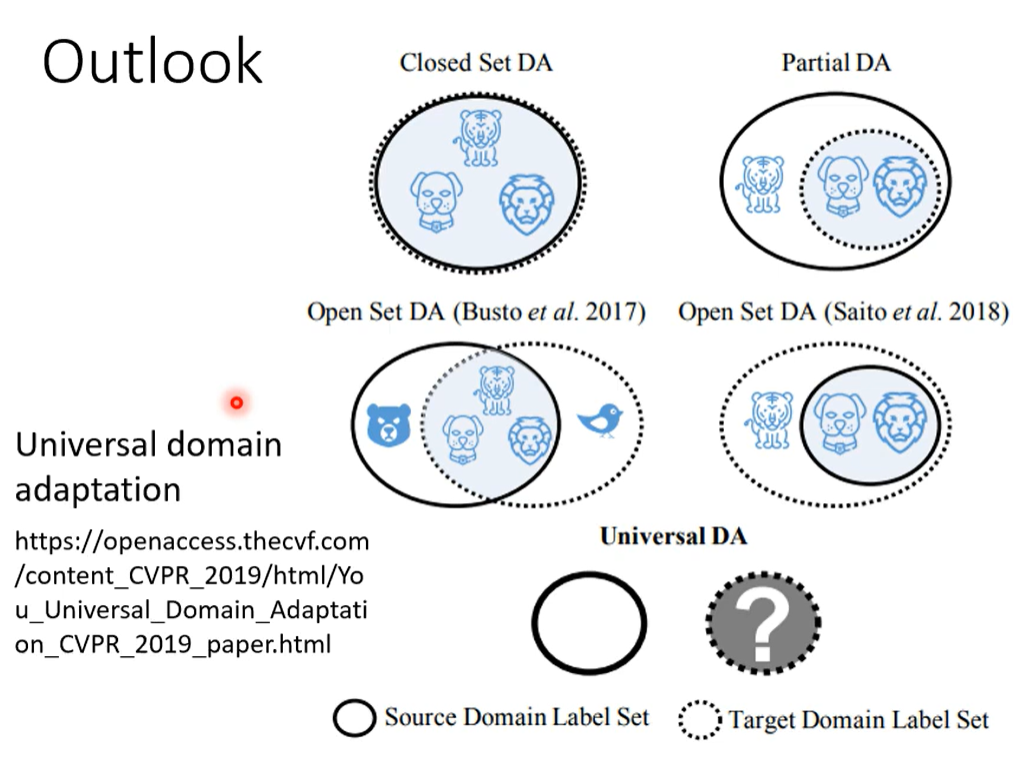
情况四:什么都不知道
即领域生成。
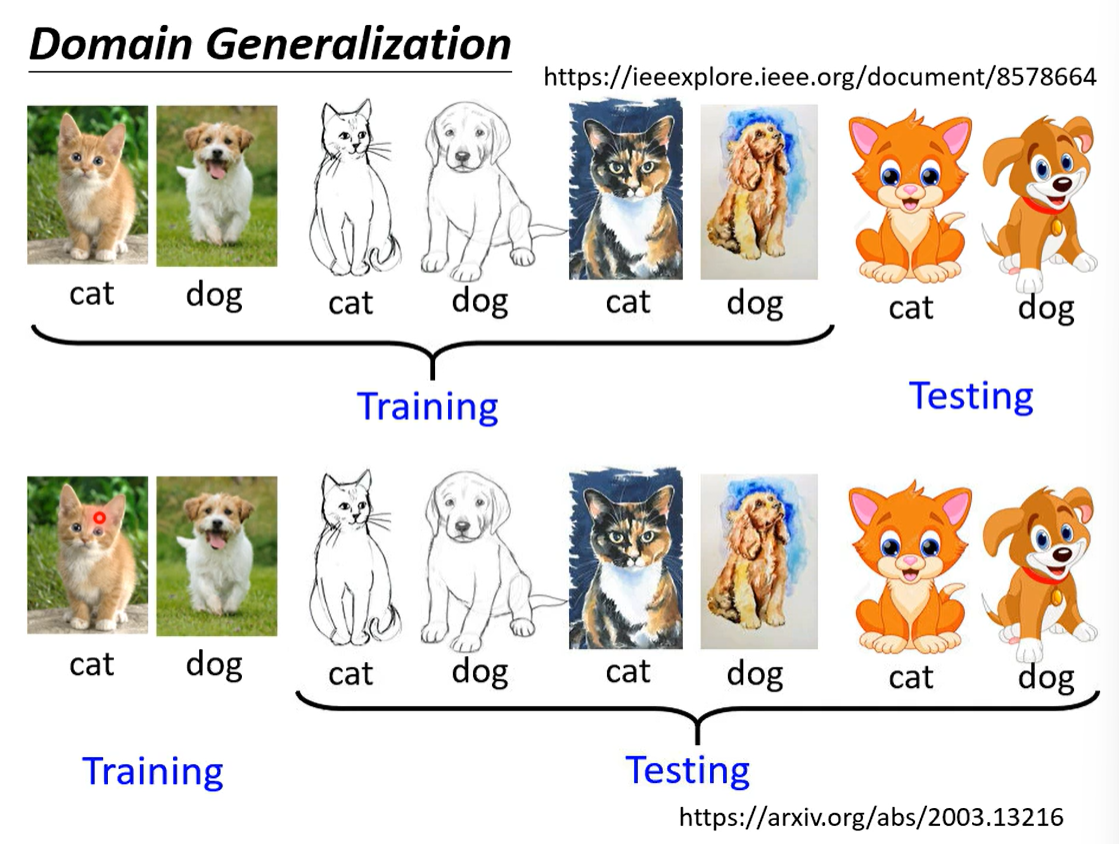
三、限制
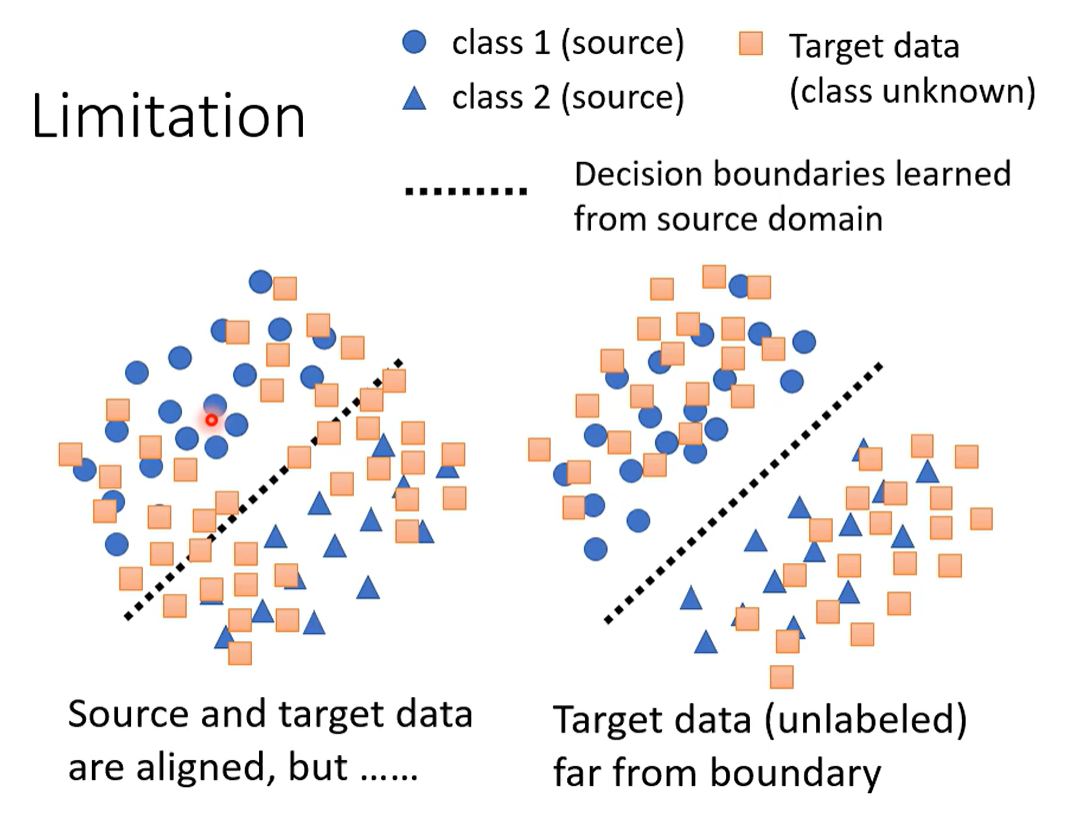
远离边界。
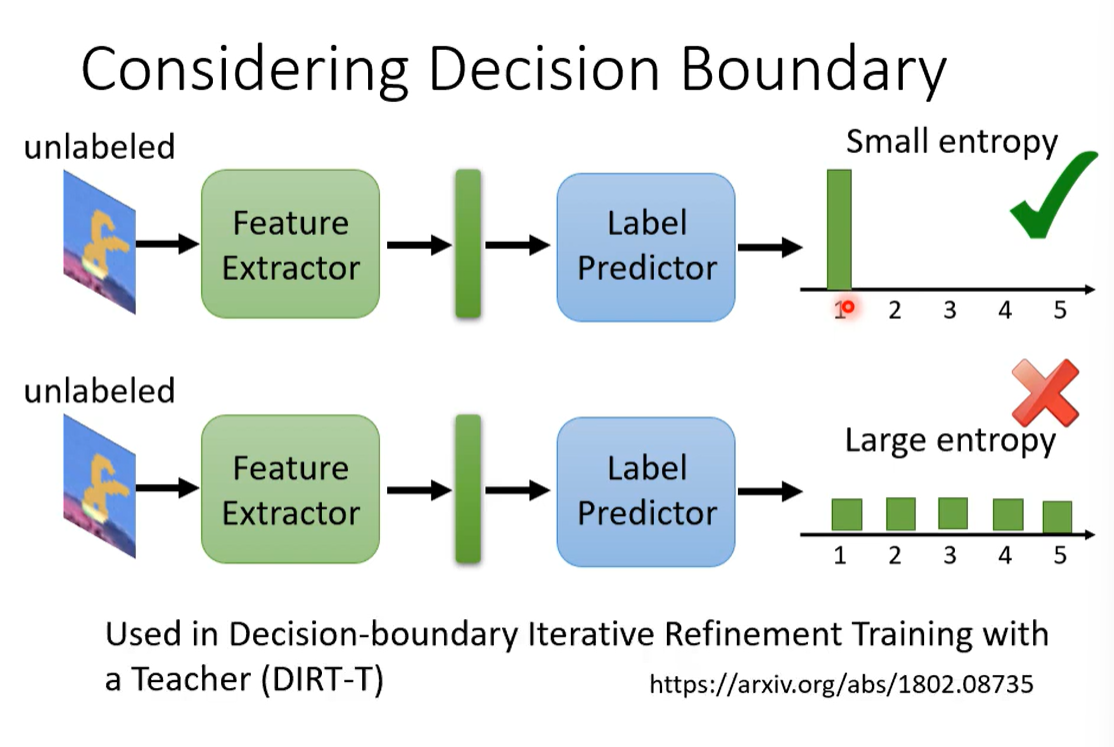
训练标签和测试标签不一样: