一、引入
当处理的输入向量长度不一样,且有多个向量输入的时候。
例如:文字处理。
对每一个文字进行One-Hot编码。(词汇之间没有关系)。
对文字进行词嵌入。
输出则会有三种可能:
① 和输入向量一样多Sequence Labeling
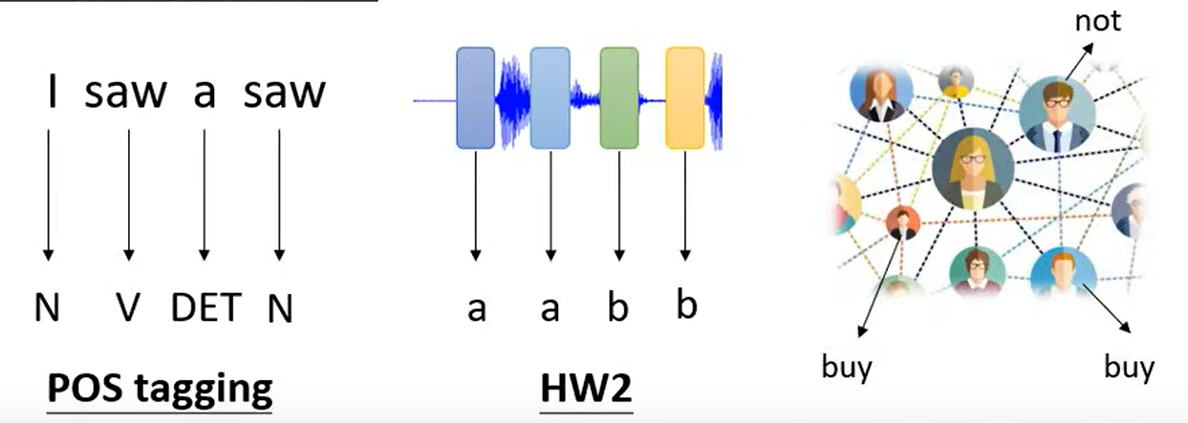
② 一个输出
③ 输出任意个向量Seq2Seq

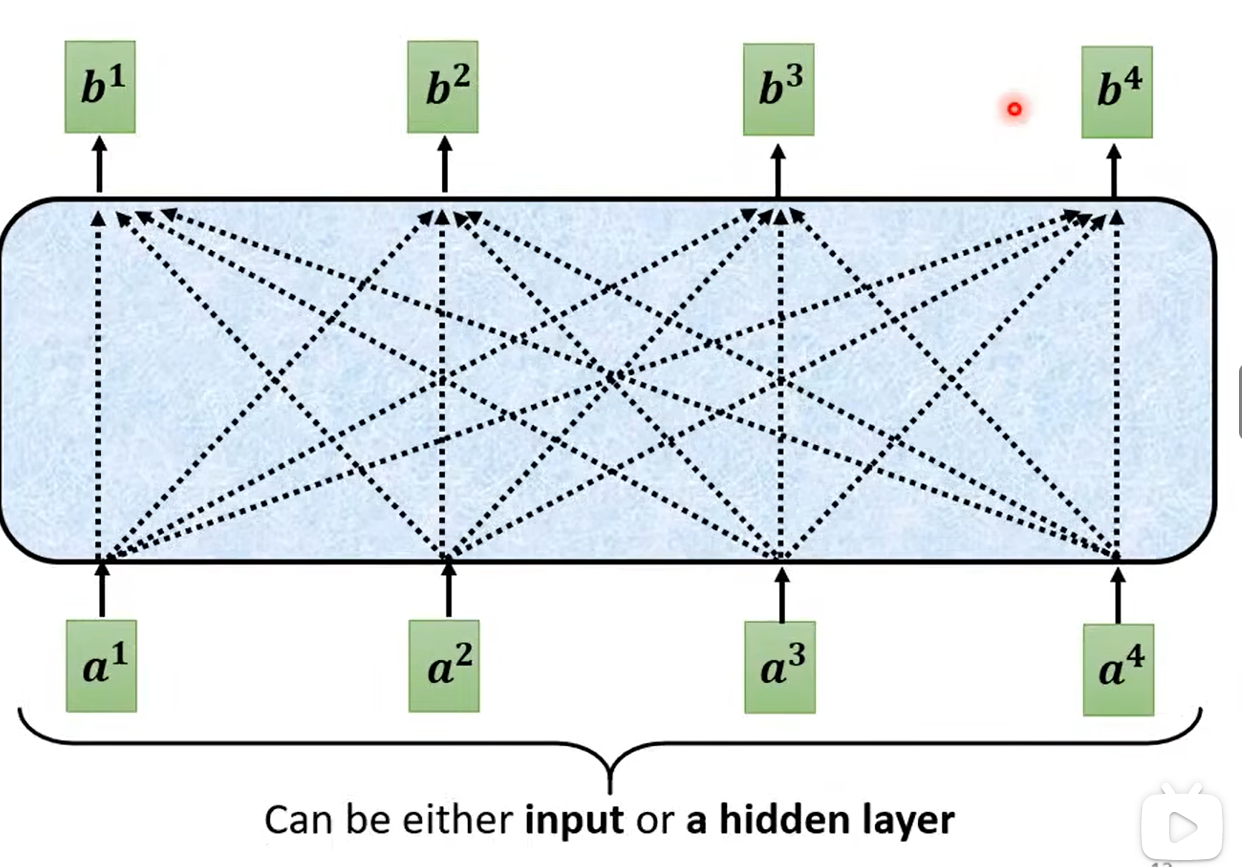
二、自注意力机制
自注意力机制维护了一整个句子的上下文。
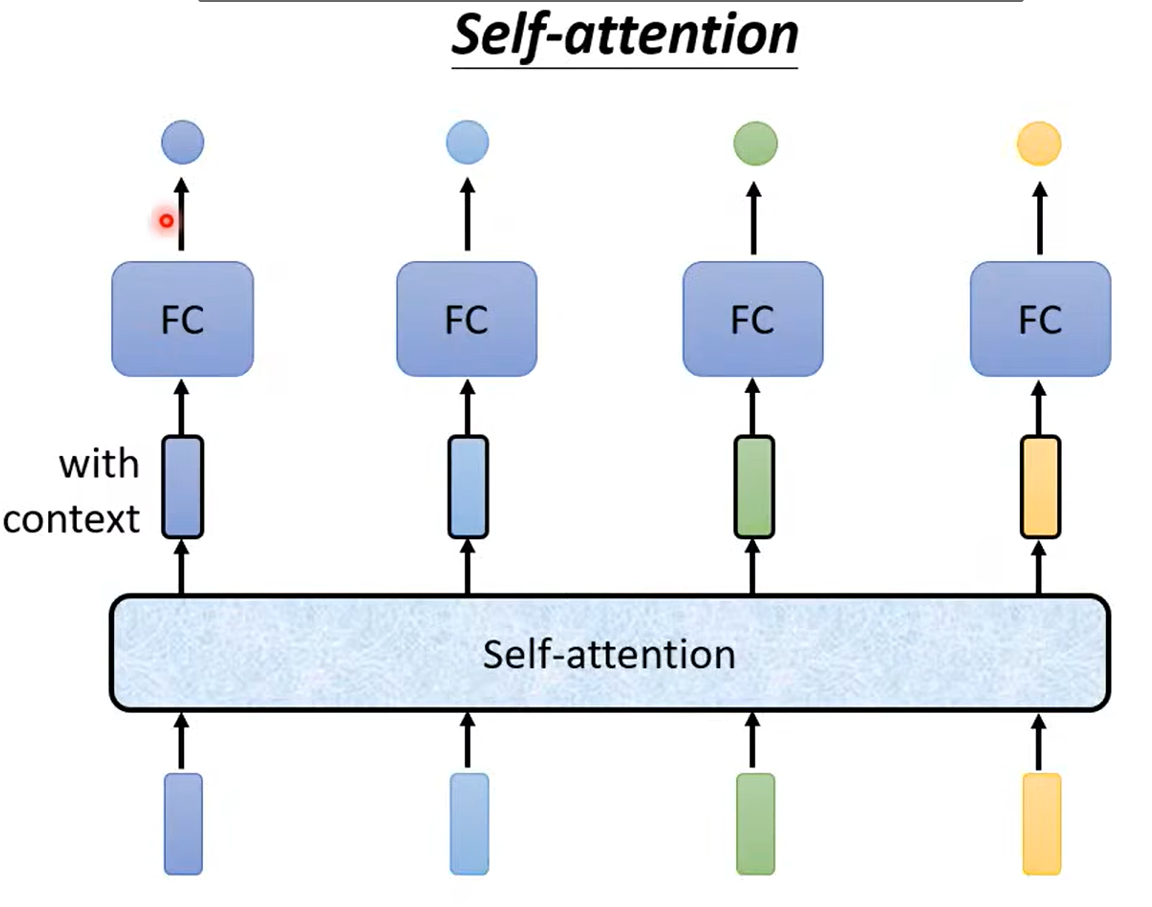
其中自注意力机制可以继续叠加,对整个上下文产生更好的维护。
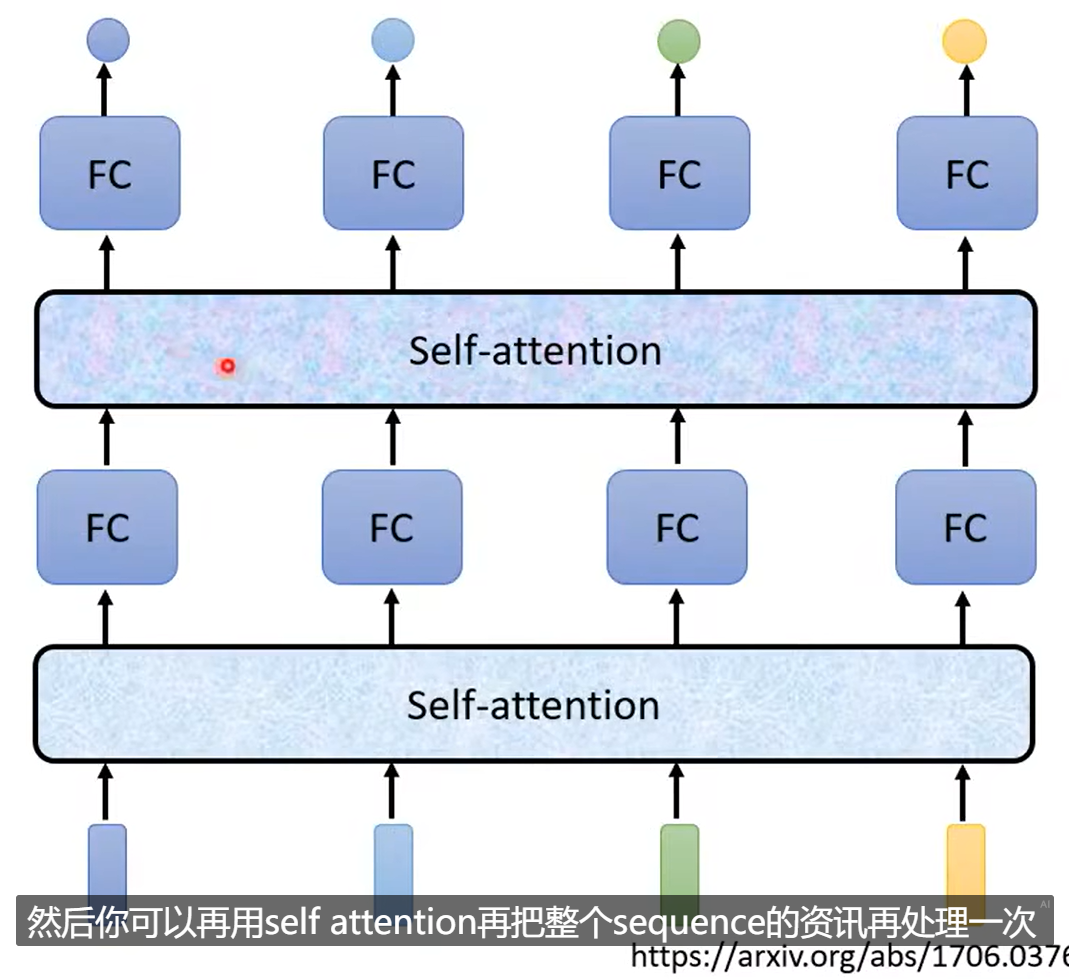
FC处理局部的资讯,自注意力维护全局资讯。
而对自注意力机制的最好运用就是Attention is all you need。
提出了 Transformer。
三、自注意力机制
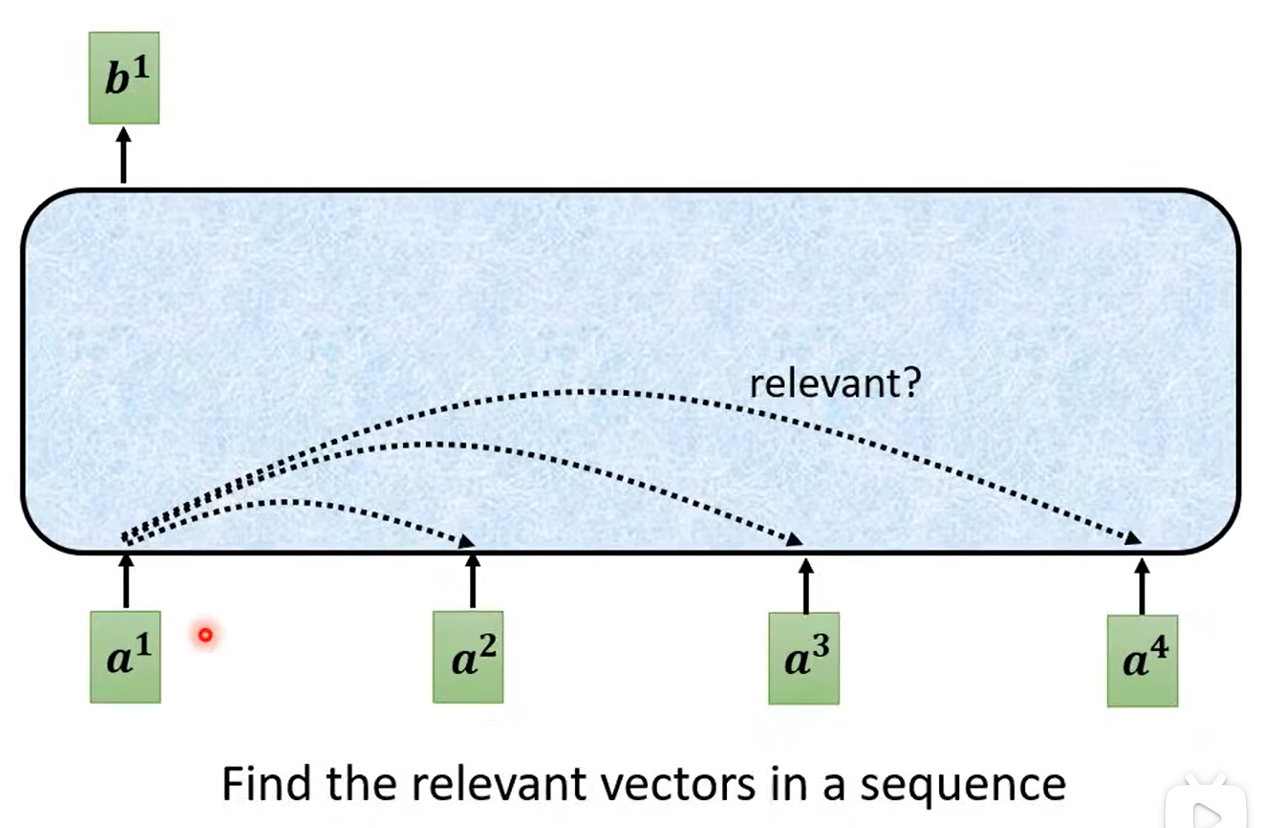
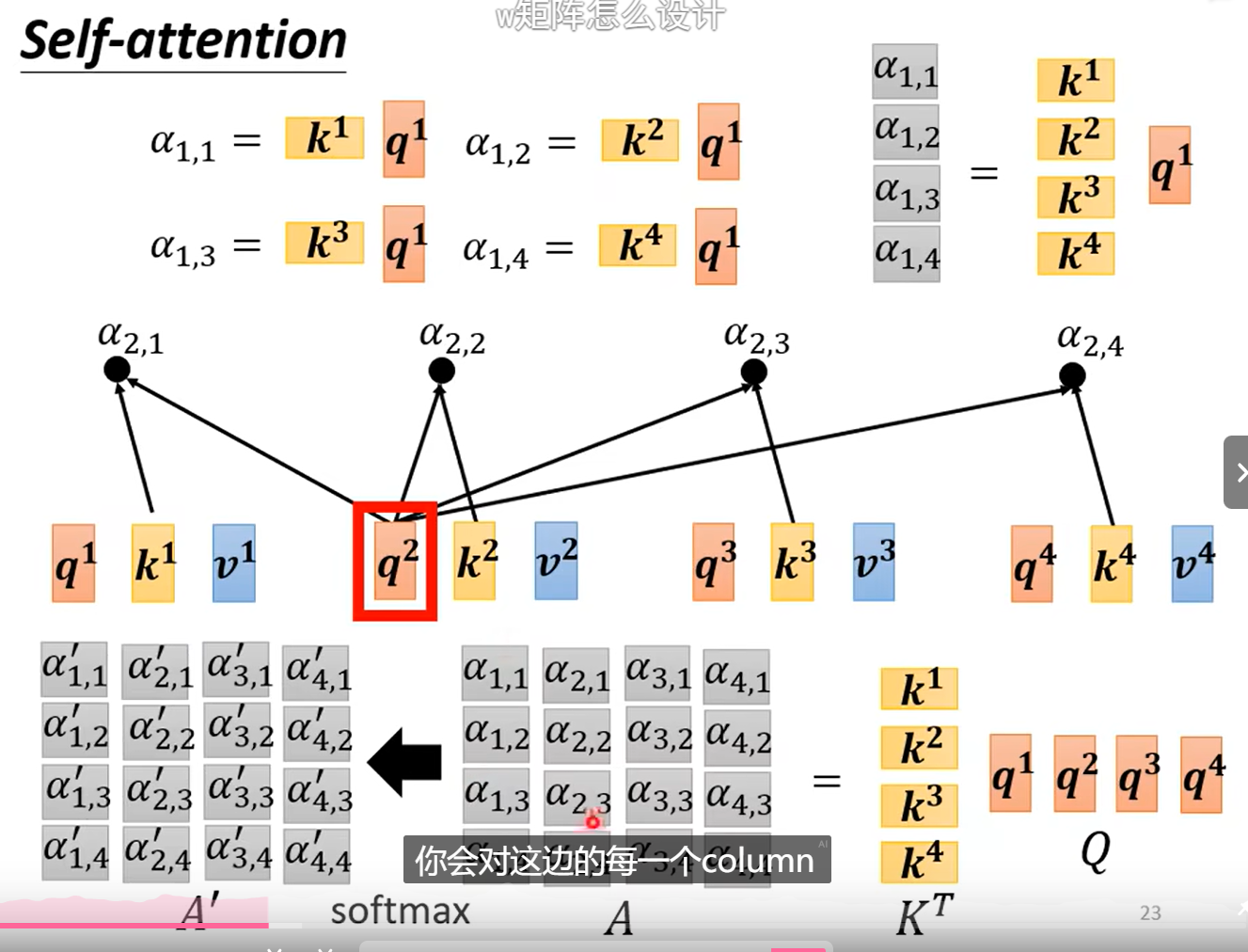
步骤:查询其他词汇对当前词汇的相关度α
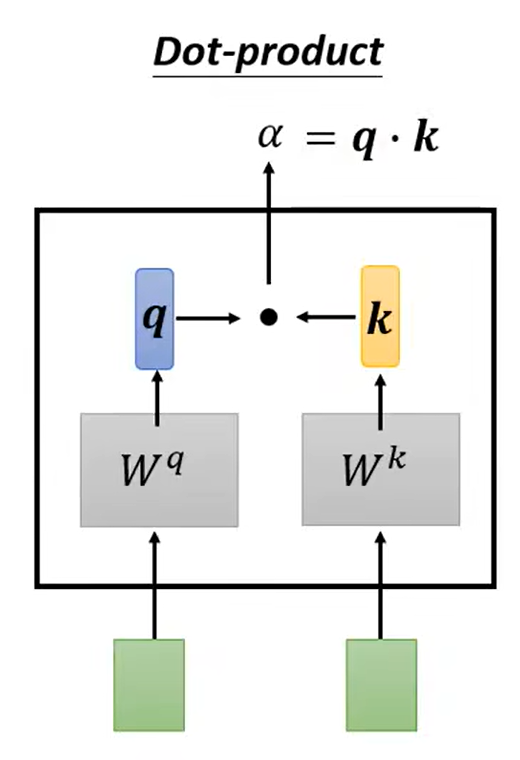
1.1 计算注意力
一种使用Dot-product法。注意这里不是点乘。
一种使用Additive法。
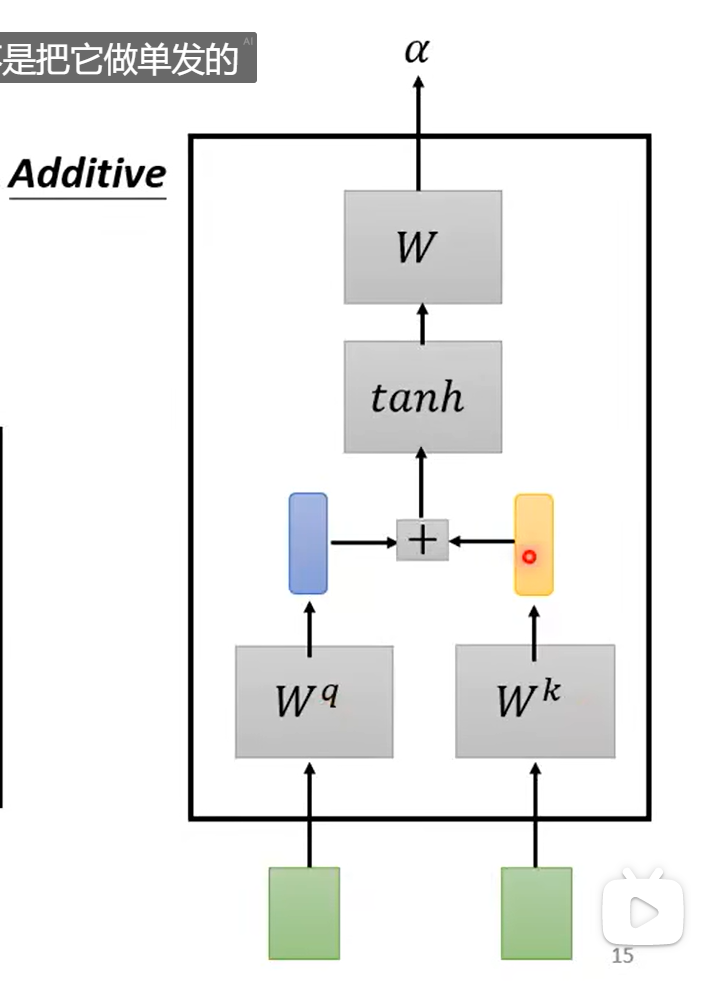
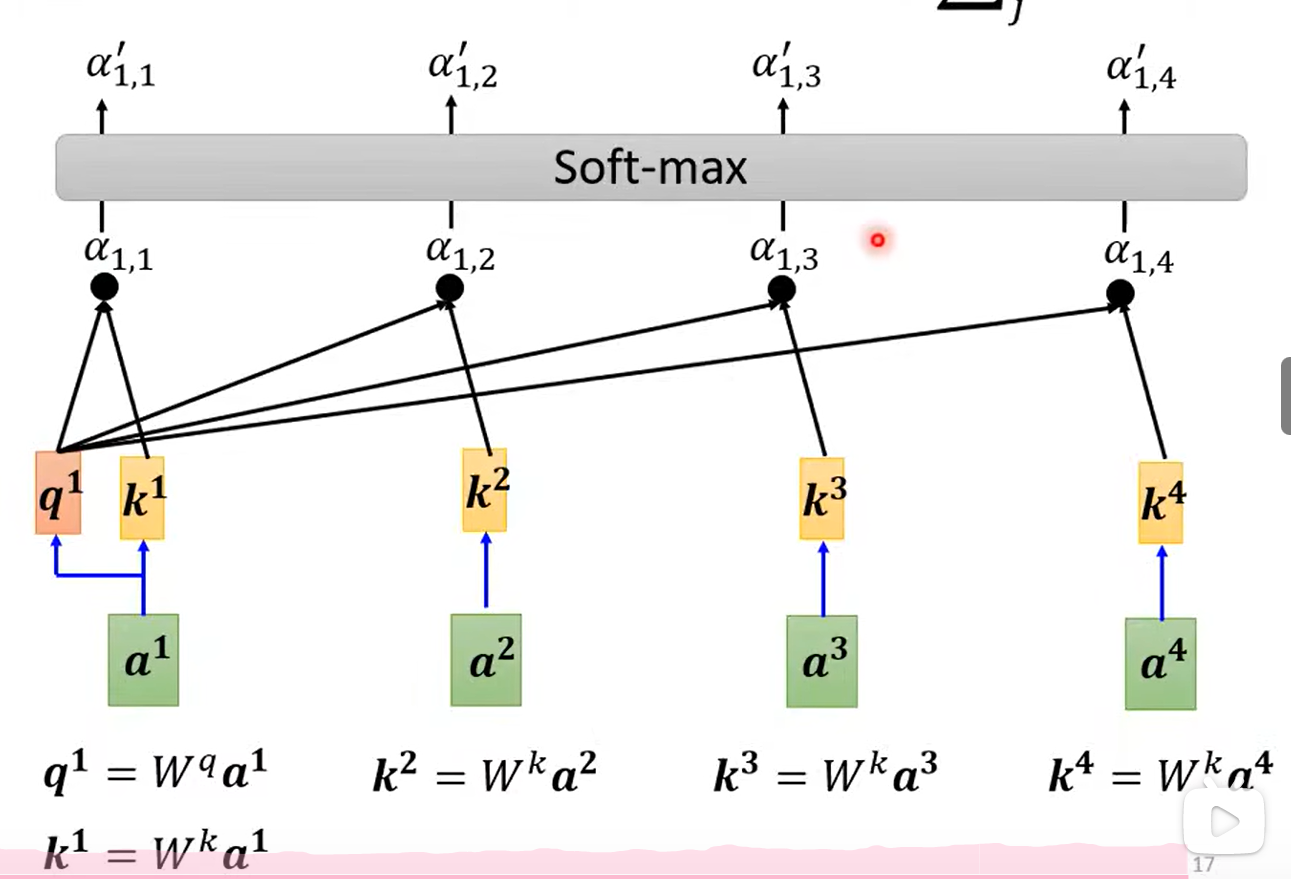
1.2 计算相关度
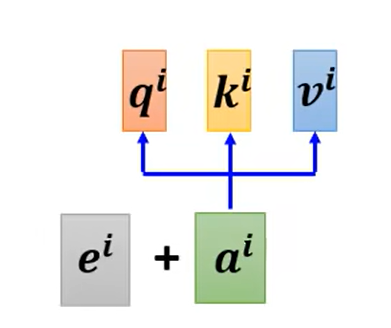
当前词汇乘以q查询矩阵。
其余词汇(自己和自己也会计算关联)乘以k键矩阵。
计算出来注意力分数。
进行Softmax操作。(ReLU也行)
从而得出关联度α。
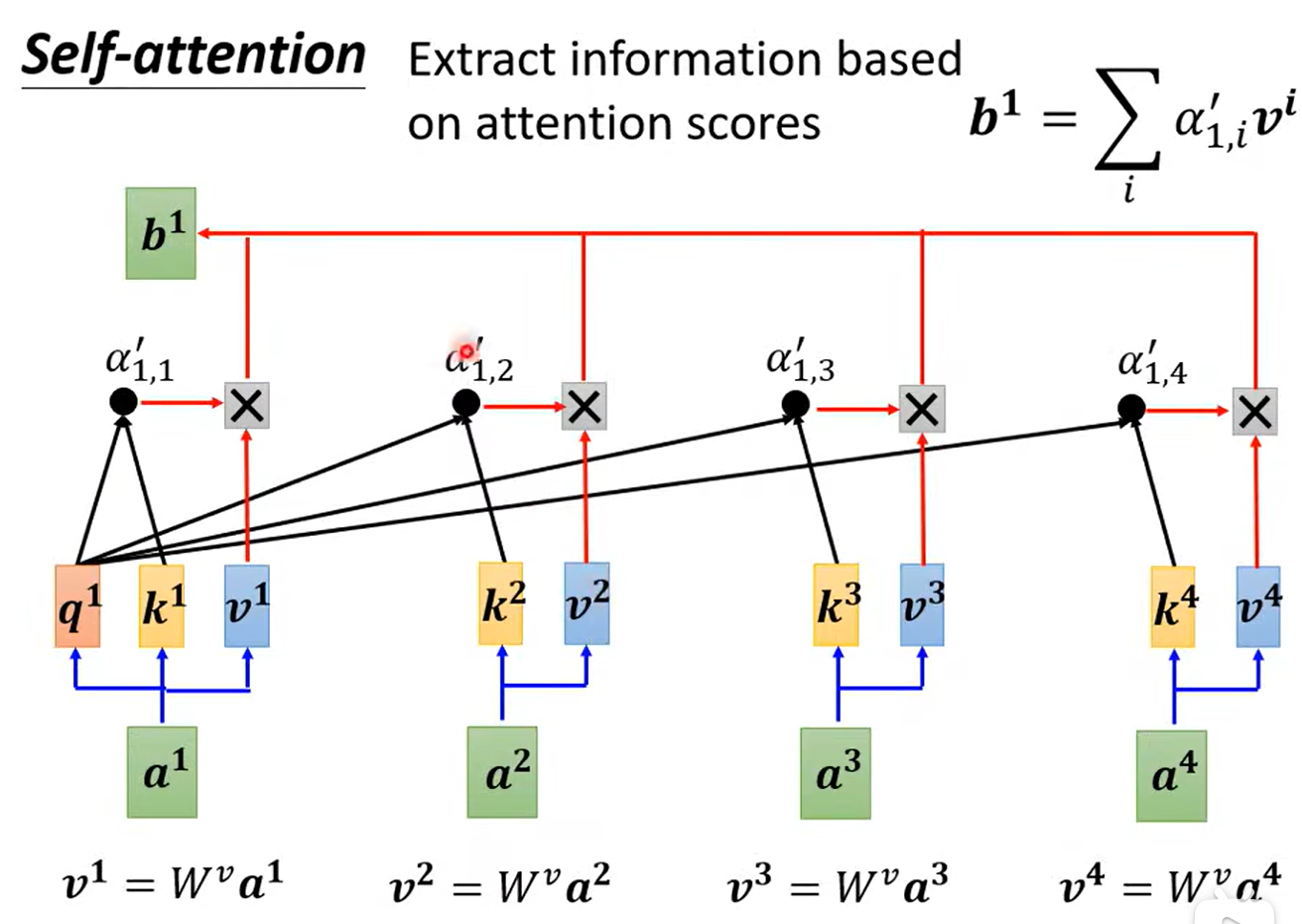
1.3 抽取重要资讯
依据注意力分数进行抽取。
将词向量乘以v值矩阵。
再乘以注意力分数。
再加起来。
例如,a1和a2的关系近,那么b1就会接近v2
以上计算可以化简。
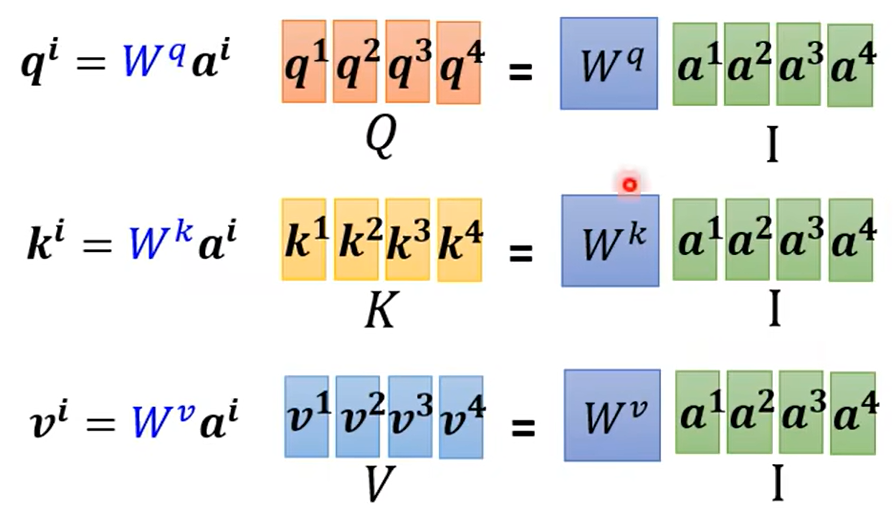
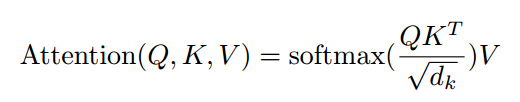
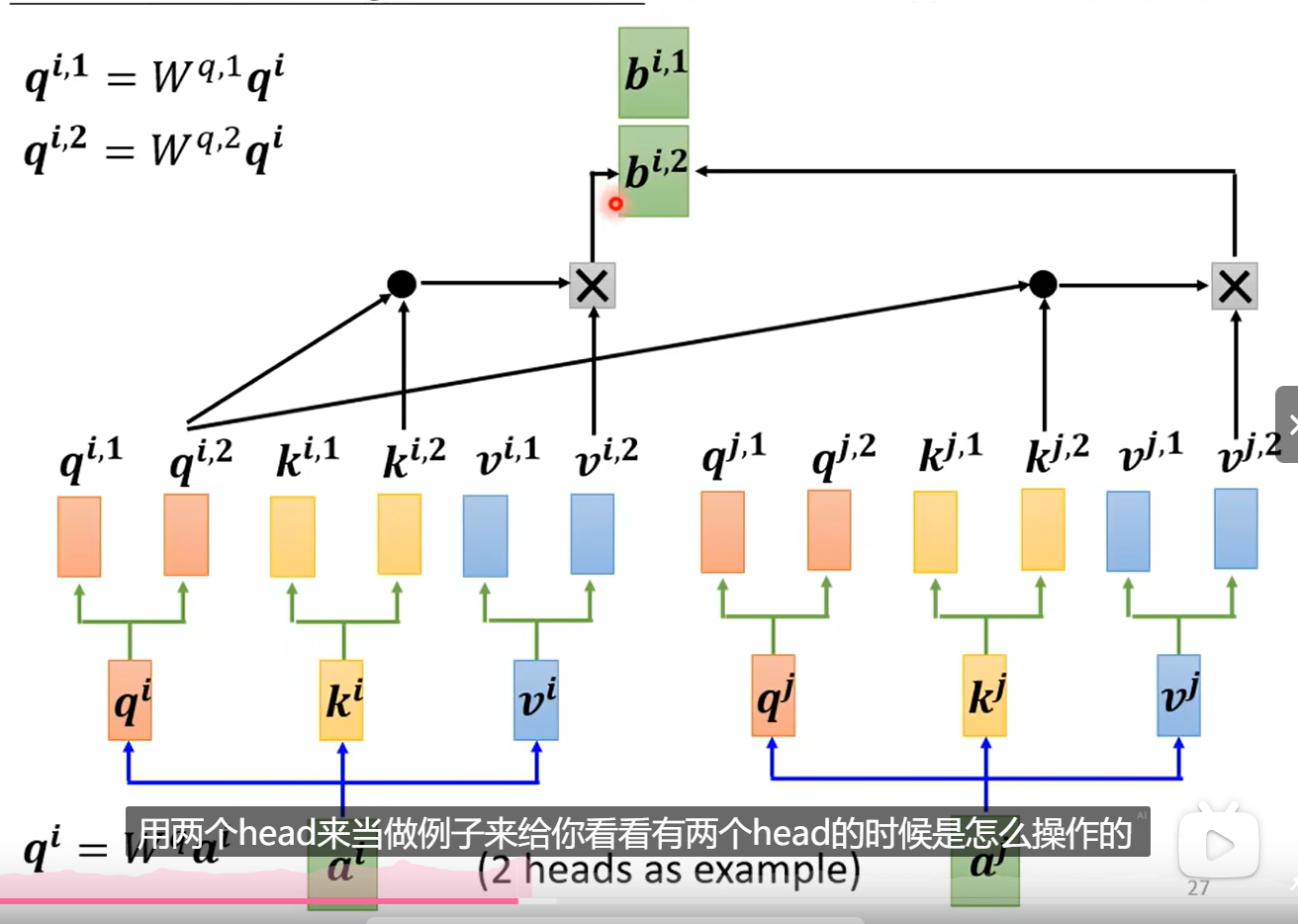
四、多头自注意力机制
将q,k,v进行分解。
从而得出不同的相关性。

五、位置编码
我们发现计算完相关度之后,其实每一个向量的位置没有被维护。
这个位置资讯没有被维护。
所以我们提出来位置编码。