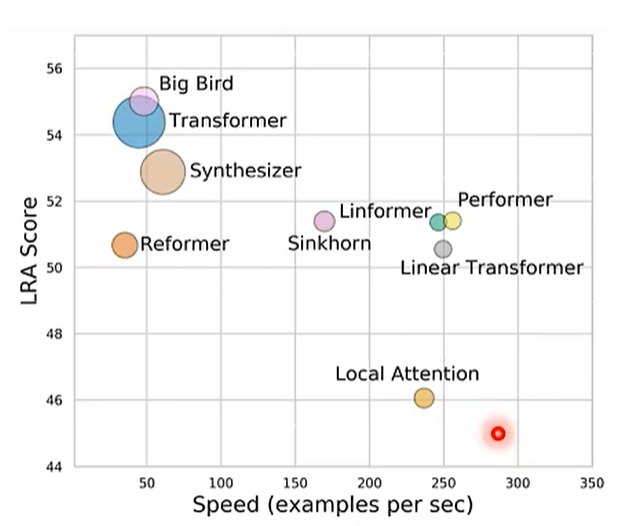
一、怎么使得Self-Attention有效
输入长度 N。
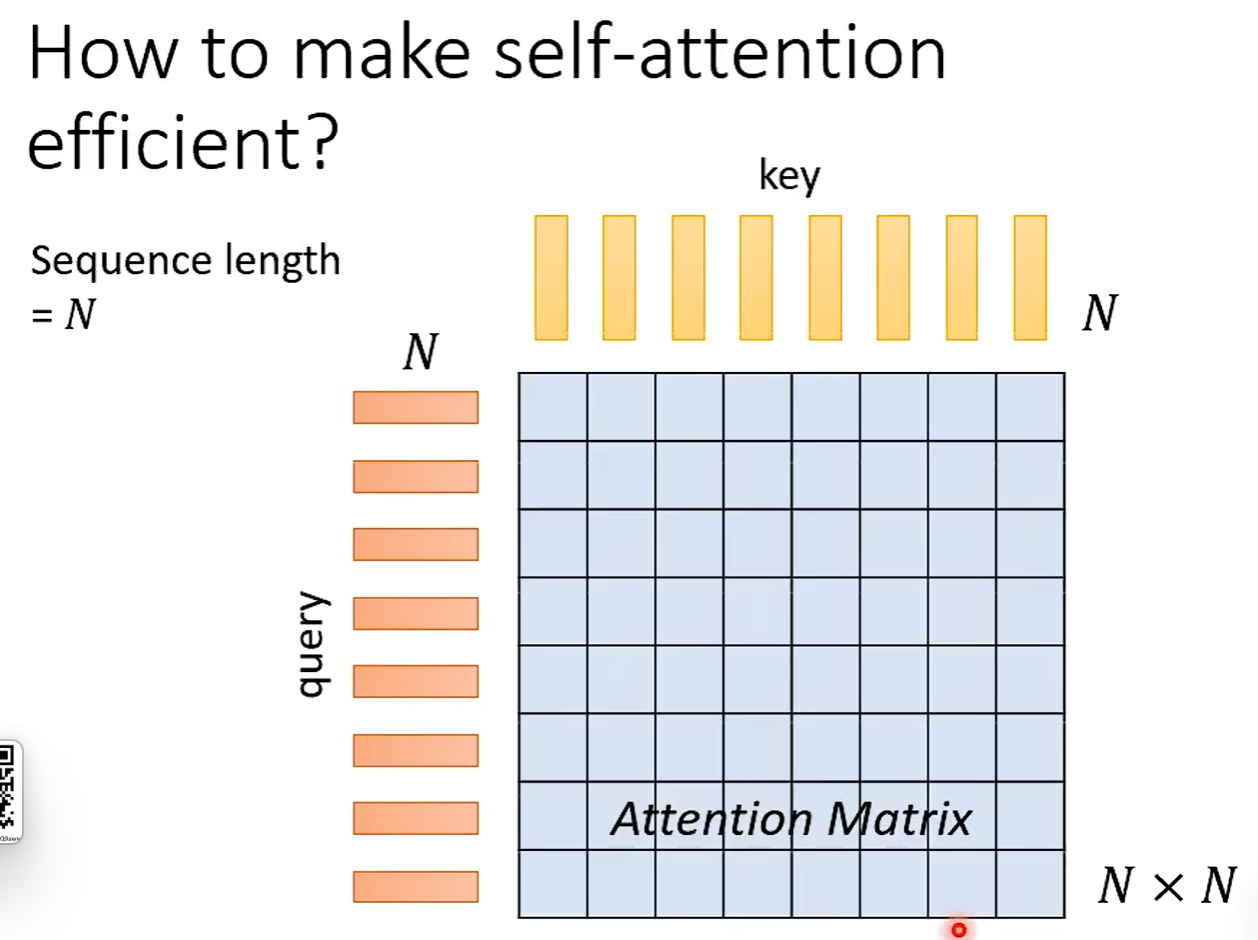
问题就在于 N * N 的计算量过于巨大。
思考:也许不需要计算全部的 N * N 矩阵。
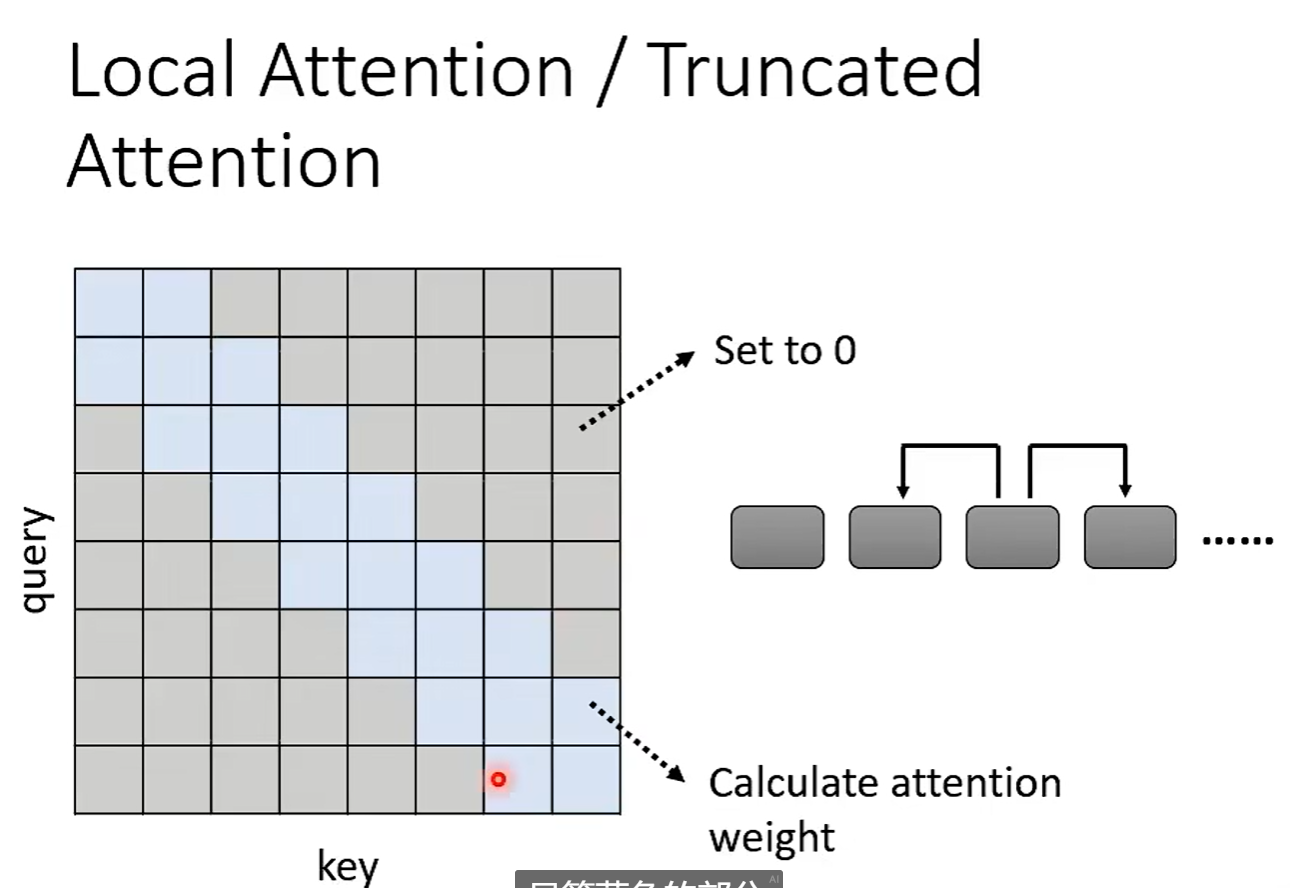
例如:局部Attention。但是类似于CNN。
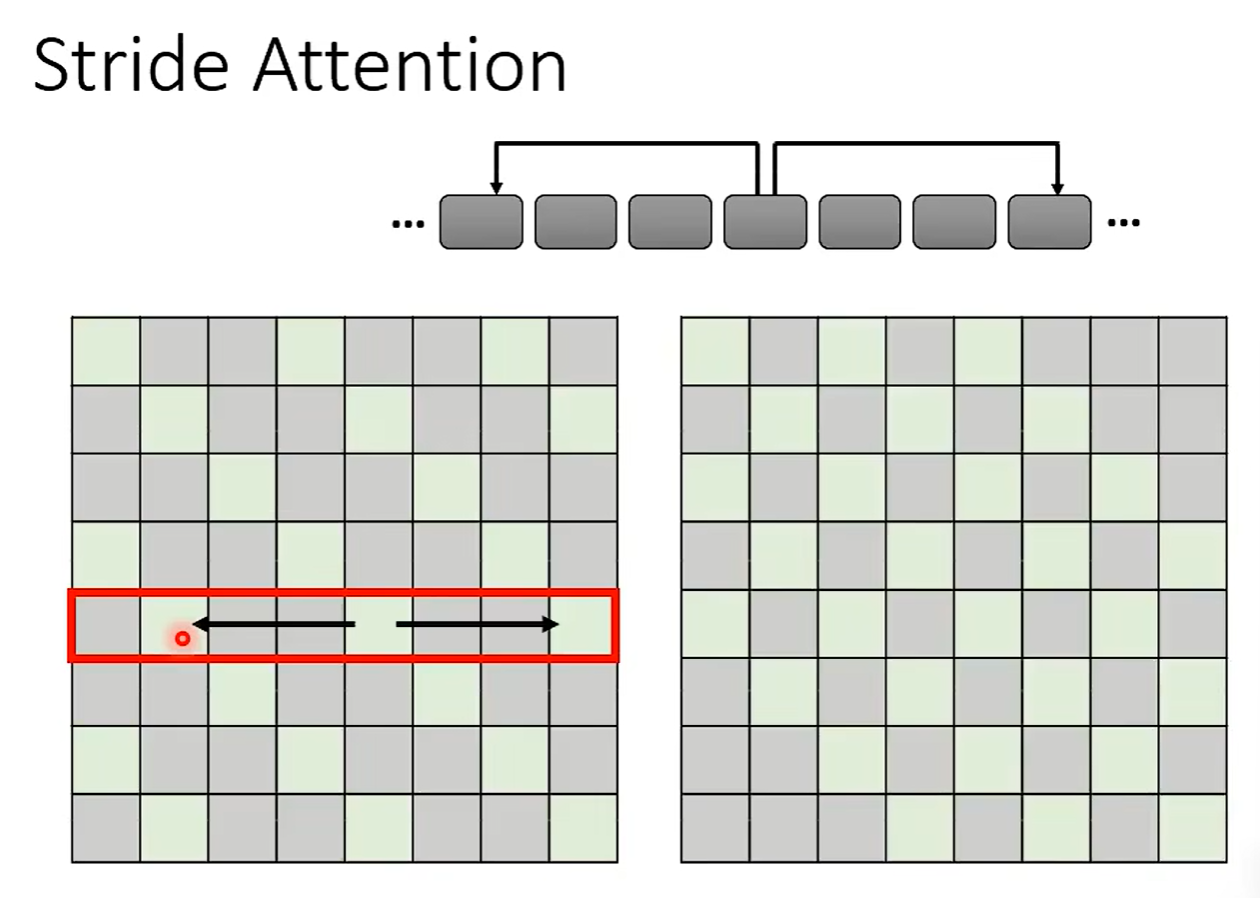
Stride Attention
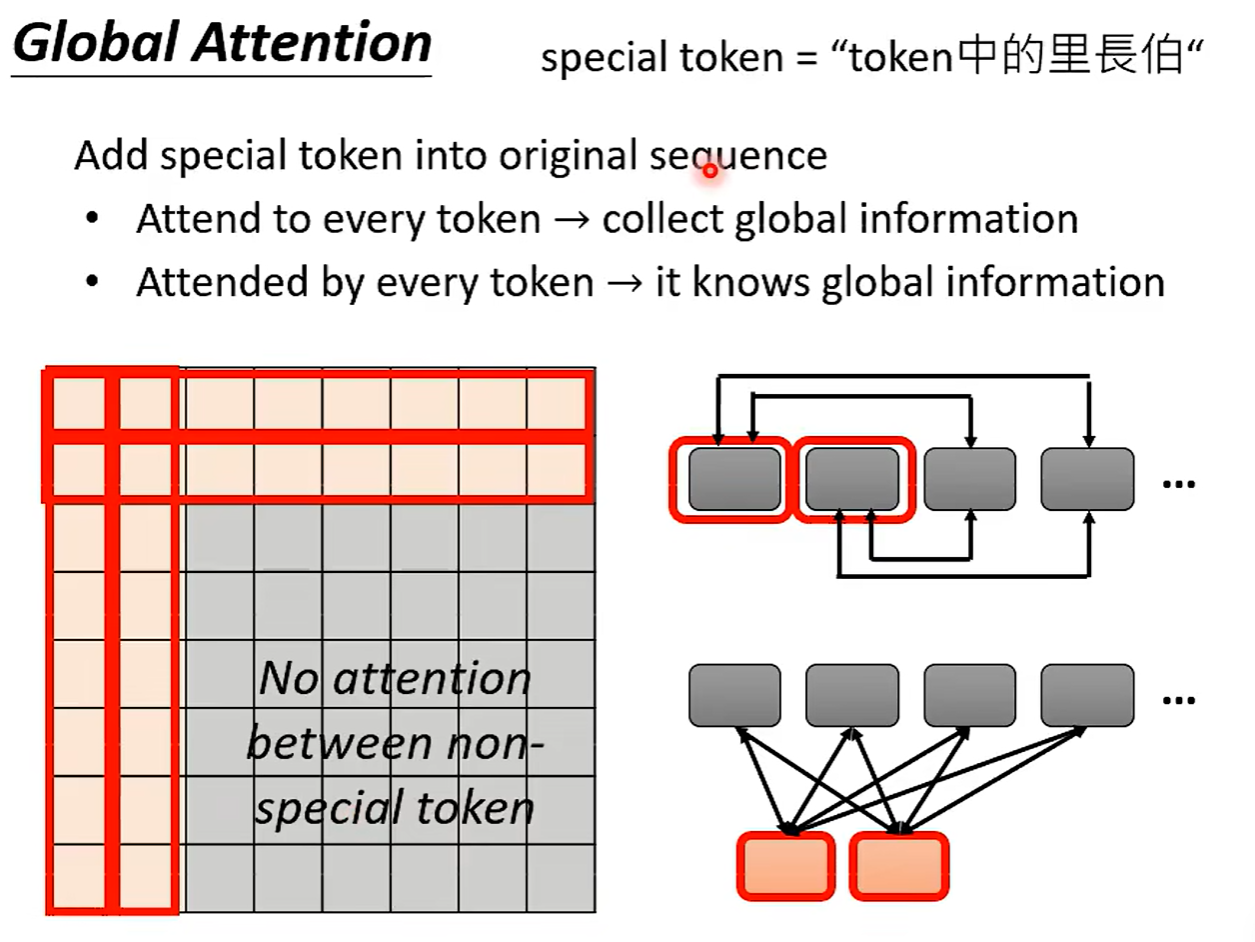
全局注意:
添加一个token,了解全局资讯。
各部分之间通过token相互了解。
在多头注意力的各个头中分别使用不同的处理。
以上都是人工设计的Attention。
但是我们是否能够找到数据驱动的自己寻找保留哪些Attention。
通过基于相似度的 Clustering 聚类实现。
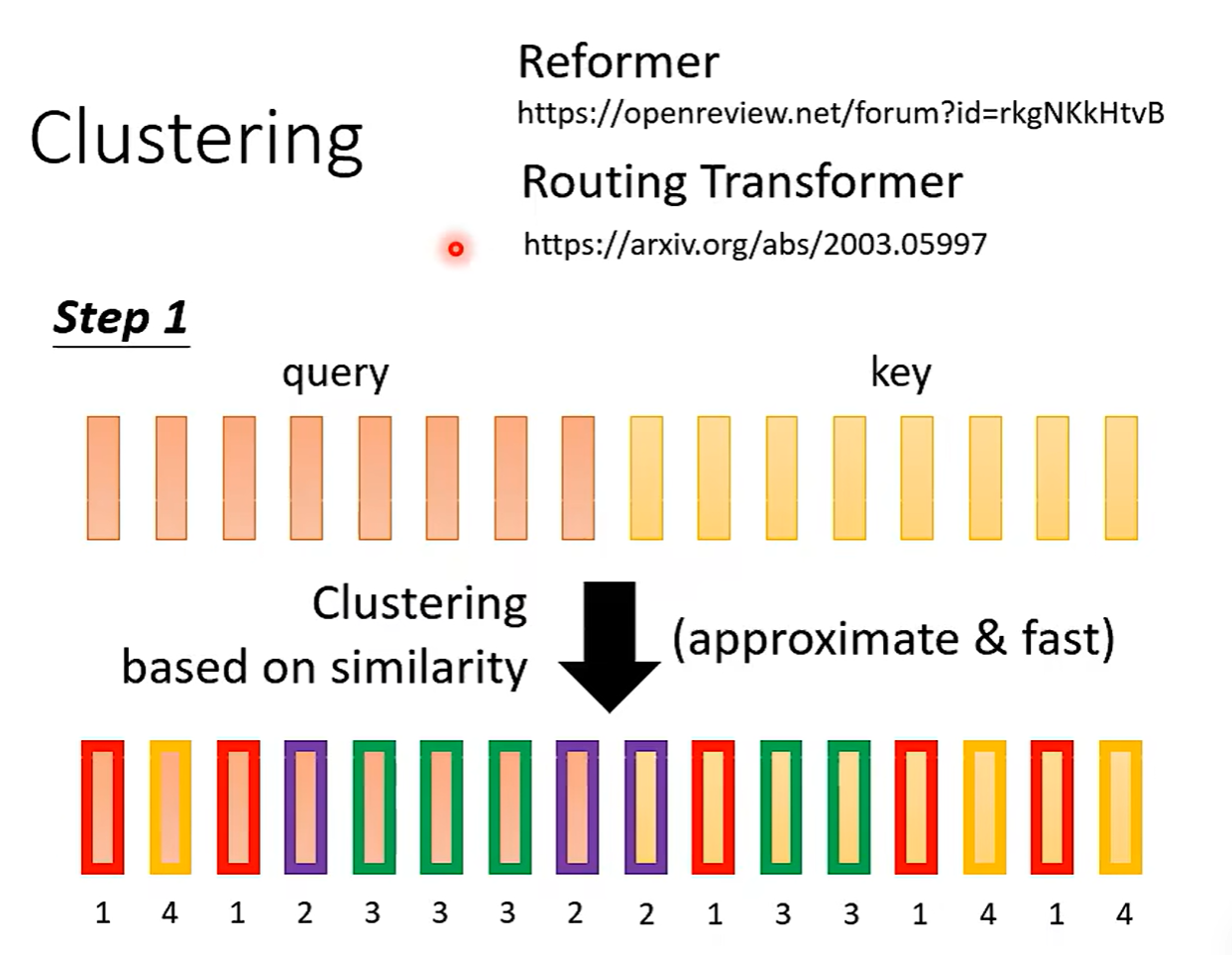
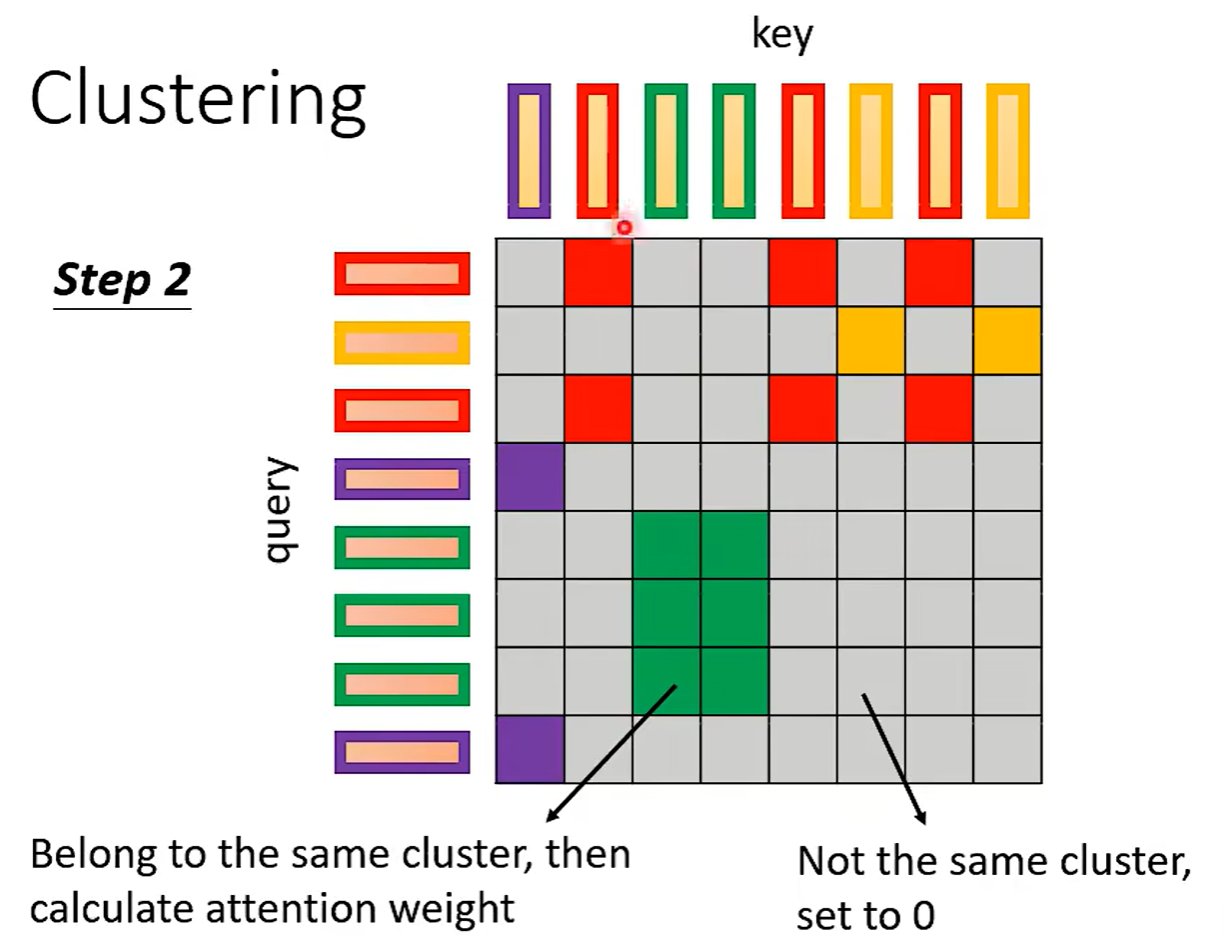
只有相像的才计算Attention。
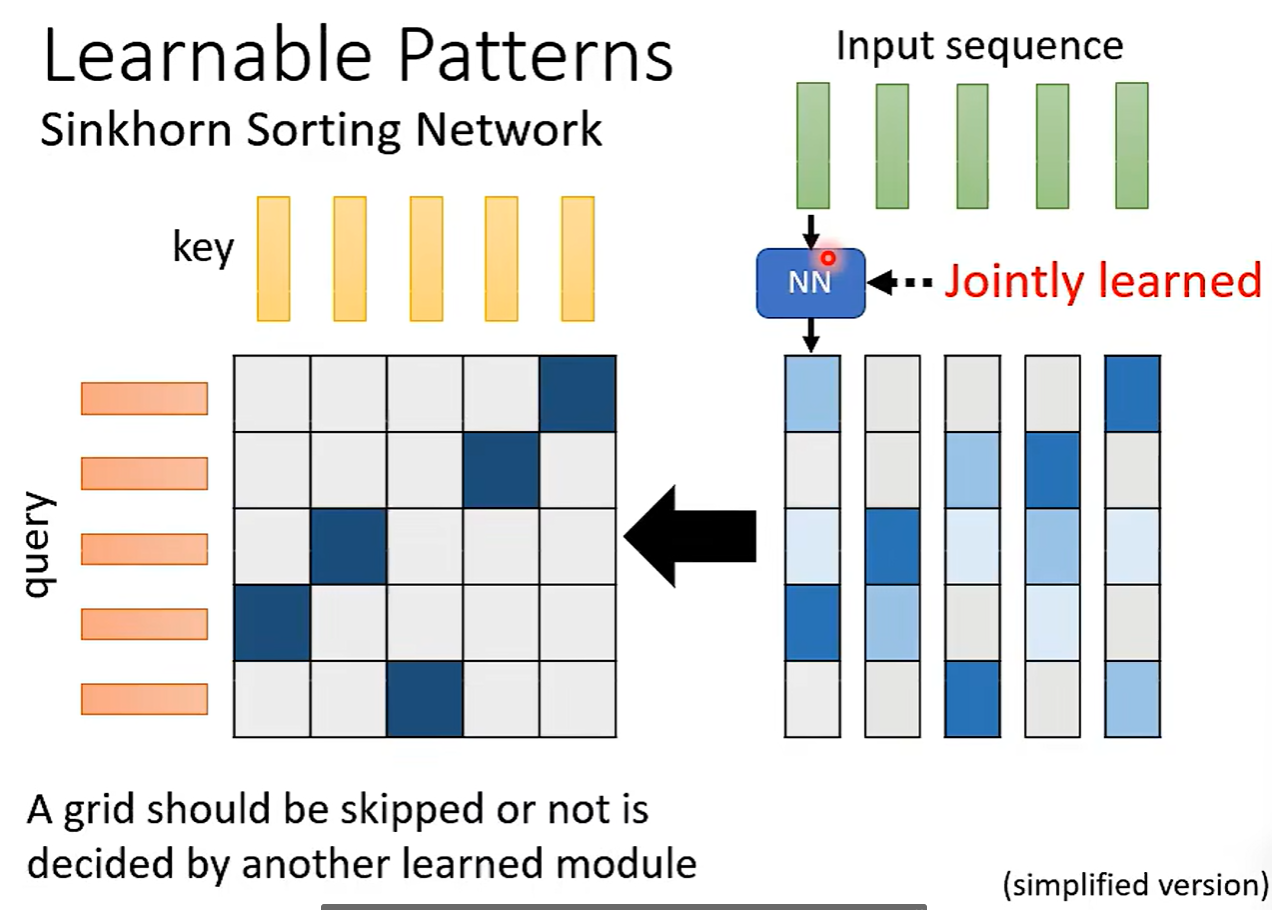
可学习模式:
用另外一个Net学习Attention。
挑选代表,压缩矩阵:
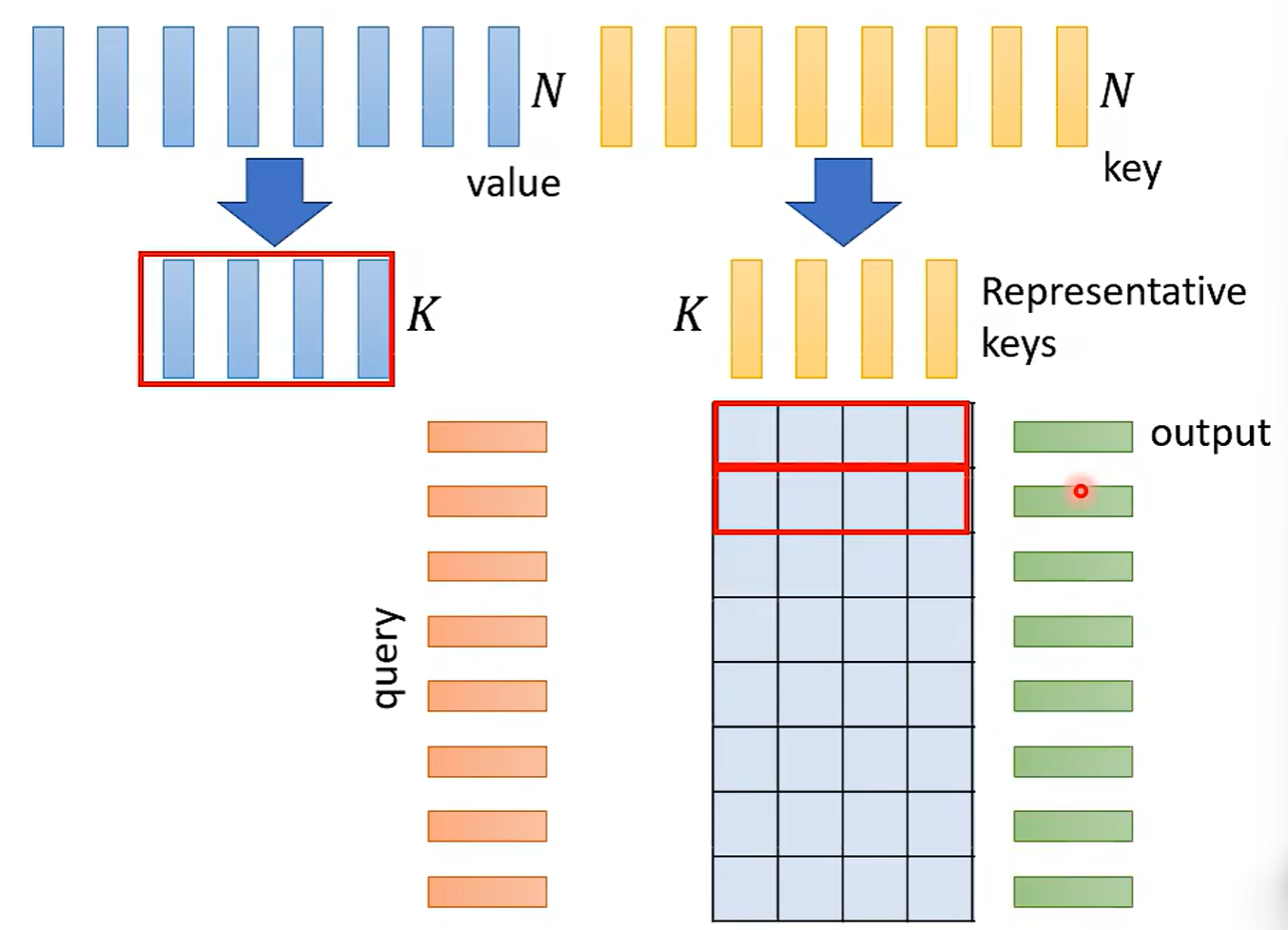
问:为什么不挑选q?
输入和输出的长度不同了。
挑选:CNN
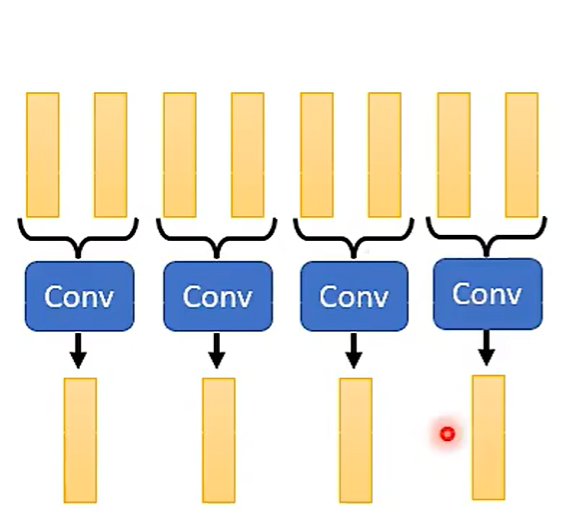
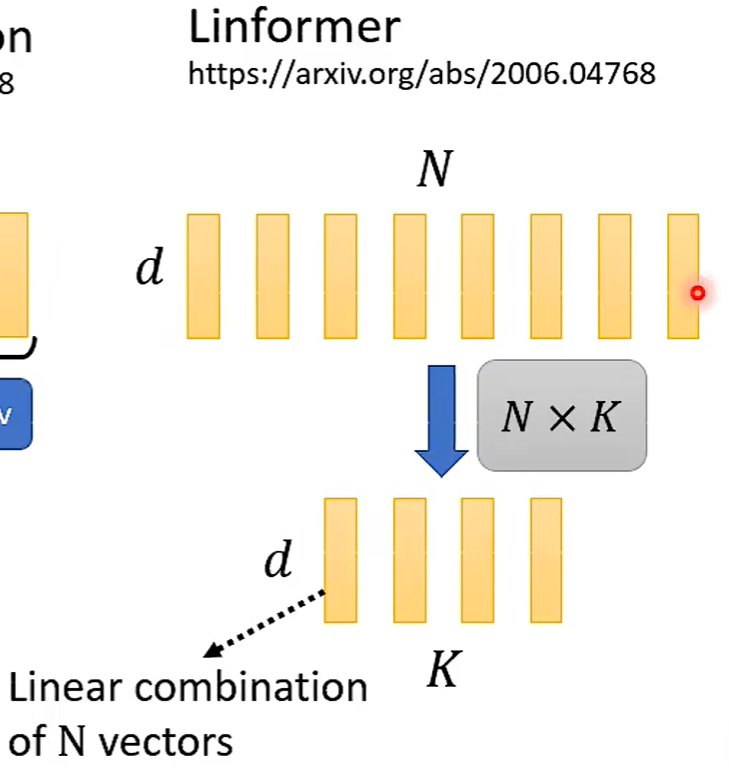
降维:
改变矩阵的相乘顺序,可以减少计算量。
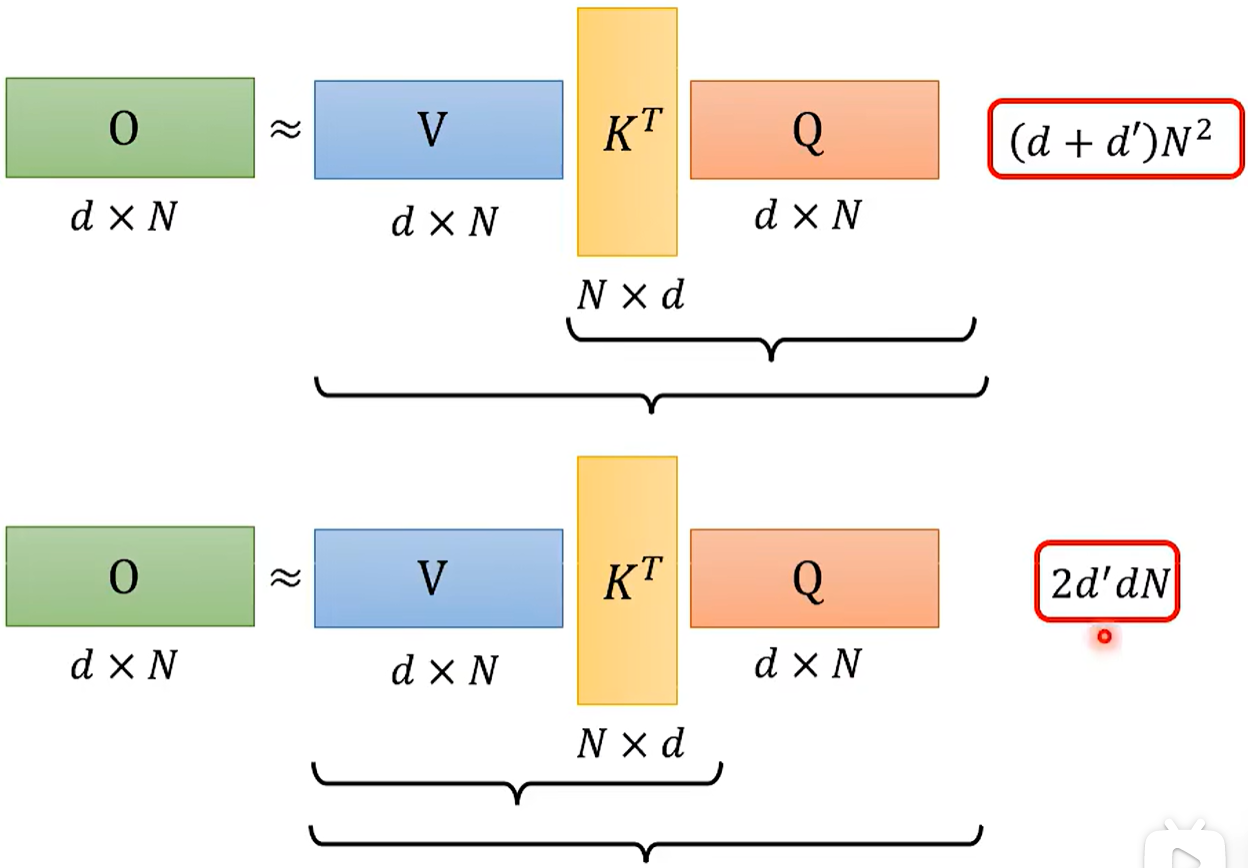
当然这是我们把Softmax拿走之后的结果。
我们再把Softmax放回来。
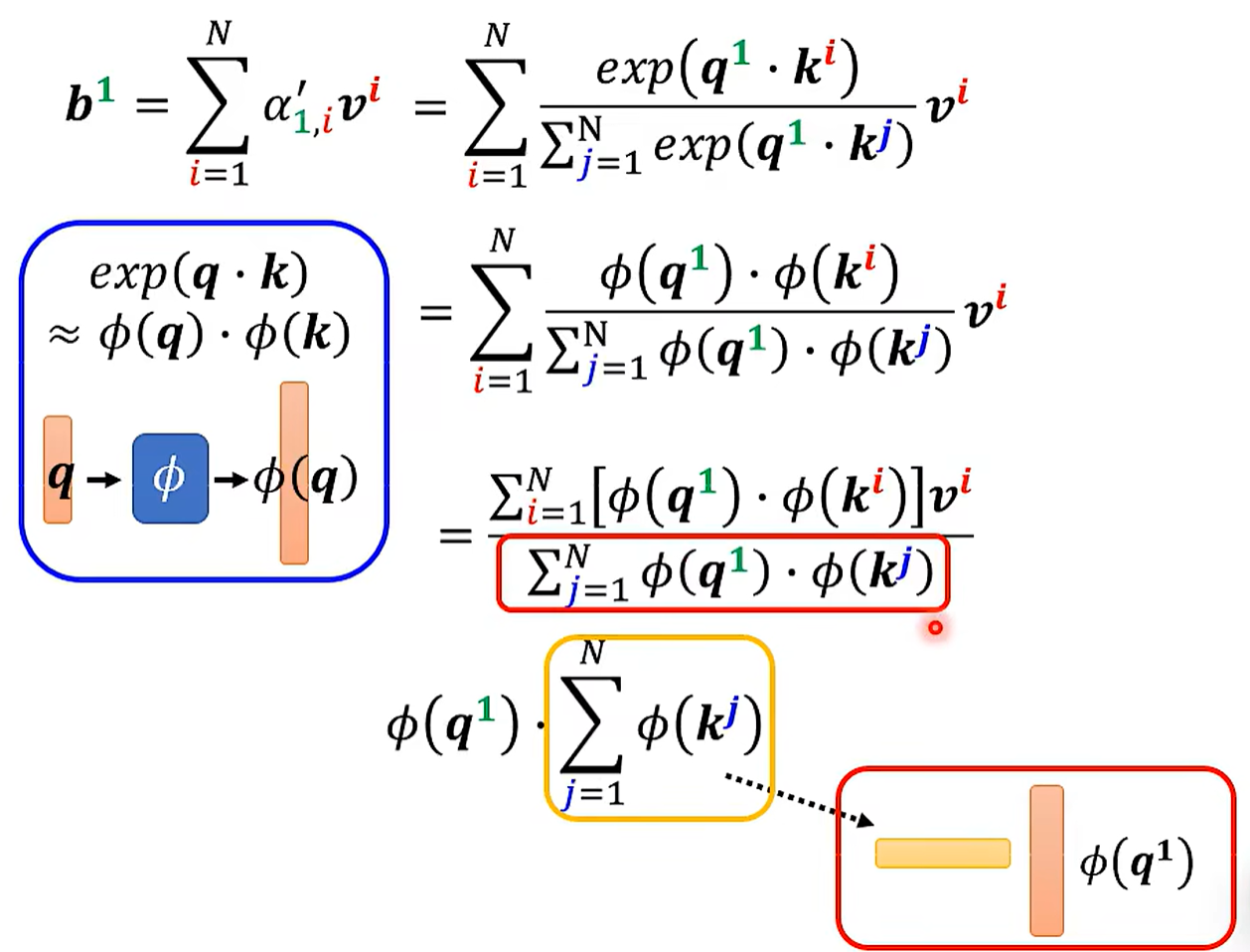
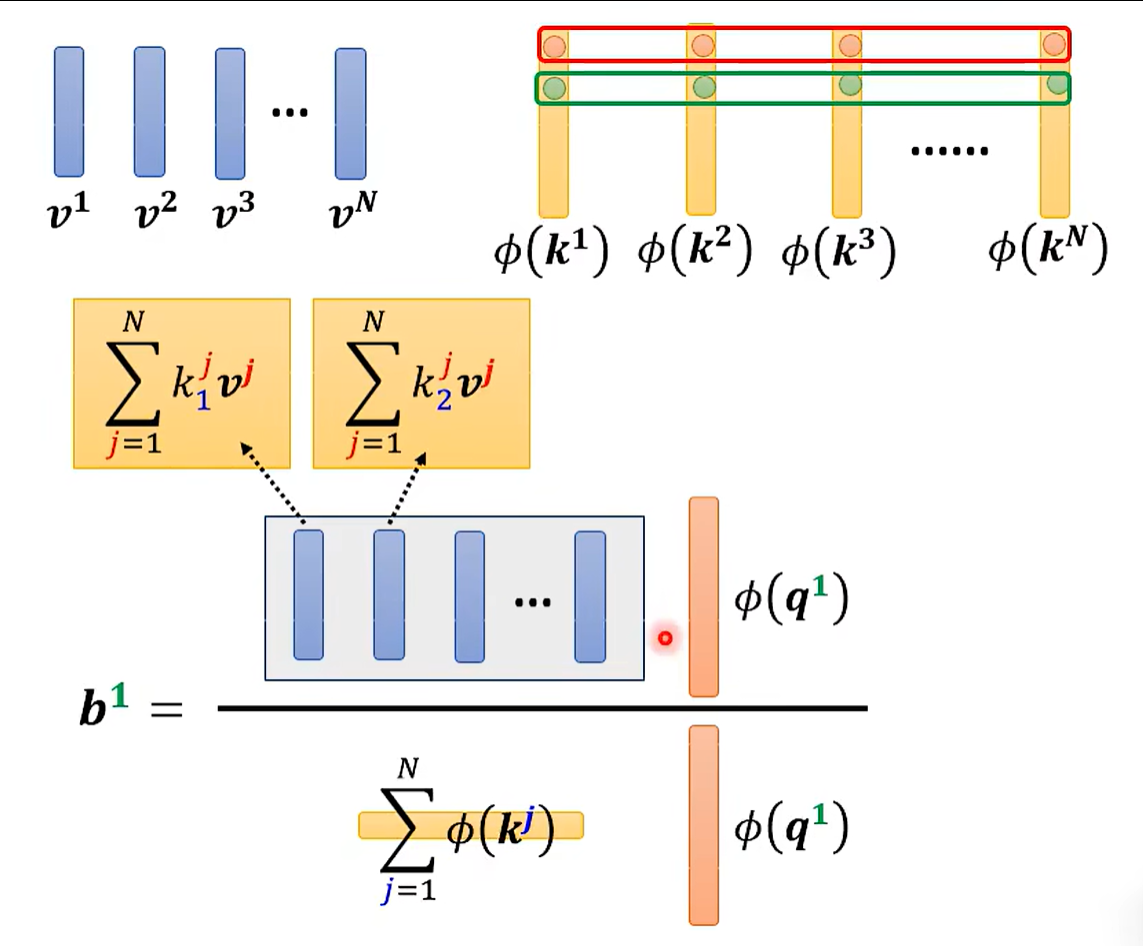
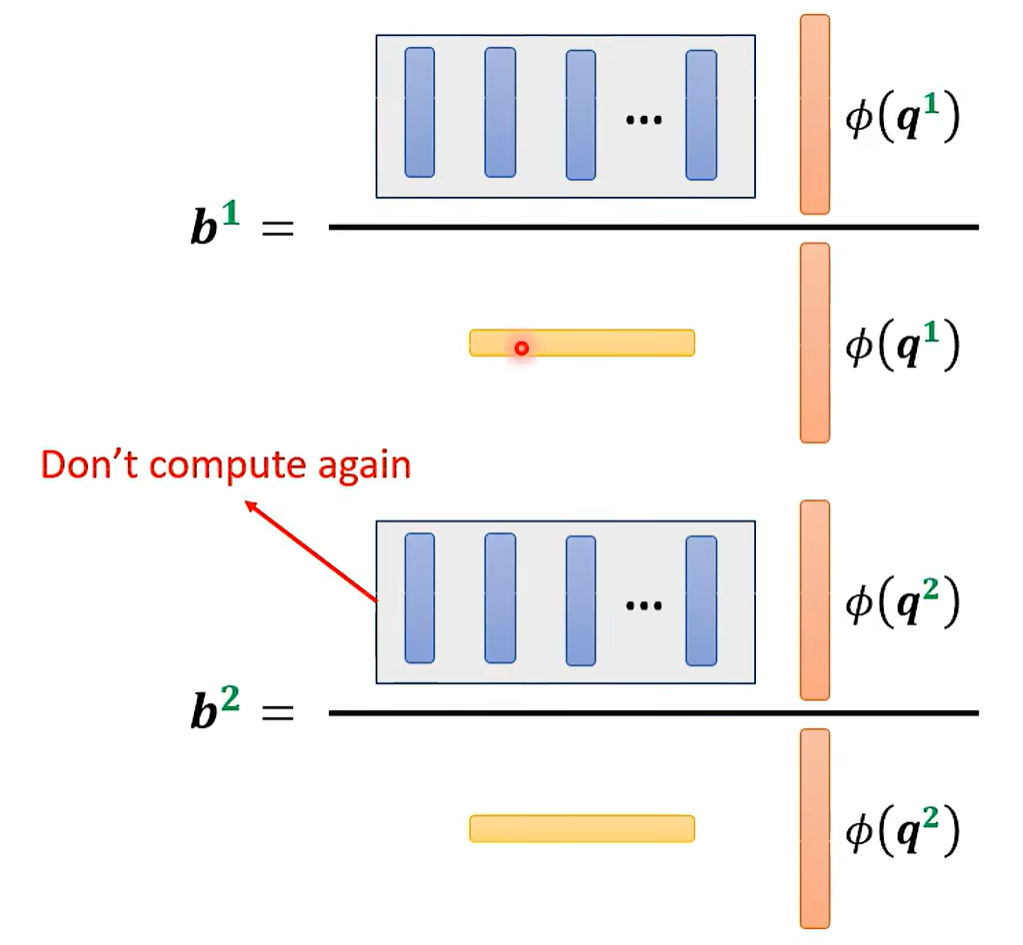
可重复利用。运算量少。
先操作k和v。
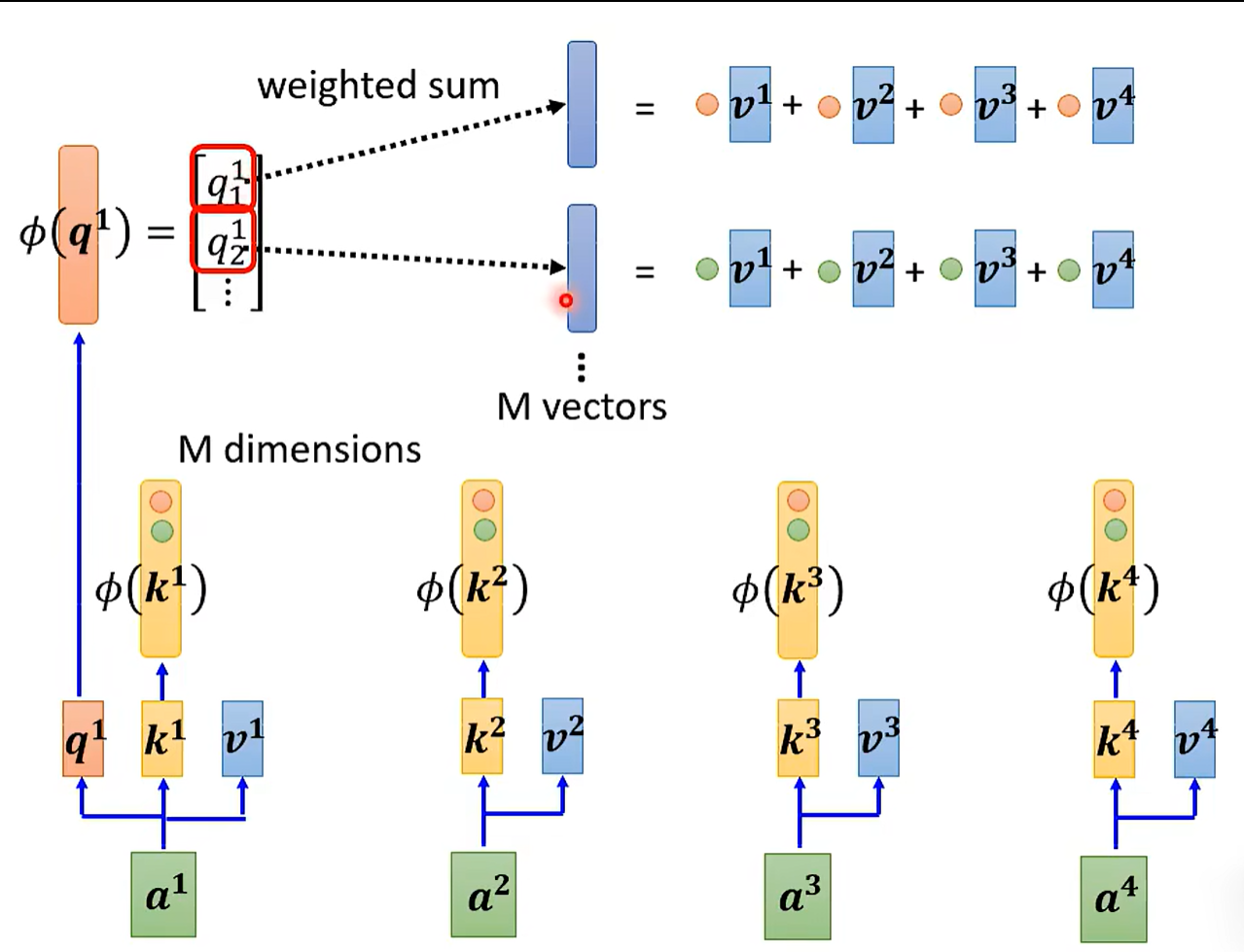
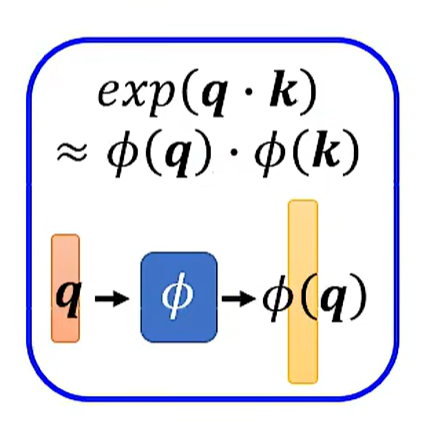


Attention也可以被学习。