本篇说明
本篇
TrialBench: Multi-Modal AI-Ready Datasets for Clinical Trial Prediction 是由 香港科技大学(广州)陈晋泰助理教授联合南京大学符天凡副教授、IQVIA 、哈佛医学院等团队合作 发表在《Nature Scientific Data》上的一篇文章。该团队构建了 首个面向人工智能的多模态临床试验预测平台,整合临床试验数据,搭建了一个开放、可复用的 基准测试。
相关资料
 Trialbench - Research Project
Trialbench - Research Project ML2ClinicalTrials/Trialbench at main · ML2Health/ML2ClinicalTrials
ML2ClinicalTrials/Trialbench at main · ML2Health/ML2ClinicalTrials一、背景与现状
1.1 临床试验
- 临床试验过程 是开发新疗法的关键步骤,是科学发现与现实医疗应用之间的桥梁。临床试验旨在系统评估这些治疗方法对人体的 安全性、有效性、剂量及整体影响。
- 一项临床试验的基本步骤包括:(1)规划和设计,研究人员定义研究目标、资格标准并确定治疗方案;(2)招募和筛查,即已登记符合条件的参与者并收集基线健康数据;(3)干预和监测,参与者接受治疗或安慰剂,并密切监测其健康结局;(4)数据分析,分析结果以确定治疗的安全性和有效性;(5)结论,报告发现,若成功,提交监管审批。
- 临床试验通常包括 四个阶段:(1)第一期,从小规模研究,评估安全性和剂量(20-80名健康志愿者);(2)第二期,扩展到评估更大人群的疗效和副作用(100-300名患者);(3)第三期,继续扩展到评估更大人群的疗效和副作用(300-3000名患者),通过第三期后获得 FDA批准;(4)进入上市后进行监测(服务几千到几万的病人)。
1.2 问题与现状
从上边的描述中可以看出:临床试验耗时长、劳动密集和成本高,且临床试验本身就存在风险。而 人工智能 尤其适合准确估计以降低风险,因为 AI 擅长识别那些对人类而言未知的模式。
然而识别关键临床试验挑战并有效利用这些数据中的复杂变量,需要深厚的医学知识与人工智能专业知识的结合。本文作者将整合 
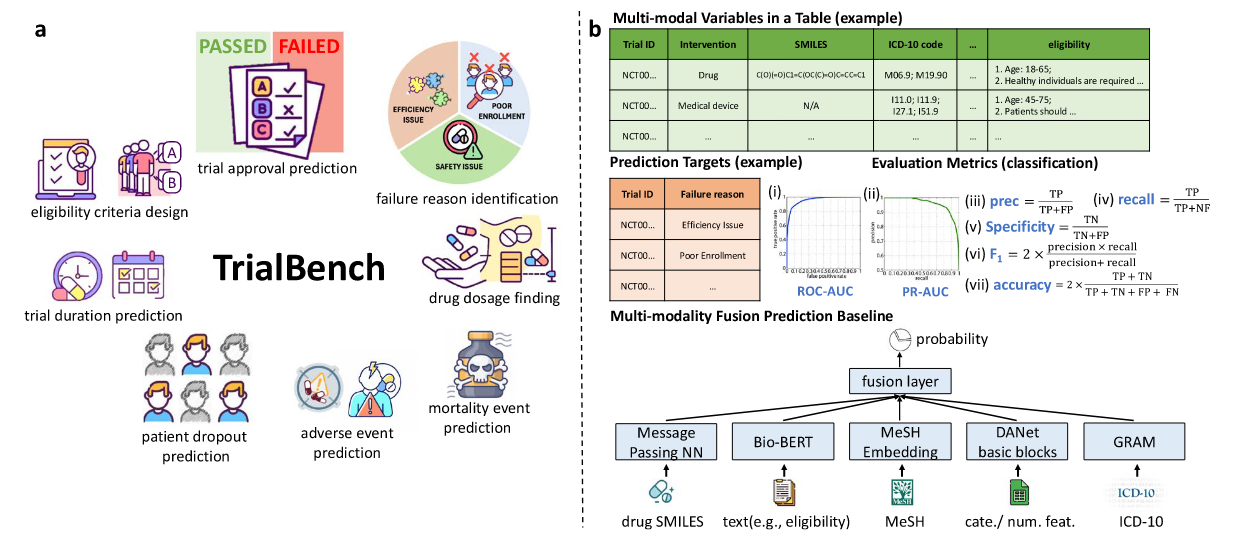
- 8 个关键临床试验挑战,包含临床试验时长预测、患者退出率预测、严重不良反应事件预测、死亡事件预测、实验获批结果预测、实验失败原因预测、资格标准设计、药物剂量发现;
- 5 个数据模态,包括 SMILES 字符串、文本描述、医学主题词(MeSH)、疾病 ICD-10 代码及其他类别或数字特征整合为最多五个不同的模态特征,利用消息传递神经网络(MPNN)、Bio-BERT、MeSH 嵌入层、基于图的注意力模型(GRAM)和 DANet 基本模块分别处理每种模态;
- 23 个数据集;
二、数据集构建
2.1 AI 可解决的临床实验任务定义
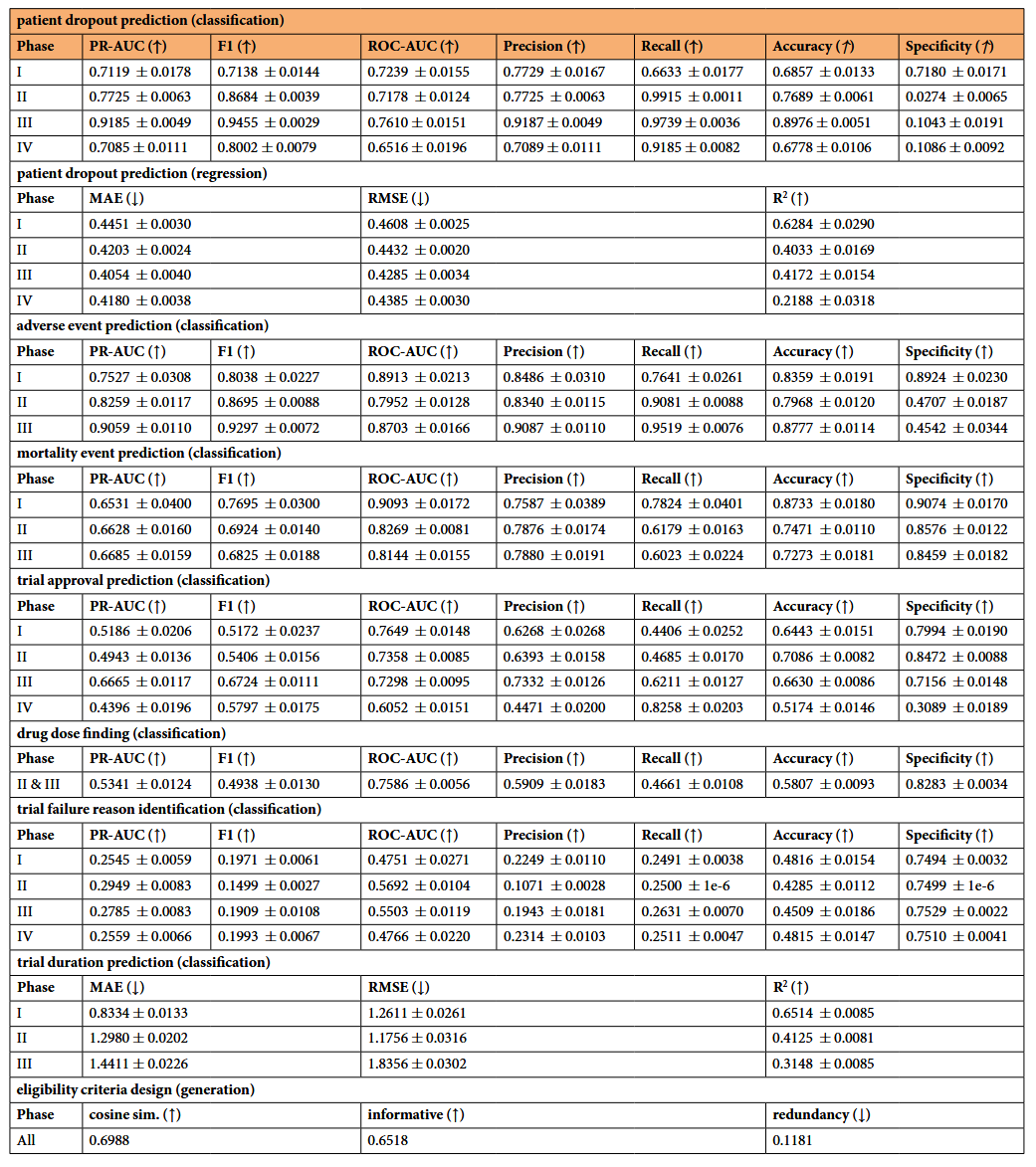
这部分,作者梳理了本文中定义的 8 项临床试验任务,包括任务背景、学习任务的形式、数据集的构建、输入输出等。详细信息见下表:
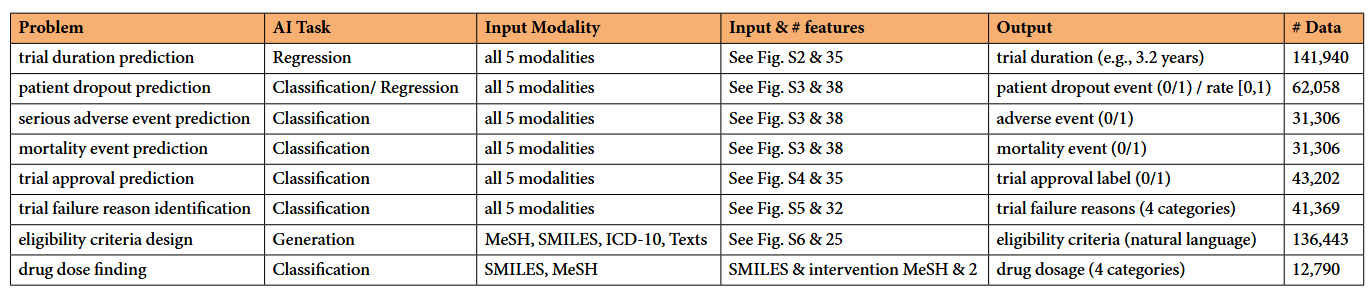
2.1.1 临床试验时间预测
- 背景:临床试验的持续时间定义为从试验开始日期到结束日期的年数,表示一个连续的数值。
- 定义:根据多模式试验特征(如资格标准、目标疾病等)预测试验时长(从第一名参与者入组到研究结束的时间跨度),被定义为 回归 任务。
2.1.2 患者退出预测
- 背景:以往研究表明,大约30%的参与者最终退出临床试验,这可能削弱试验结果的有效性,并导致成本上升和时间延长。
- 定义:基于多模式特征(如资格标准、目标疾病等)预测临床试验中患者退出的发生率(二元分类)和回归率,被定义为一个双目标学习任务,包括一个用于退出发生的分类子任务和一个用于估计退出率的回归子任务。
2.1.3 不良事件预测
- 背景:不良事件预测在临床试验中至关重要,因为它直接影响试验的安全性、有效性和整体成功率。任何临床试验的首要关注点是参与者的安全。
- 定义:预测基于多模式临床试验特征(如药物分子、目标疾病、资格标准等)的不良事件发生情况,被定义为二元分类问题。
2.1.4 死亡时间预测
- 背景:临床试验中的死亡事件指的是参与者在研究期间的死亡。当严重不良事件超过关键阈值时,不安全的治疗或严重疾病可能导致死亡。意外死亡可能引发伦理问题,并需要彻底的安全重新评估。
- 定义:根据多模态特征(包括药物分子、目标疾病、资格标准等)预测临床试验中的死亡率发生情况。它被表述为二元分类问题。
2.1.5 试验批准预测
- 背景:临床试验批准指的是药物是否能够通过临床试验的某个阶段,这是临床试验中最重要的结果。
- 定义:根据药物分子、疾病代码和资格标准等多模态试验特征,预测试验获批的概率。它被表述为二元分类问题。
2.1.6 试验失败原因识别
- 背景:临床试验通常因以下几个原因而失败:(1)商业决策(例如,资金不足、公司战略转变、管道重组、药物战略转变);预测业务决策具有挑战性,因此我们不将这些试验纳入数据集;(2)招生不良。招募人数不足会削弱研究的统计效力,使得难以发现药物的显著效果。此外,报名不足可能导致试验时间表延误和成本增加,因为需要更多资源来招募更多参与者。(3)安全。意外的不良反应或副作用可能发生,对参与者健康构成重大风险。这可能导致审判被中止或终止。(4)疗效(有效性)。在试验中,我们预计所测药物在治愈目标疾病方面将优于标准治疗。
- 定义:被定义为一个四分类问题。
2.1.7 资格标准设计
- 背景:要实现统计学上显著的结果,临床试验必须达到其目标样本量。患者数量不足可能导致研究样本不足,无法证明治疗效果或遗漏重要安全信息。资格标准对于患者招募至关重要。他们用非结构化的自然语言描述患者招募需求。资格标准包括多个纳入和排除标准,明确招募患者时希望和不希望的条件。每个独立的标准通常是自然语言句子。
- 定义:根据一系列临床试验特征(如目标疾病、阶段、药物分子等)设计资格标准。是一个生成式任务。
2.1.8 药物剂量检测
- 背景:临床试验的主要目标之一是确定药物剂量。确定药物的正确剂量对于确保其治疗特定疾病效果至关重要。在药物开发的早期阶段,预测最佳剂量对于设计临床试验至关重要。
- 定义:根据药物分子结构和目标疾病预测药物剂量,该问题被表述为序数分类问题。
2.2 原始临床试验数据
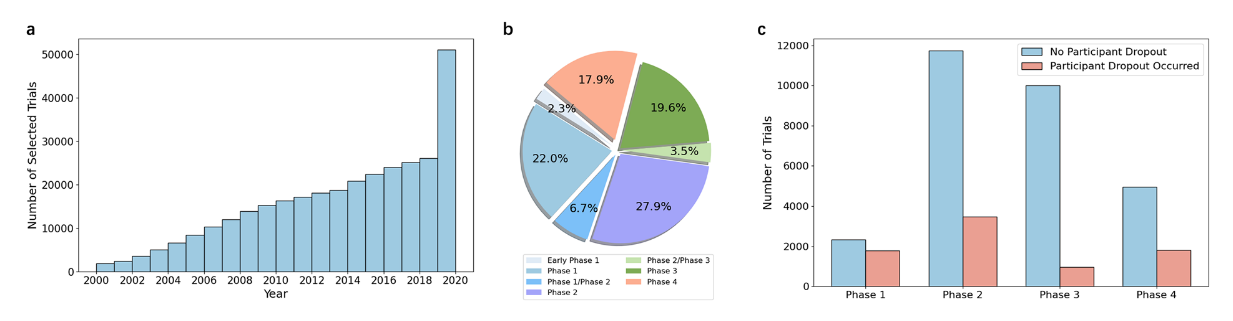
在 ClinicalTrials 网站上能够查看到可以被公开访问的临床试验数据。该数据库由美国国家医学图书馆支持,涵盖超过42万条临床试验记录,覆盖美国所有50个州和全球221个国家。一张真实的试验记录单如下图(真实的数据是按照 xml 格式组织,包括数百种模态特征):

- 记录数量随时间变化迅速增长。
- 大多数试验停留在二期。
- 不同阶段患者退出率不同。
2.3 数据采集
作者基于多个公开数据源创建数据集基准,包括 ClinicalTrials.gov、DrugBank、TrialTrove、ICD-10编码系统。构建流程如下:
- 从 ClinicalTrials.gov 中提取治疗名称(例如药物名称),并将其与其分子结构(SMILES字符串和分子图结构)关联,使用DrugBank数据库收集AI准备的输入和输出信息;
- 从 ClinicalTrials.gov 中提取疾病数据,并将其与ICD-10(国际疾病分类第十版)代码和疾病描述链接,然后通过 hcup-us.ahrq.gov/toolssoftware/ccs10/ccs10.jsp 转为CCS代码;
- 进一步提取和分类TrialTrove中的试验结果,并将其与NCTID关联起来。
2.4 数据集筛选与特征构建
作者基于临床试验知识,手动为各种任务选择合适的功能。此外,还剔除了不同试验中取值相同或全部为零的特征。对于不同的任务又有额外的筛选标准。
- 试验时长预测:我们仅考虑可用开始和完成日期的试验。我们只考虑具有现实完成日期的审判,剔除仅提供预期完成日期的案件。我们发现持续时间超过10年的试验属于异常值,因此我们移除了这些试验以促进回归分析。
- 患者退出预测:结果可在 ClinicalTrials.gov 年提供,并报告退出人数及注册患者总数。
- 不良事件预测:结果可在 ClinicalTrials.gov 年公布,严重不良事件会被报告。
- 死亡事件预测:结果可在 ClinicalTrials.gov 获取,死亡事件会被报告。
- 试验批准预测:结果和试验结局信息可在TrialTrove23的官方 ClinicalTrials.gov 或已发布子集获取。
- 试验失败原因识别:我们纳入那些结果和结局信息在 ClinicalTrials.gov 上可查到的试验,可分为上述四类(三种失败原因或成功)。
- 资格标准设计:为确保所选资格标准的质量,我们仅纳入已完成、表明成功招募患者且标准设计合理的试验,其他则剔除。
- 药物剂量检测:我们纳入药物剂量信息可在 ClinicalTrials.gov 获取的试验。仅包含二期临床试验,因为二期是验证药物剂量安全性和有效性的阶段。由于药物剂量查找任务主要涉及药物信息,我们仅保留了小分子药物相关数据(如MeSH),并从DrugBank获取了SMILES数据。我们鼓励AI专家利用PubMed和DrugBank等外部资源进行高级AI模型开发。
2.5 数据标签的构建
数据标签是整理数据集时的一个基本步骤。所有数据集的标签都可以从各种数据源推断出来。对于某些任务,如药物剂量检测、试验批准预测和试验失败原因识别,作者使用外部工具如GPT从原始文本获取标签。
- 试验时长预测:临床试验的持续时间指试验持续的年限,即开始日期与完成日期之间的差值。这是一个连续的数值。部分试验的开始和完成日期可在 ClinicalTrials.gov 年提供。我们可以利用这些信息计算审判时间。
- 患者辍学预测:一些临床试验 ClinicalTrials.gov 会显示辍学患者数量和注册患者数量。我们通过将辍学患者人数除以注册患者数来计算患者辍学率。由此产生的辍学率是一个百分比。
- 不良事件预测:ClinicalTrials.gov 呈现部分试验结果。部分试验报告了不良事件。
- 死亡事件预测:临床试验结果可能包含死亡事件 ClinicalTrials.gov我们将死亡事件二元化为预测目标,指示是否发生死亡事件,并剔除所有缺乏死亡事件信息的其他试验。
- 试验批准预测:注释来自两个来源。首先,HINT论文23,26–28构建了一个试验批准预测的基准数据集,批准标签来源于TrialTrove。此外,ClinicalTrials.gov 还在 XML 文件中的“为何停止”节点中,提供了某些试验终止原因,如招募不良或无效。我们将这些试验以及表示未批准的终止原因纳入数据集,作为阴性样本。
- 试验失败原因识别:对于部分终止试验,ClinicalTrials.gov 提供“为何停止”标签,使用自然语言描述失败原因。我们使用 OpenAI ChatGPT API(
https://openai.com/index/openai-api/)自动将失败原因分为四类,包括(1)注册不良;(2)药物安全问题;(3)治疗目标疾病的疗效不足;(4)其他因素(例如,资金不足、赞助商的战略决策)。由于最后一个失败原因((4)其他)通常不可预测,我们执行4类别分类((1)成功;(2)入学率低;(3)药物安全问题,(4)疗效不足)。其 GPT 提示词如下:
Prompt

- • 资格标准设计:对于某些试验,资格标准以文字形式组织,并可在 ClinicalTrials.gov 上查阅。我们以标记为“已完成”的试验的纳入/排除资格标准为事实。
- 药物剂量确定:二期临床试验的一个目标是确定药物剂量。ClinicalTrials.gov 用自然语言呈现了一些试验的药物剂量信息。我们使用 OpenAI ChatGPT API(
Prompt

2.6 数据划分
采用随机分区来进行数据集拆分。对于分类任务,采用分层抽样以保持训练集和测试集间的类别分布;回归任务采用随机拆分。默认的分配比例是80/20。
三、数据集概述
3.1 数据特征
- 国家临床试验编号(NCT ID):是临床试验的标识符。它由11个字符组成,以NCT开头,例如NCT02929095。NCT编号根据注册日期的时间顺序分配,从NCT00000000开始。
- 研究类型:临床试验可分为干预性和观察性。介入性临床试验涉及药物、医疗器械或手术作为治疗手段。相比之下,观察性试验不会将参与者分配到治疗或其他干预措施。相反,研究人员观察参与者或测量某些结果以确定临床结果。
- 研究阶段:第一阶段测试药物的毒性和副作用;第二阶段确定药物的疗效(即药物是否有效);第三阶段重点关注药物的有效性(即药物是否优于当前标准做法)。当试验通过第三阶段后,可以提交给FDA审批。在许多情况下,即使获批后,我们仍需进一步监测药物的有效性和安全性。有时会进行第四期临床试验以评估药物的有效性和安全性。表4展示了第一、二、三和四阶段之间的差异。
- 资格标准描述患者招募需求:采用非结构化自然语言。资格标准包括多个纳入和排除标准,明确招募患者时希望和不希望的条件。每个独立的标准通常是自然语言句子。
- 疾病(也称为疾病或适应症):描述了该药物旨在治疗的疾病。它是用无结构的自然语言表达的。例如,NCT00428389研究了在疑似阿尔茨海默病患者中从多奈哌齐尔切换到利瓦斯季明贴片的安全性,而阿尔茨海默病正是试验想要治疗的疾病。有时,单一试验可能针对多种疾病或有共病的患者。
- 疾病代码:该疾病通常用自然语言描述,难以揭示不同疾病之间的关系。为解决这一问题,我们将疾病名称映射到疾病代码,并利用疾病层级进行机器学习建模。例如,多个ICD-10代码对应阿尔茨海默病,包括“G30.0”(早发阿尔茨海默病)、“G30.1”(晚发阿尔茨海默病)、“G30.8”(其他阿尔茨海默病)和“G30.9”(阿尔茨海默病,未明确说明)。
- 临床试验的标题:通常使用无结构的自然语言。
- 临床试验的总结:同样采用非结构化自然语言,由2-5句话组成,描述所测试的治疗方法、治疗目标疾病以及临床试验的主要目标。
- 药物(也称为干预或治疗):在试验文件中,会显示药品名称。我们也知道药物的类别,即它属于小分子药物还是生物制剂。治疗通常涉及一种或多种药物分子。我们还可以将药物候选者映射到其分子结构,例如其SMILES字符串(简化分子输入行输入系统(SMILES)是一种以行符号形式描述化学物种结构的短ASCII字符串的规范)。
- 试验场地:一项试验通常在多个试验点进行,以便科学家能够招募足够的患者。科学家们还希望减少患者群体的偏见,增强其多样性,因此也考虑了试验地点的地理位置。
- 病人:试验主办方需根据试验地点的电子健康记录(EHR)招募符合条件的患者志愿者进行试验。招募患者的要求已在资格标准中明确。
- 电子健康记录(EHR):电子健康记录(EHR)是患者的纵向数字记录,包含患者的病史。电子健康记录(EHR)数据的不断增加和可获得性,激发了利用机器学习方法支持药物开发的兴趣。例如,已有机器学习方法(如33,34)被提出将患者电子健康记录数据与临床试验资格标准对应。电子健康记录数据包含N个不同患者的医疗记录。每位患者的病历是纵向数据。
- 开始日期:即为临床试验的注册日期。NCTID根据开始日期的顺序分配。
- 完成日期:指的是临床试验完成的日期。未完成的临床试验有预期的完成日期。
- 临床试验的赞助方:可以是制药公司或研究机构。
- 结果:通常,试验结果通常较为复杂,涉及大量统计和分析。在某些任务中,如临床试验结果预测,结果可以抽象为二元标签,例如测试药物是否通过了某个特定阶段。
- 失败的原因:临床试验因多种原因而面临高失败率,包括业务决策(如资金不足、公司战略转变)、招募不足、药物安全问题(如不良反应)以及疗效不足。
3.2 数据模态
- 分类特征:范畴特征通常描述一些定性属性。例如,主要有两种研究类型:干预性研究和观察性研究。干预类型可以是小分子药物、生物制剂或手术等。临床试验的赞助方可以是制药公司或研究机构,例如约翰斯·霍普金斯大学或辉瑞。
- 数值特征:数值特征,如招募患者的最低/最高年龄以及实际/预期招募患者的数量,也代表了定量数据,在临床试验中也很常见。 数值特征和范畴特征是表形式特征的两种重要类型。
- 文本功能:在临床试验中,有许多文本特征包含丰富的信息,用于AI建模。例如,资格标准描述患者招募需求时用非结构化自然语言;每个临床试验都包含一个摘要,由2到5个自然语言句子组成,描述所测试的治疗方法、要治疗的目标疾病以及临床试验的主要目标。
- 药物分子:药物分子最具表现力和直观的数据表示是二维分子图,其中每个节点对应分子中的一个原子,而边对应化学键。分子图主要包含两个核心组成部分:节点身份和节点互连性。节点的身份包括原子类型,例如碳、氧、氮等。节点的连通性可以用邻接矩阵表示,其中(i,j)第元素表示第i个和第j个节点之间的连通性。
- MeSH术语:医学主题词(MeSH)全面索引、编目并搜索生物医学及健康相关信息。它由一组层级结构中的术语组成,能够更精确、更高效地检索信息。与主要分类疾病和医疗状况的ICD-10不同,MeSH还用于索引和检索解剖学、药物和疾病等更广泛健康相关主题的信息。
- 疾病代码:医疗服务提供者使用多种标准化疾病编码系统进行临床健康信息的电子交换,包括国际疾病分类第十版临床修订版(ICD-10-CM)、国际疾病分类第九版临床修订版(ICD-9-CM)以及系统化医学命名法-临床术语(SNOMED CT)40。这些编码系统包含以层级结构组织的疾病概念。以ICD-10-CM代码为例。ICD-10-CM是一种七字符的字母数字代码。每个代码以一个字母开头,字母后面跟着两个数字。ICD-10-CM的前三个字符是“类别”。该类别描述了一般类型的伤害或疾病。小数点和子范畴紧随范畴。
四、多模态模型测试结果
4.1 多模态模型
对于所有分类和回归任务,作者应用各种深度神经网络来表示多模态特征。每个表示是一个具有连续值的嵌入向量。然后,我们将这些表示串接起来,输入多层感知器(MLP),并做出预测。在资格标准设计任务中,作者使用 OpenAI ChatGPT API(
- 类别和数值表特征:DANets 因其关键组件的模块化特性以及无需超参数调优即可实现竞争性能而脱颖而出。关键组件——基础块模块,支持灵活堆叠,使DANet适合作为处理数值和类别特征的子模块。经过预处理(例如归一化),三个轻量级基本模块依次堆叠,从输入的类别和数值特征中层次选择、提取和合并特征,最终得到50维嵌入。
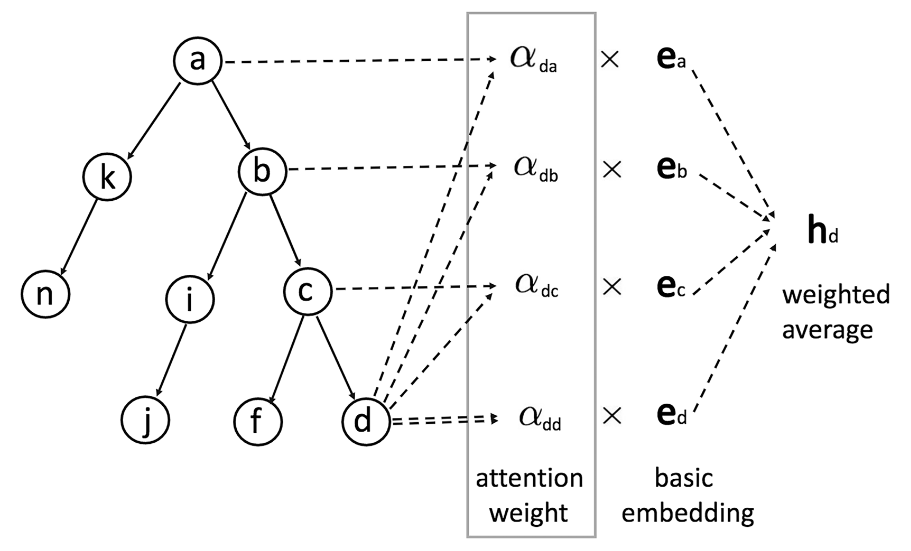
- 疾病代码:基于图的注意力模型(GRAM)是一种基于注意力的神经网络模型,利用疾病编码(医学本体)固有的层级信息。
- MeSH术语:类似于现代词嵌入表示词语语义,MeSH词库中的医学主题词(MeSH)代码也可以通过嵌入方法表示。 MeSH-Embedding 已用 node2vec 算法预训练了一个 MeSH 嵌入层,参数为默认参数。对于未包含在MeSH嵌入层预训练中的MeSH项,我们采用了从零学习的新参数嵌入层。
- 文本功能:来自Transformers的双向编码器表示(BERT)是一种强大的预训练技术,其根源源自Transformer架构,专门为自然语言处理(NLP)任务设计。近年来,它被广泛应用于药物发现,并被证明在文本数据建模方面非常有效。BERT是通过叠加多层变换器块构建的。每一层的输出作为下一层的输入,从而使模型能够学习输入数据的越来越复杂的表示。该技术形成了一个深度的双向架构,能够从过去和未来代币中连续捕获上下文信息。使用BERT完成此任务的主要优势在于,它使模型能够利用从大量未标记数据中获得的知识,更好地理解序列与其对应属性之间的关系。这使得模型能够比仅用有限的标记数据从零训练模型时做出更准确的预测。本文采用了Bio-BERT,这是一种在生物医学文献中预训练的BERT变体。
- 药物分子:药物分子本质上是二维平面图。图神经网络(GNN)是一种神经网络架构,它以图结构化数据为输入,在连接的边和节点之间传输信息以捕捉它们之间的交互,并学习图节点及整个图的向量表示。消息传递神经网络(MPNN) 是 GNN 的一个流行的变体,它更新图中边的信息。首先,在节点层面,每个节点v都有一个特征向量,记作ev。例如,分子图中的节点 v 是一个原子,ev 包含原子类型、价数及其他原子性质。ev 可以是单热向量,表示节点 V 的范畴。在边层面,euv 是边 (u, v) 的特征向量。N(u) 表示该节点 u 所有邻居节点的集合。在第l层,m(ulv)和m(vlu)是方向性边嵌入,表示节点u到节点v的消息,反之亦然。
- 表征融合:获得多模态数据表示后,我们将这些表示串接,将连接的向量输入多层感知器(MLP),并进行预测。对于二元分类任务(例如试验批准预测),我们使用 sigmoid 函数作为输出层的激活函数,以获得预测概率;对于多类别分类任务(例如试验失败原因识别),我们使用SoftMax作为输出层的激活函数,生成所有类别的概率分布;对于回归任务(例如试验时长预测),我们不在输出层使用激活函数来生成连续值预测。我们使用交叉熵准则作为分类任务的损失函数,均方误差(MSE)作为回归任务的损失函数。
4.2 实验细节
所有代码都是用Python 3.8实现的。所有深度学习模型均由PyTorch实现,我们使用GPT 4.0进行数据注释和生成任务。所有表示的嵌入大小都设置为100。我们使用 Adam 作为数值优化器,以最小化损失函数,初始学习率为 1e − 3,权重衰减为零。批量数量设置为64。最大训练 epoch 设置为20。
4.3 评估指标
- 在分类任务中,通过准确度、PR-AUC(精度-回忆曲线下的面积)、F1分数(精度与回忆的谐和平均值)、精度、回忆、特异性和ROC-AUC(受试者工作特征曲线下的面积)来评估模型性能。
- 回归任务中,我们使用RMSE(均方根误差)、MAE(平均绝对误差)、索引和皮尔逊相关作为指标。
- 对于生成任务(资格标准设计),我们设计了一些语义指标,用于衡量真实标准与设计标准之间的对齐度,包括文本嵌入的余弦相似度、信息量和冗余性。
4.4 模型结果
五、数据下载
结语