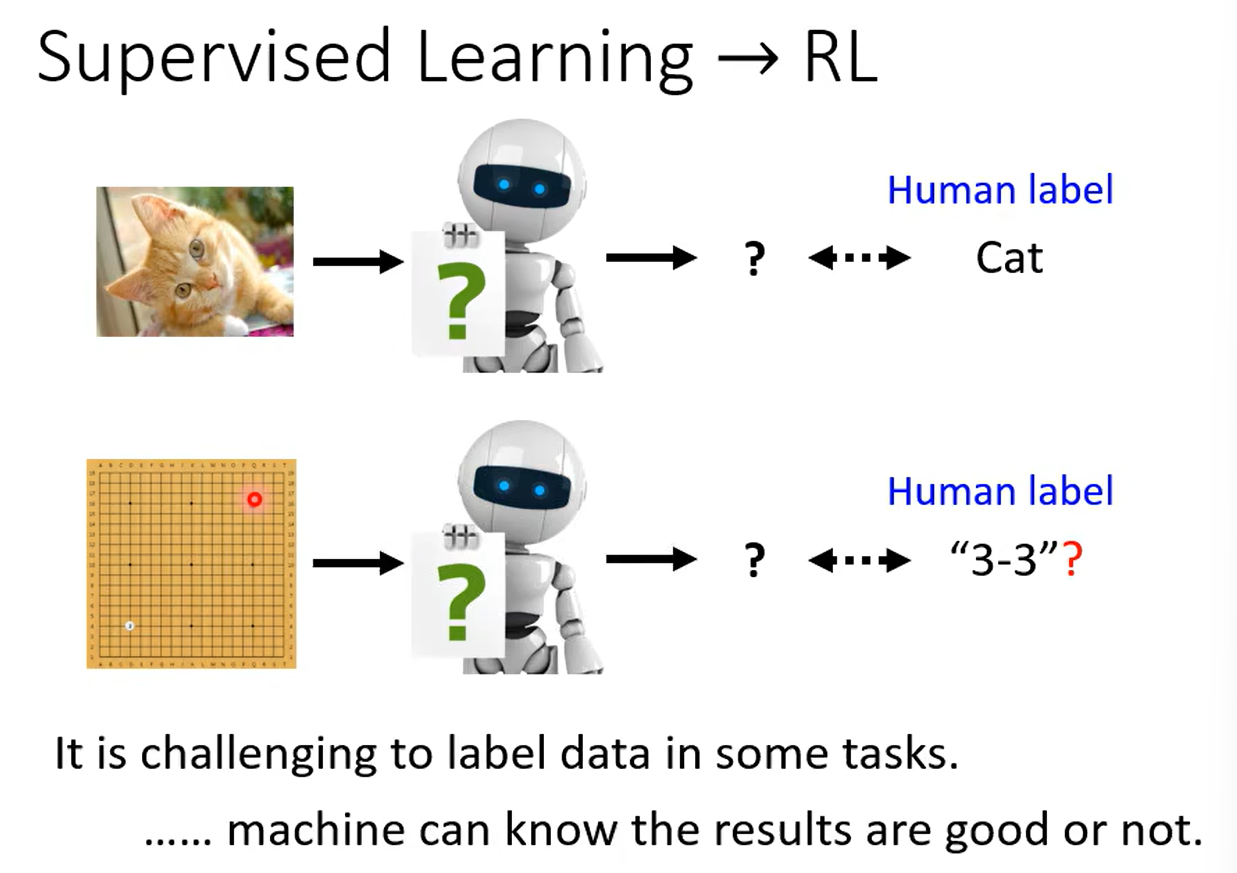
一、强化学习RL
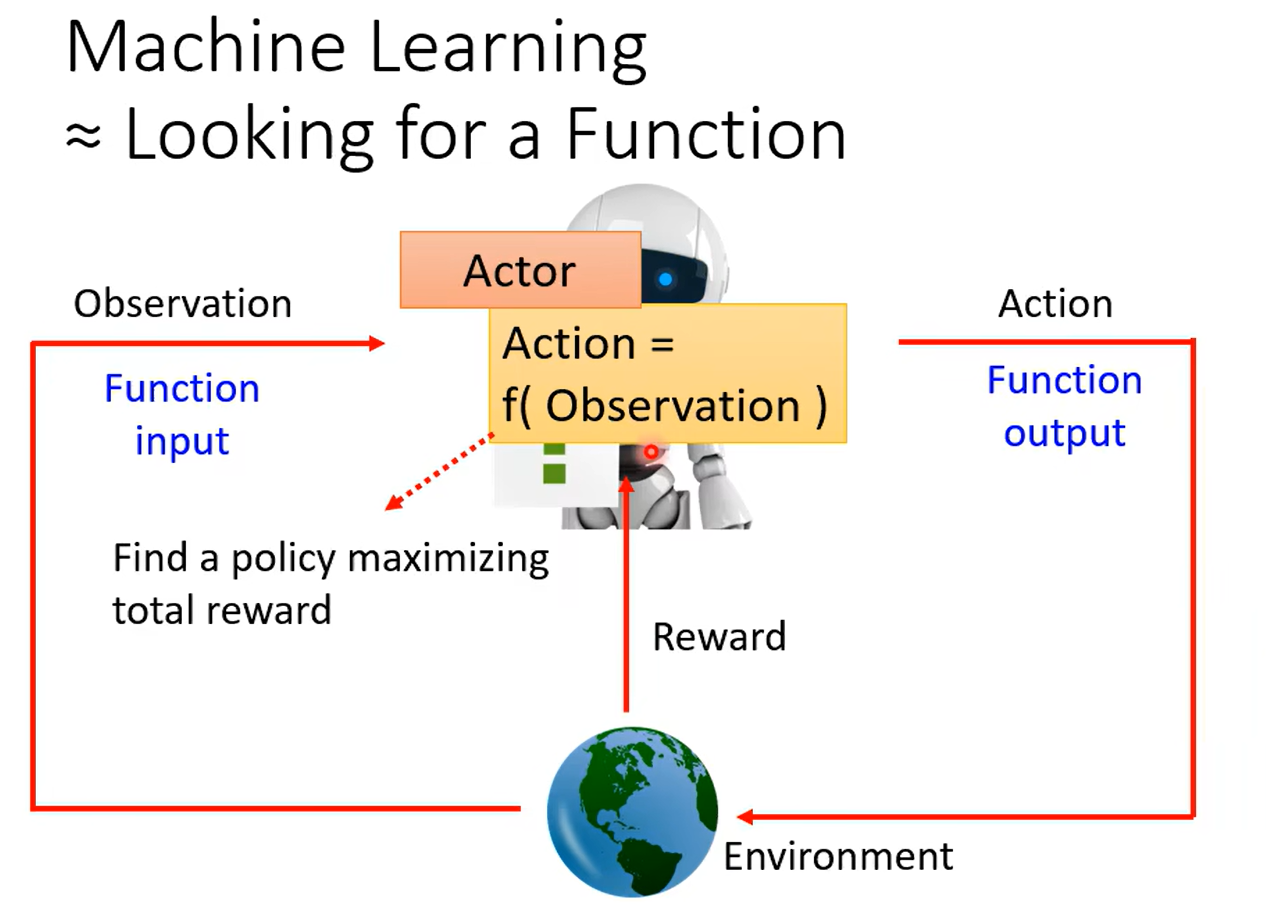
机器学习 = 寻找一个函数 = RL
RL:
Actor行动者
Environment环境
观察+动作
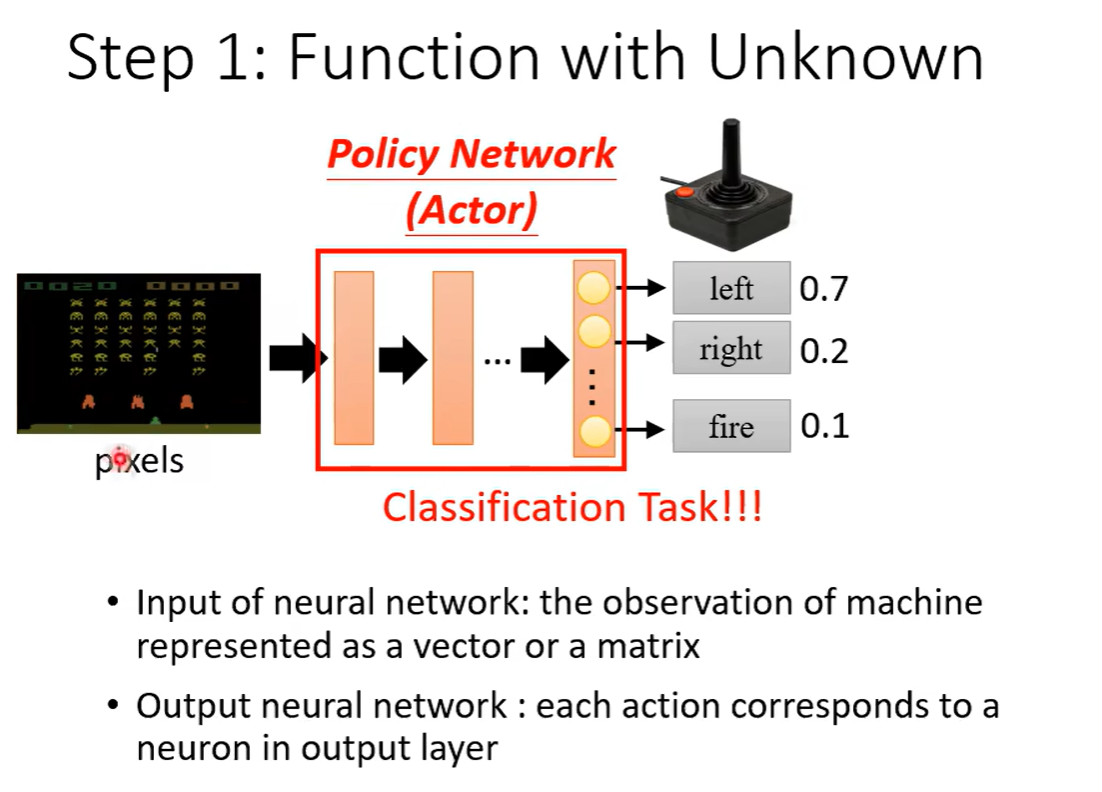
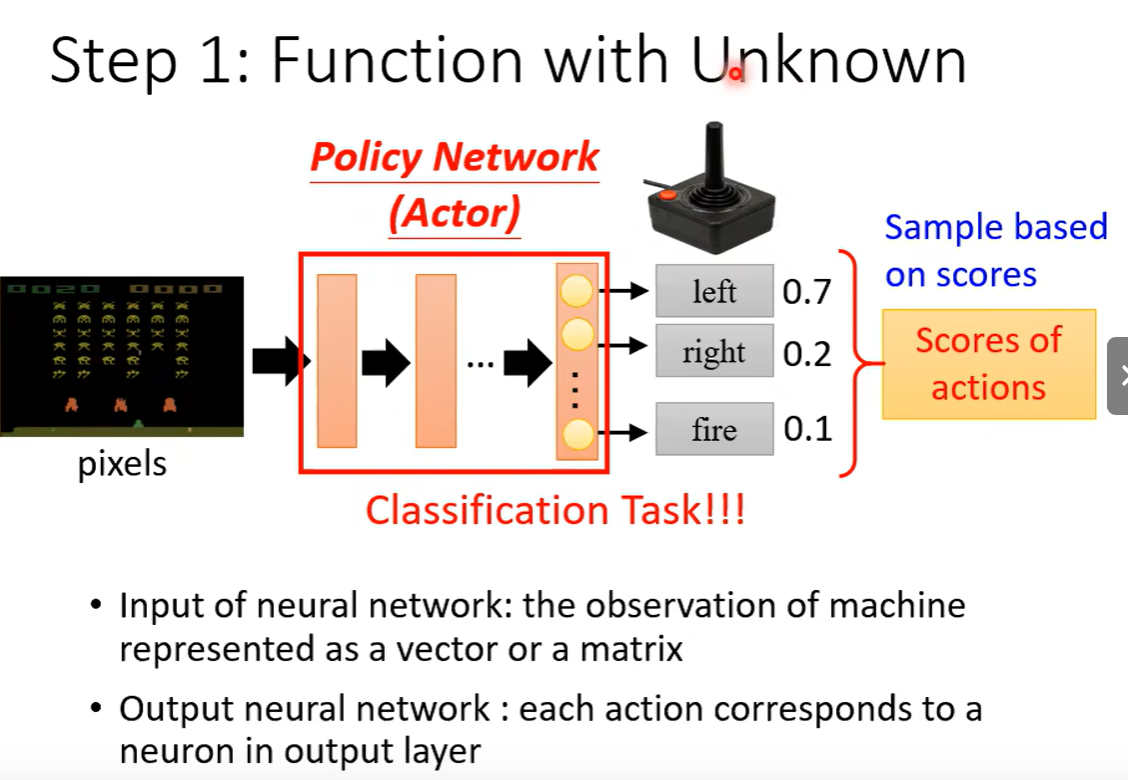
状态s、行为a。
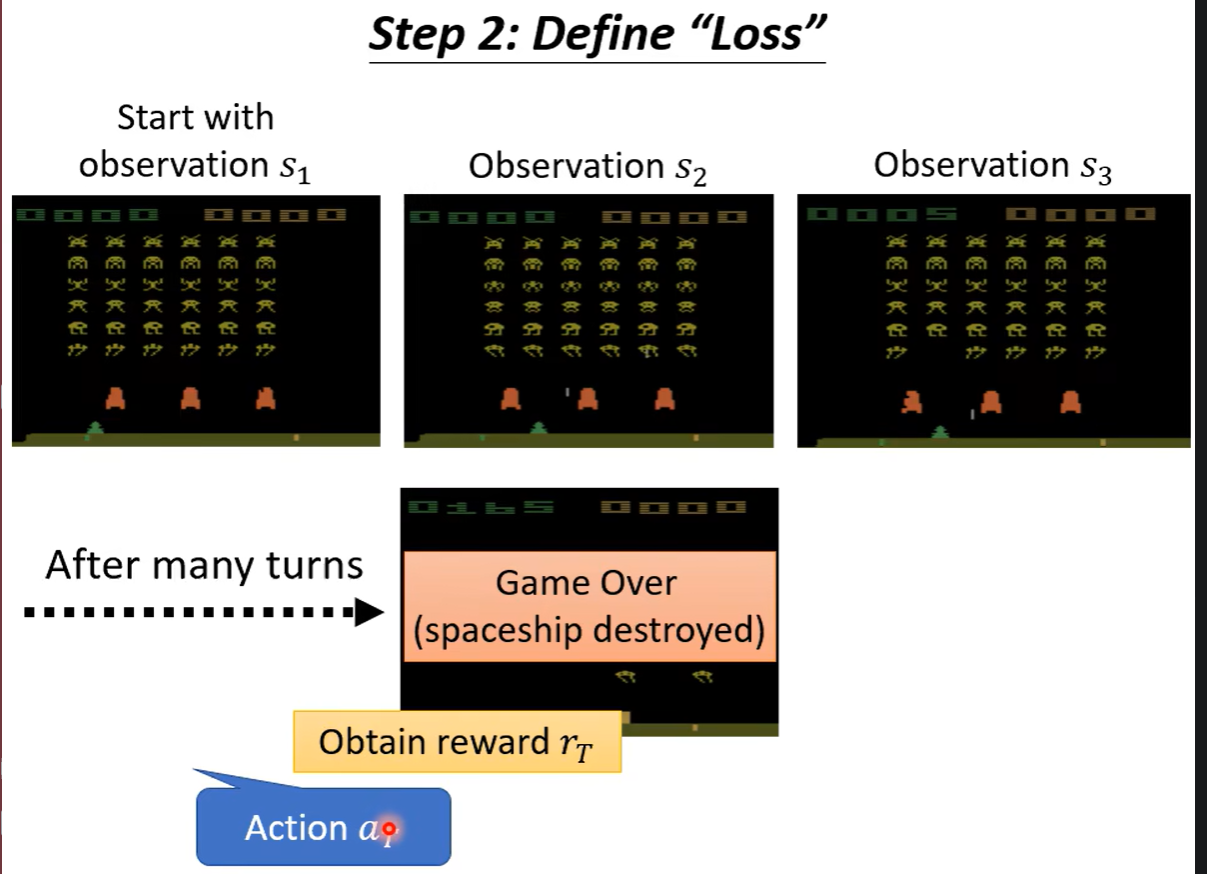

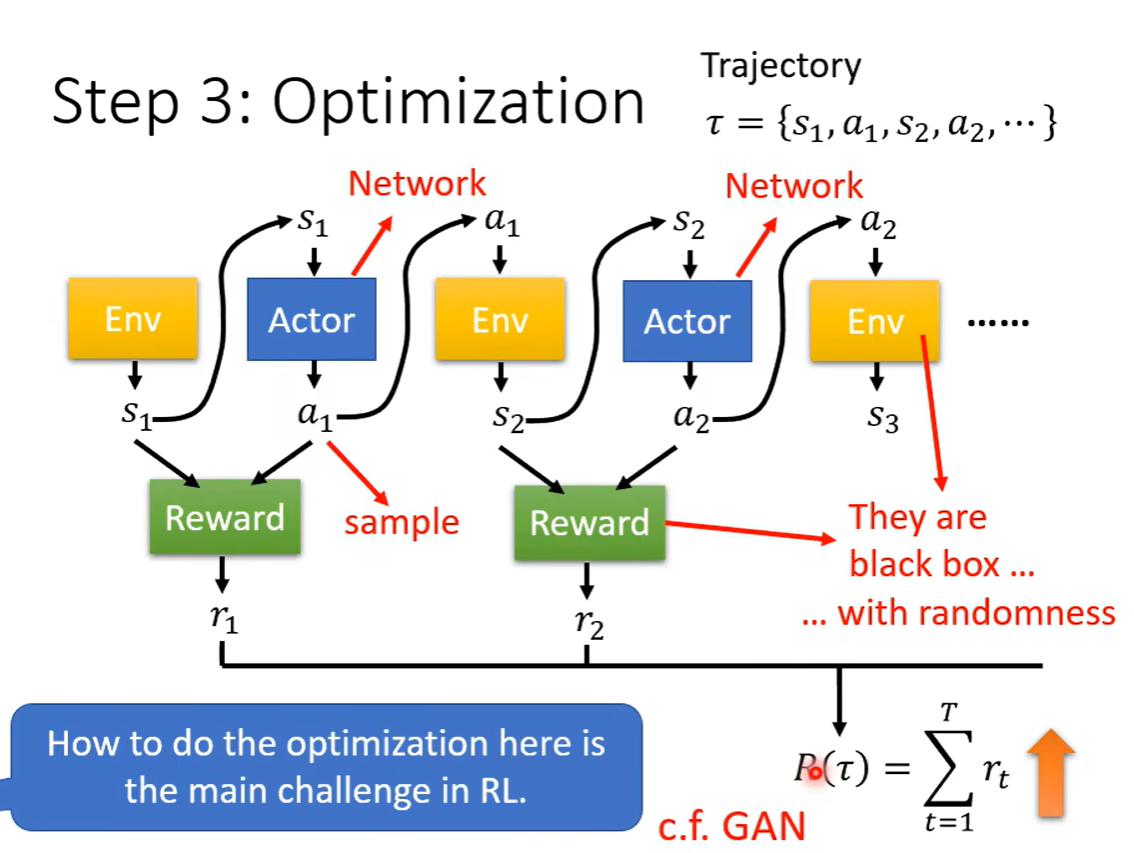
无法梯度下降。
二、策略下降
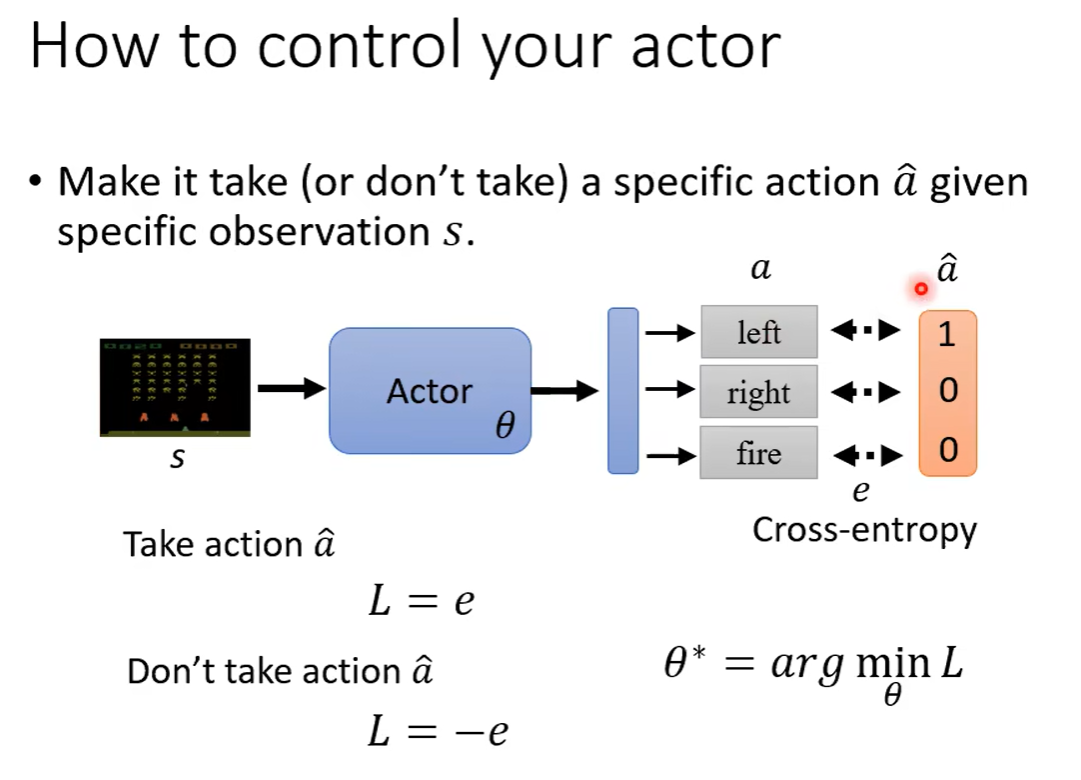
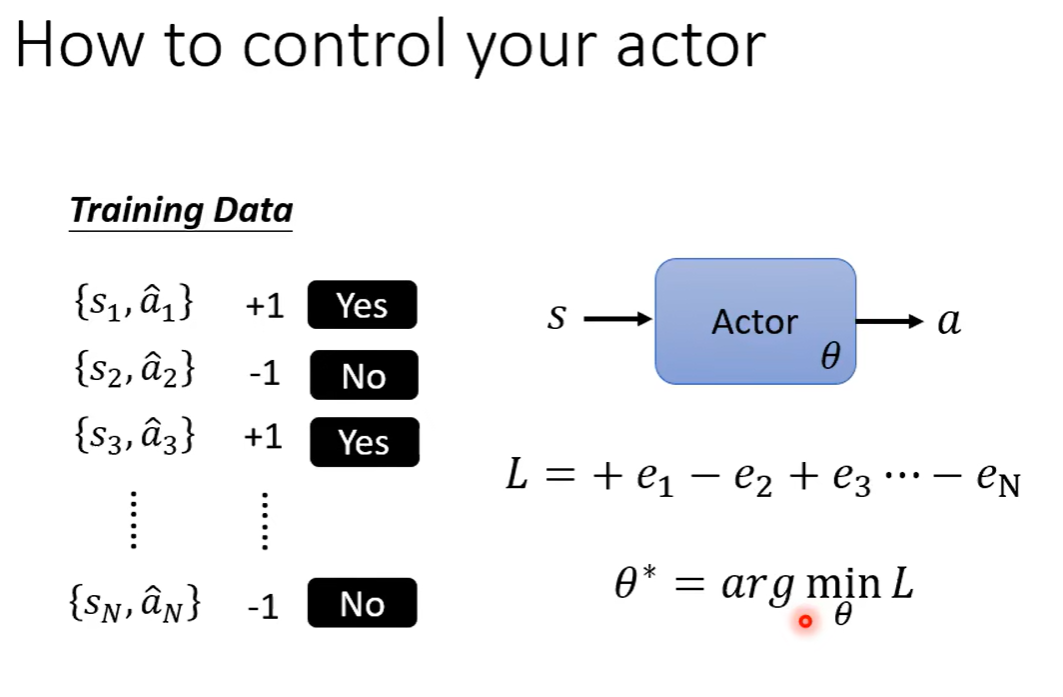

a的定义:
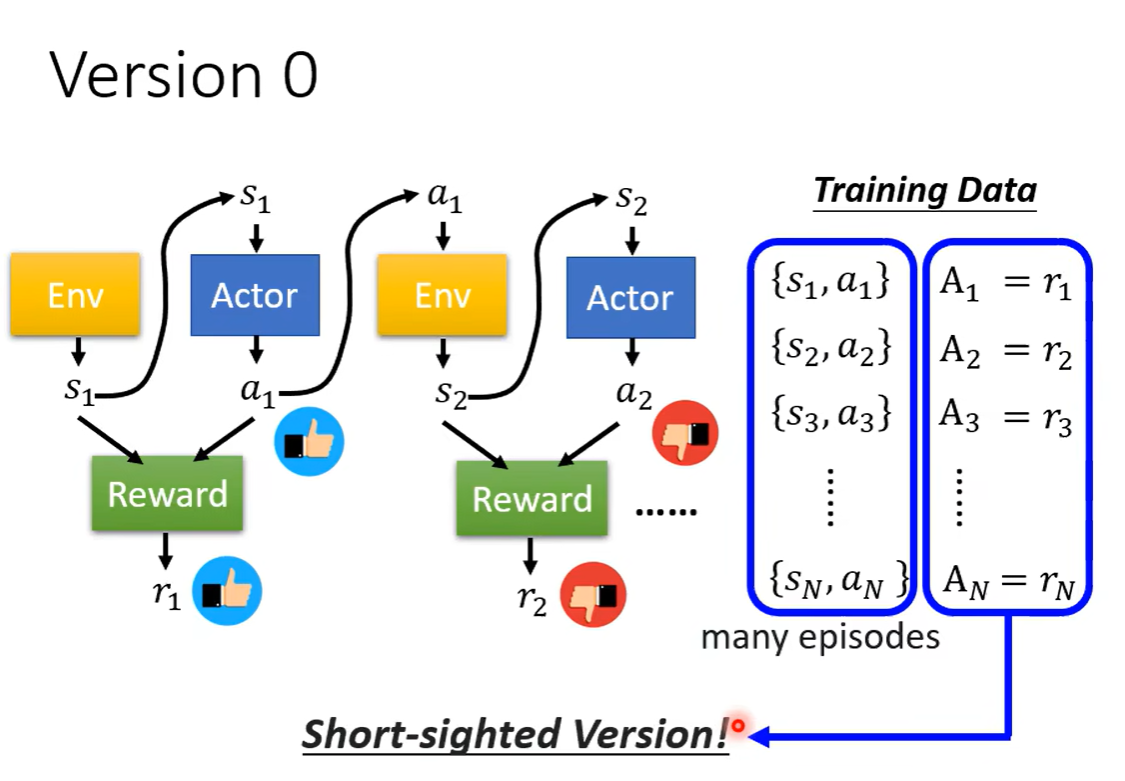
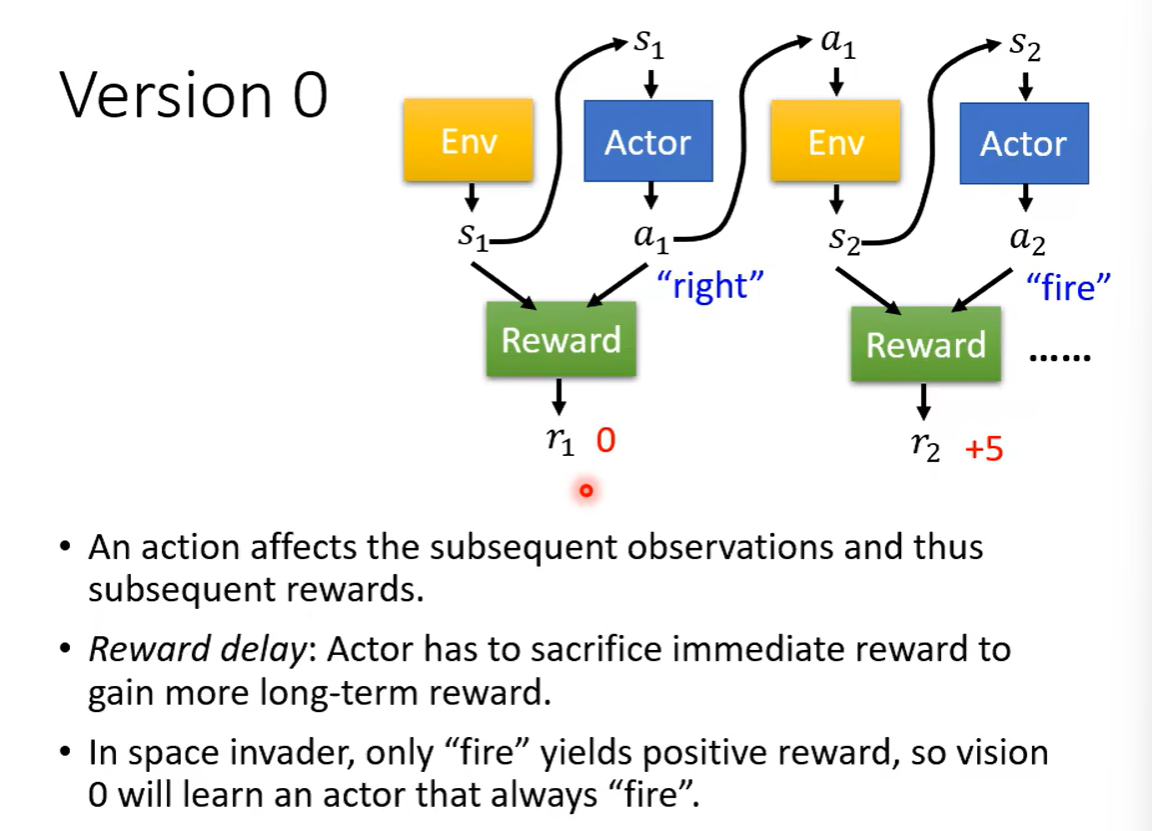
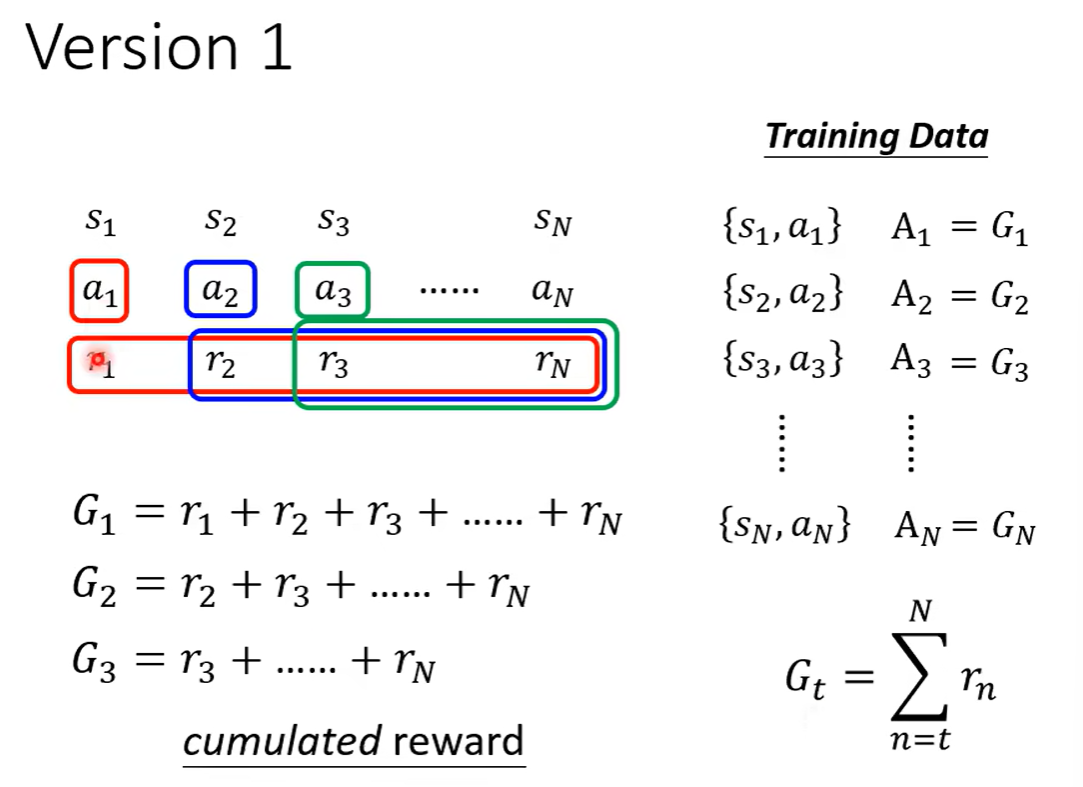




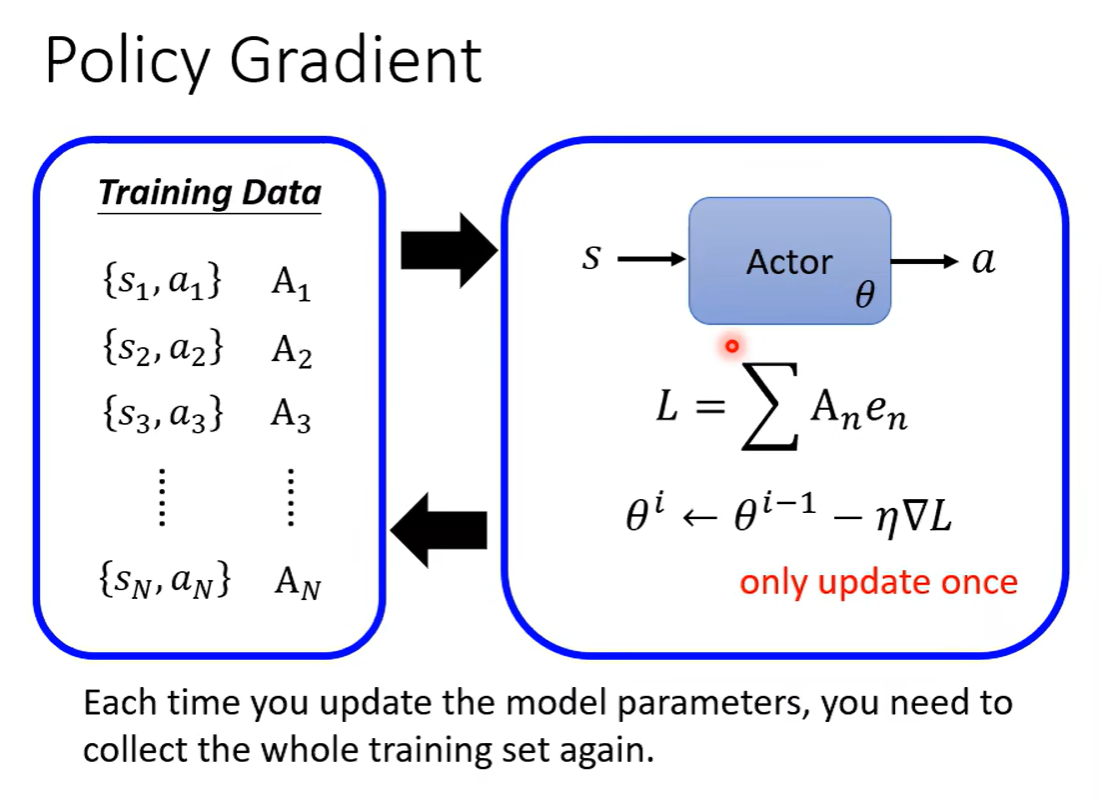
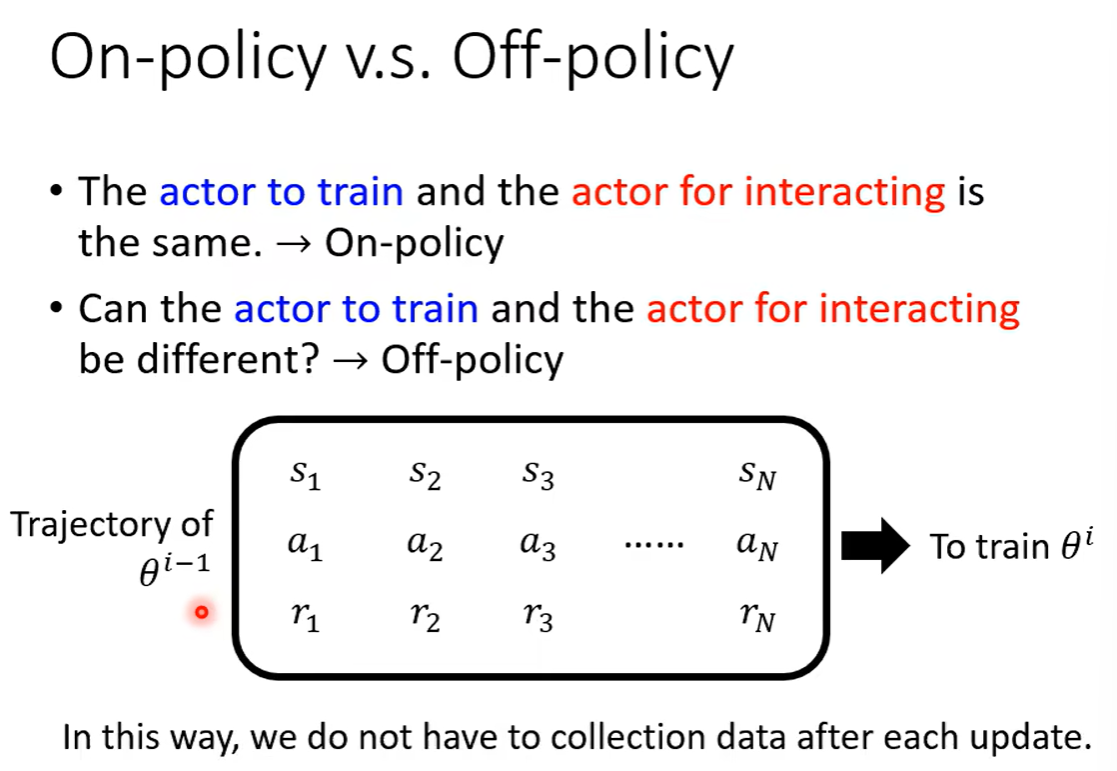
离线策略下降。
随机性
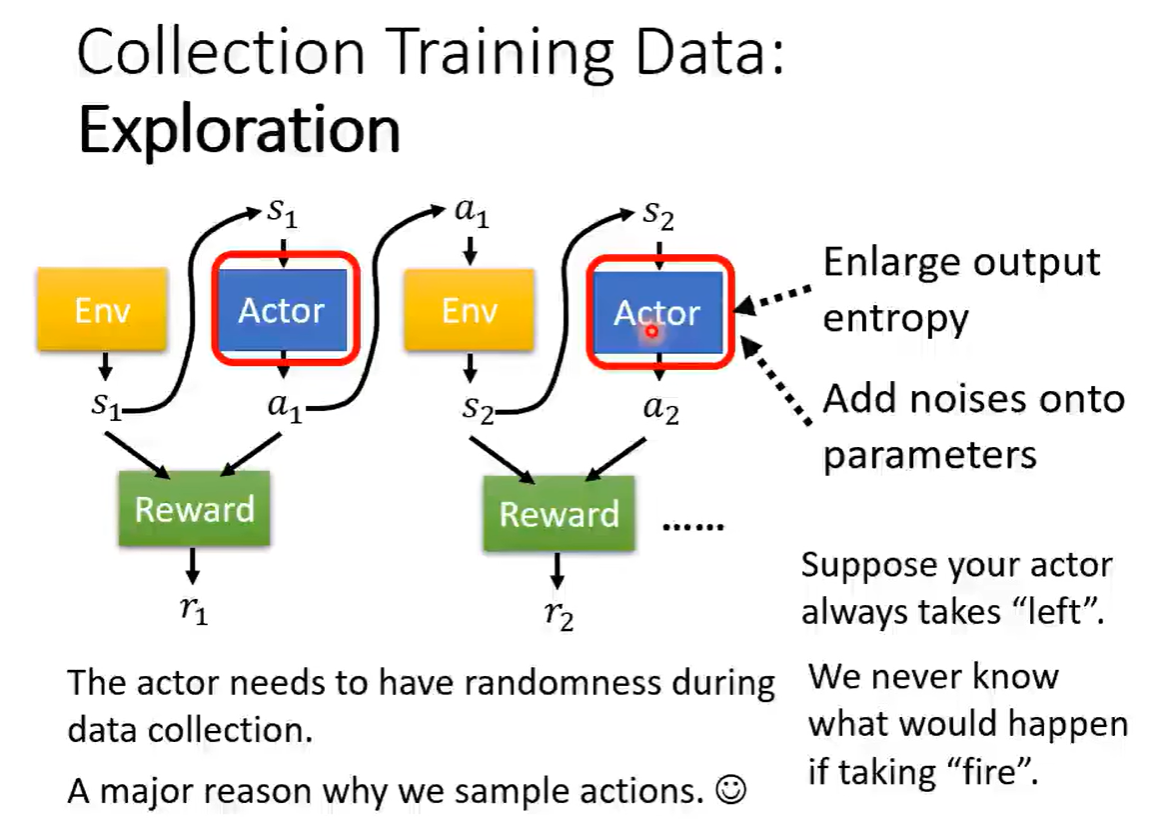
三、Actor-Critic
Critic评估状态的好坏。
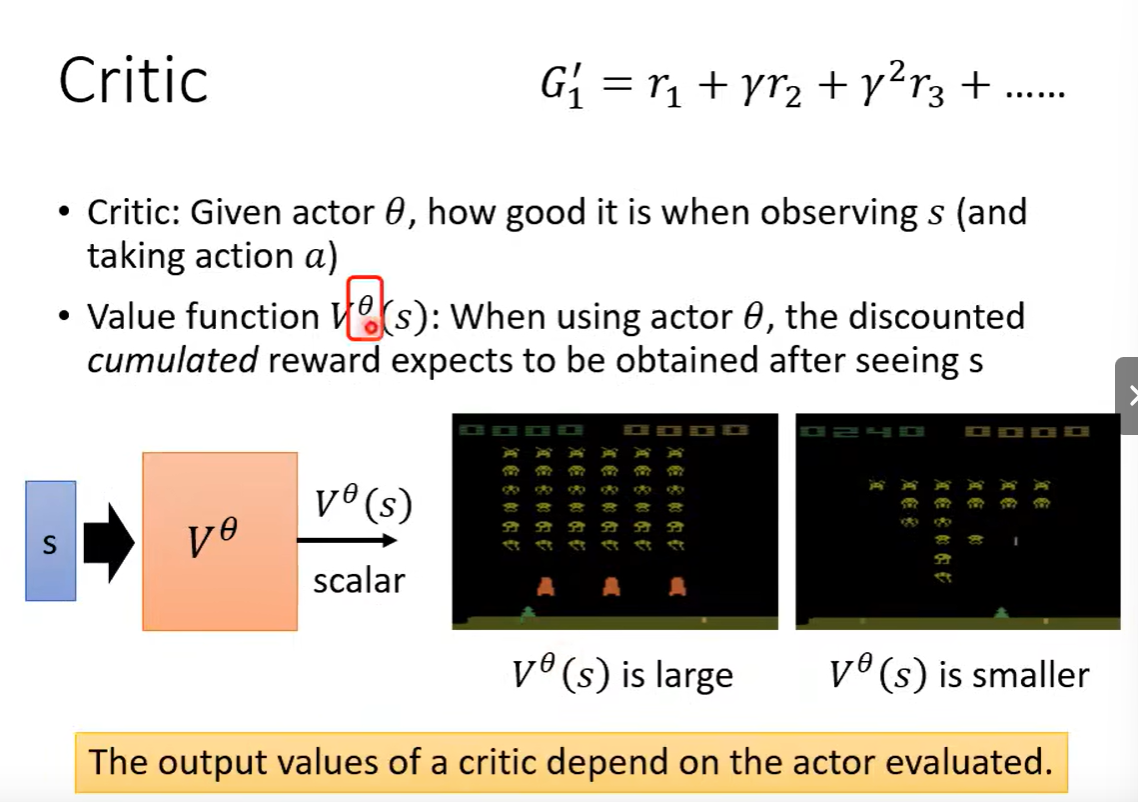
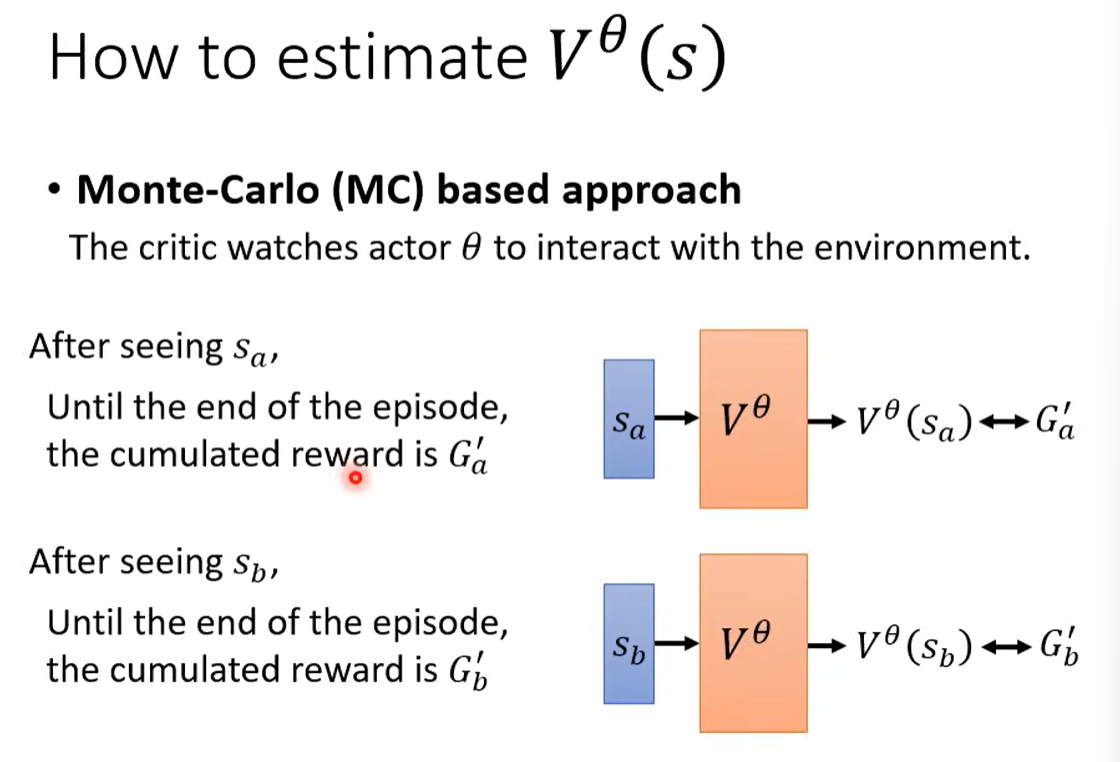


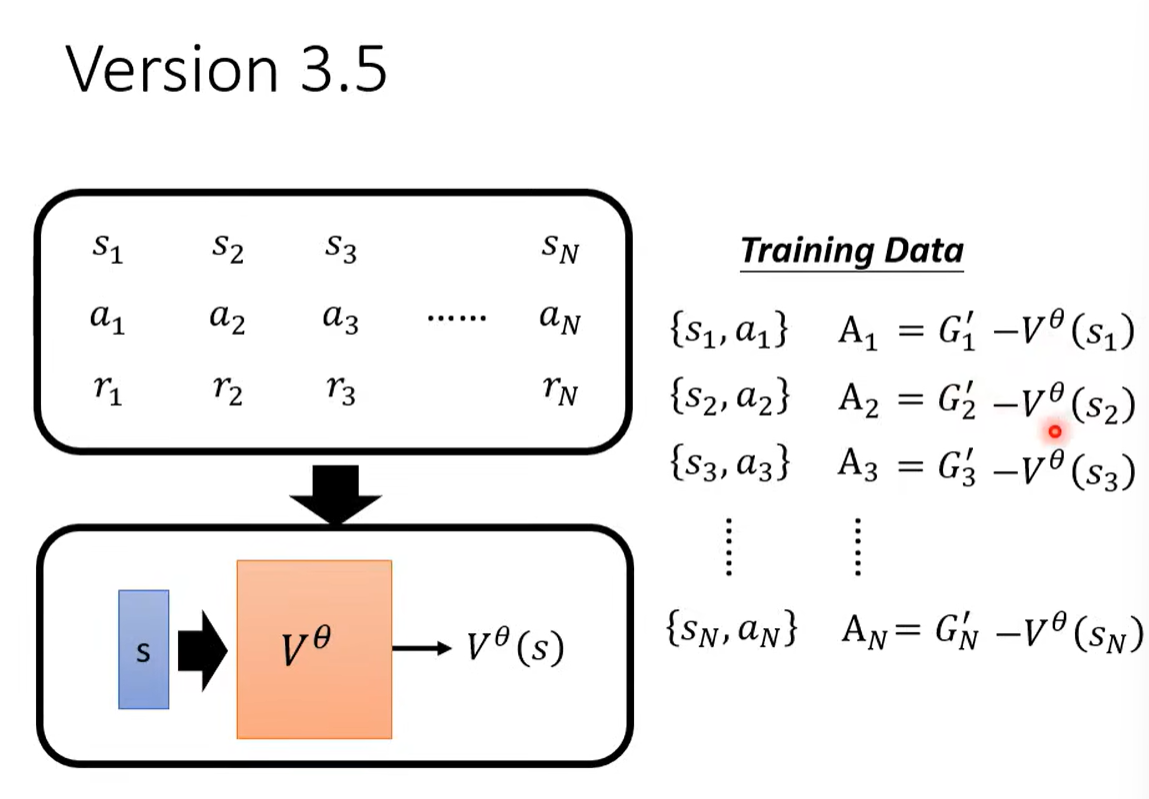
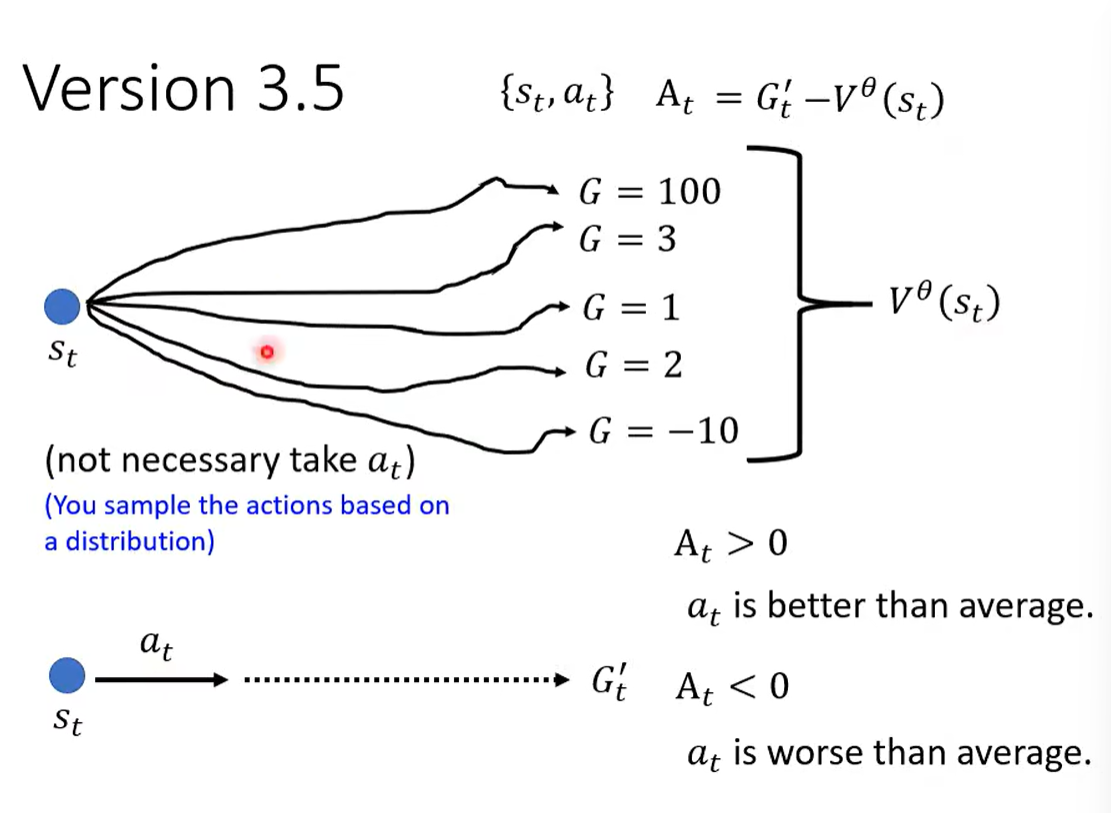
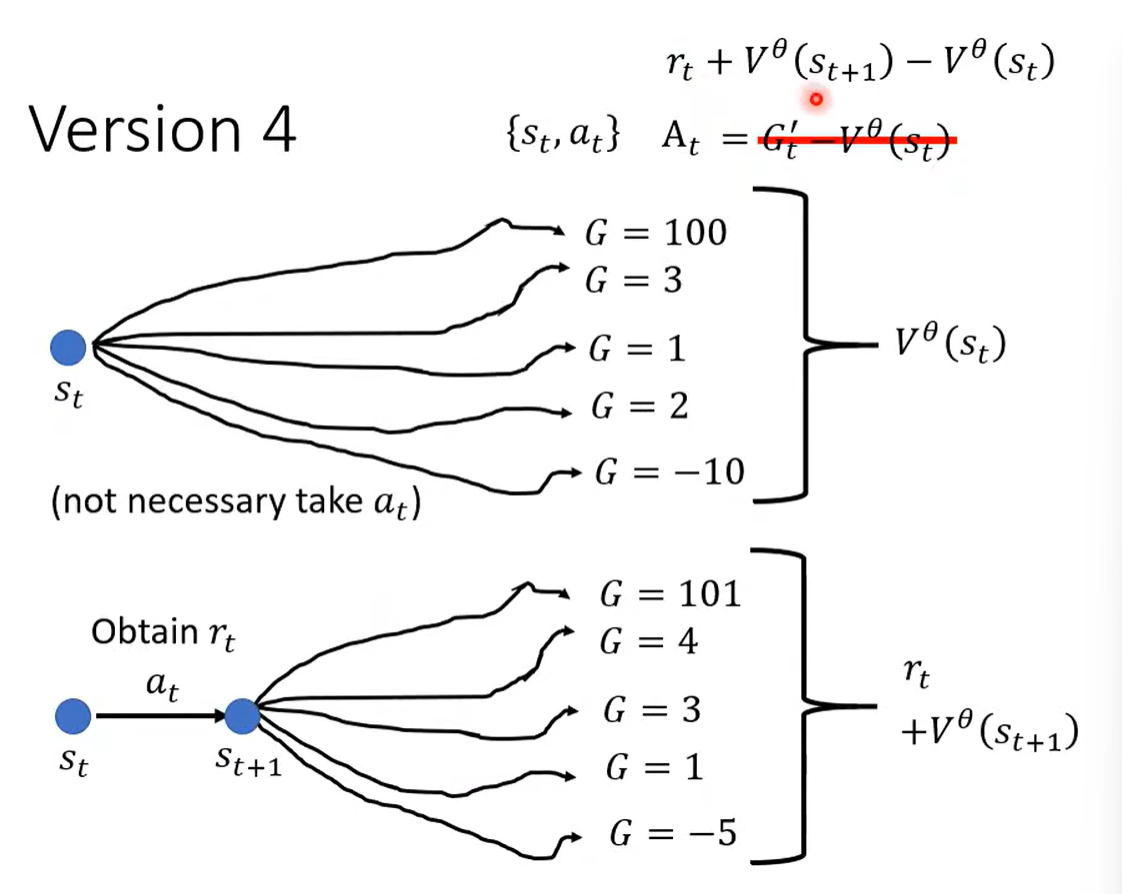

四、Reward Shaping
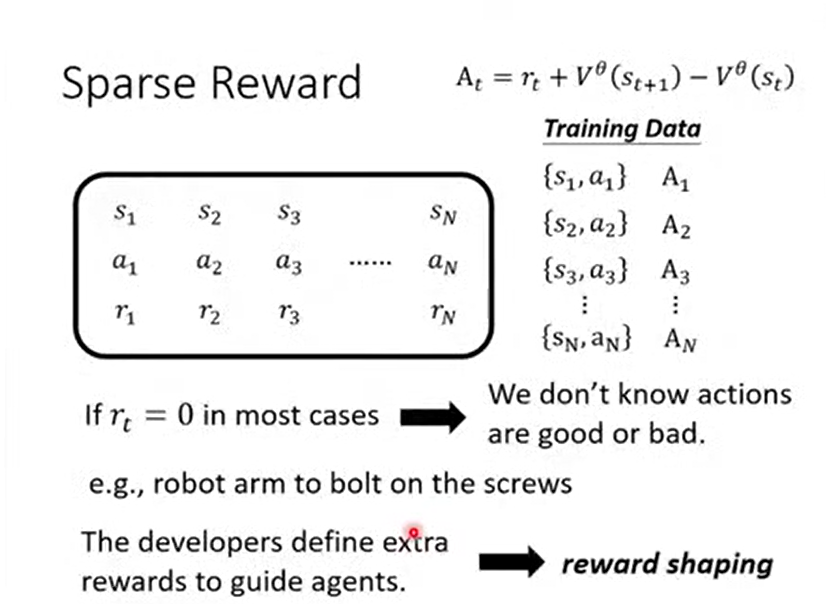
额外的回报
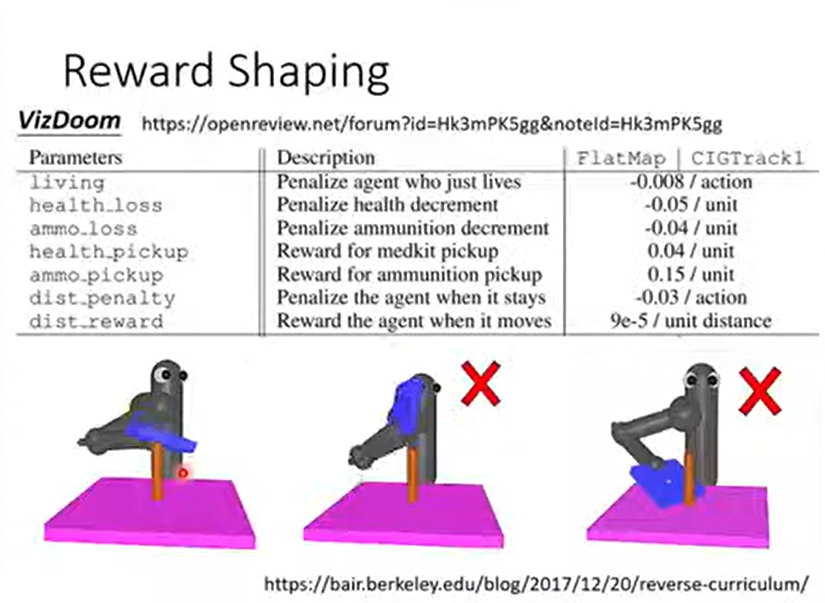
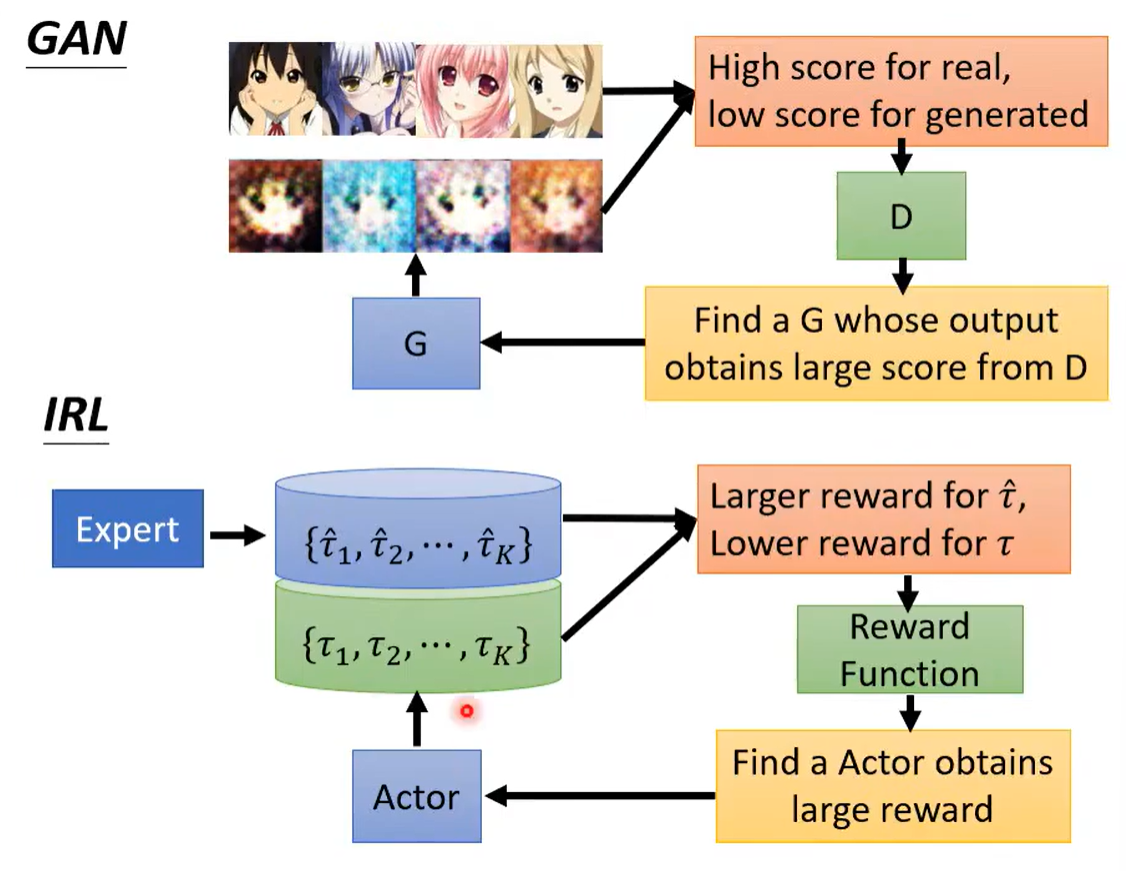
五、No Reward:模仿学习
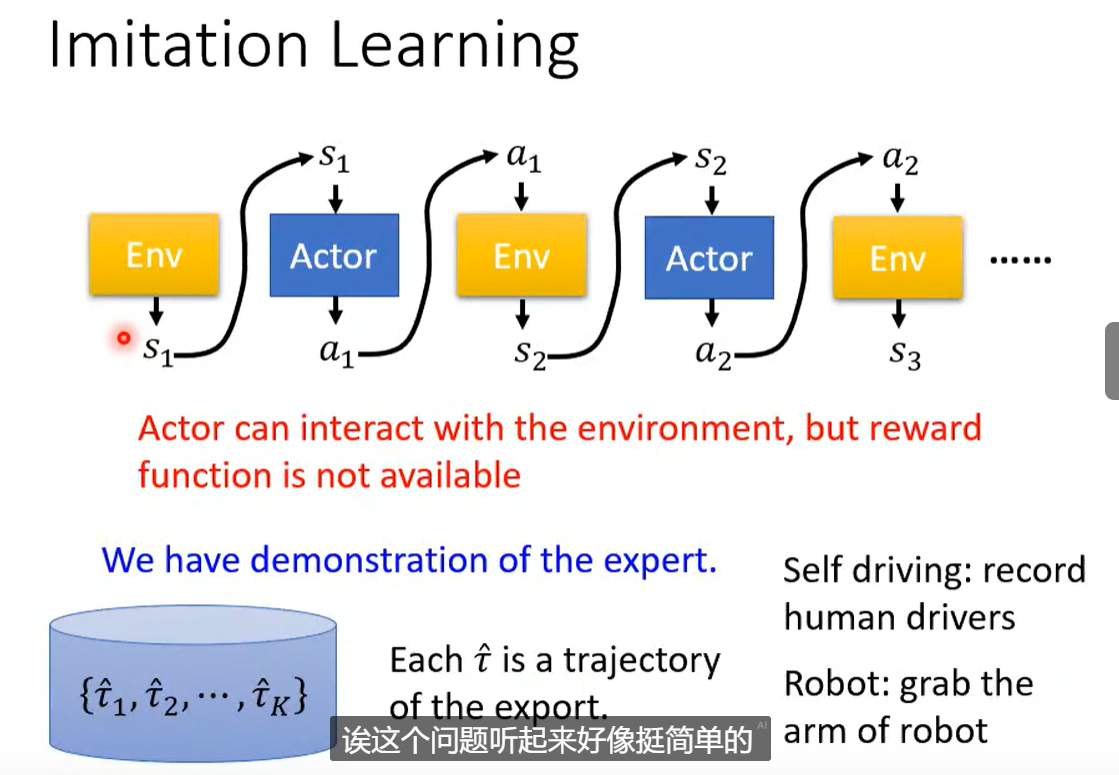
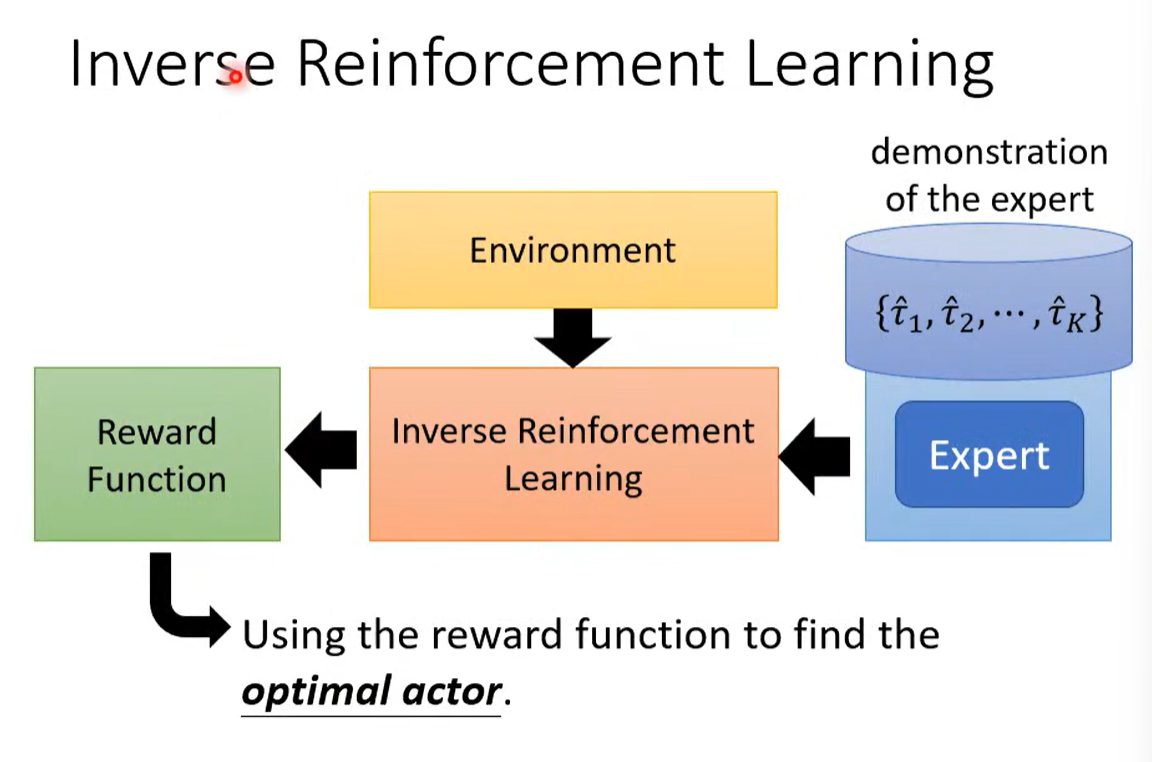

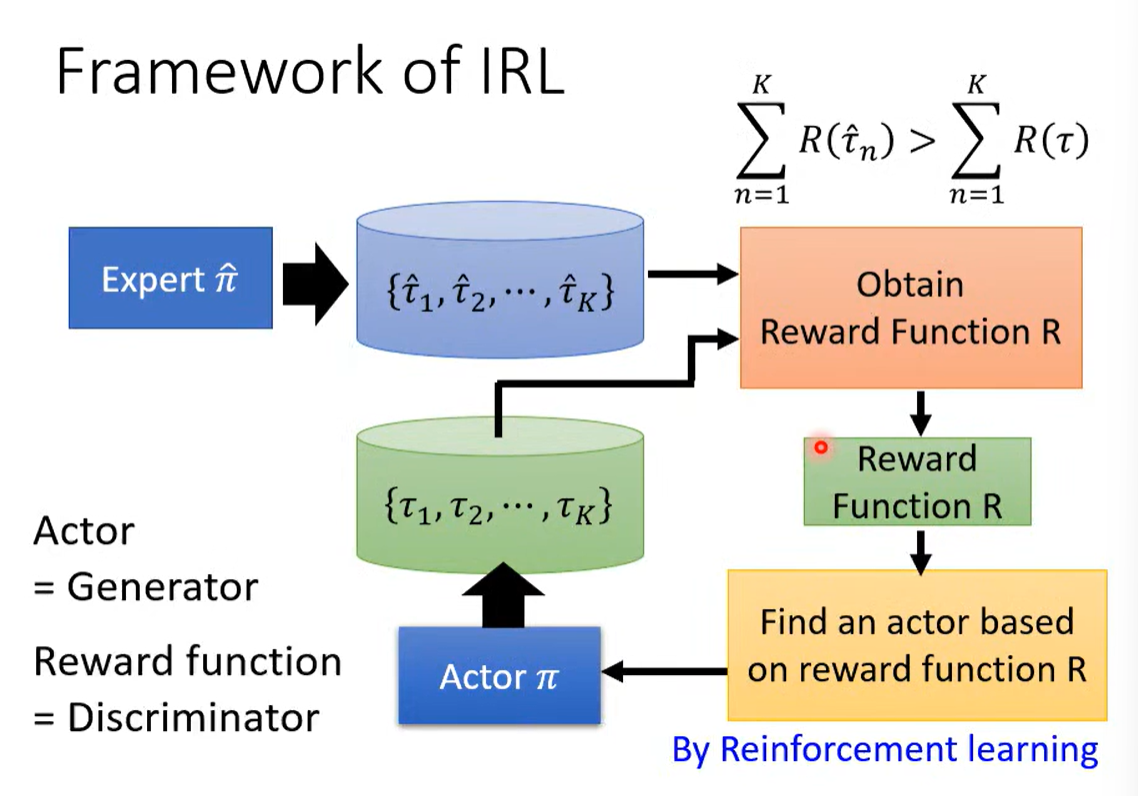
机器学习 = 寻找一个函数 = RL
RL:
Actor行动者
Environment环境
观察+动作
状态s、行为a。
无法梯度下降。
a的定义:
离线策略下降。
随机性
Critic评估状态的好坏。
额外的回报