目录
Q-Learning的介绍
Q-Learning的小技巧
用于持续动作的Q-Learning
一、Q-Learning的介绍
在Q-Learning中是基于值Value的方法。我们要训练的是一个Critic(评判网络)。
Critic的作用是评价了现在的行为有多好或是多么不好。
即给定行动 ,它评价了当前行动的好坏大小
,它评价了当前行动的好坏大小 。
。
例如状态值函数:
当使用Actor π,拜访到s状态后累积的Reward的期望值有多大。
需要注意的是不能单独有Critic的,它需要和一个Actor进行绑定。
因为还是Critic的定义,在给定状态s时,假设互动的是Actor π,计算的Reward的期望。
即 Critic 取决于Actor 和 State。

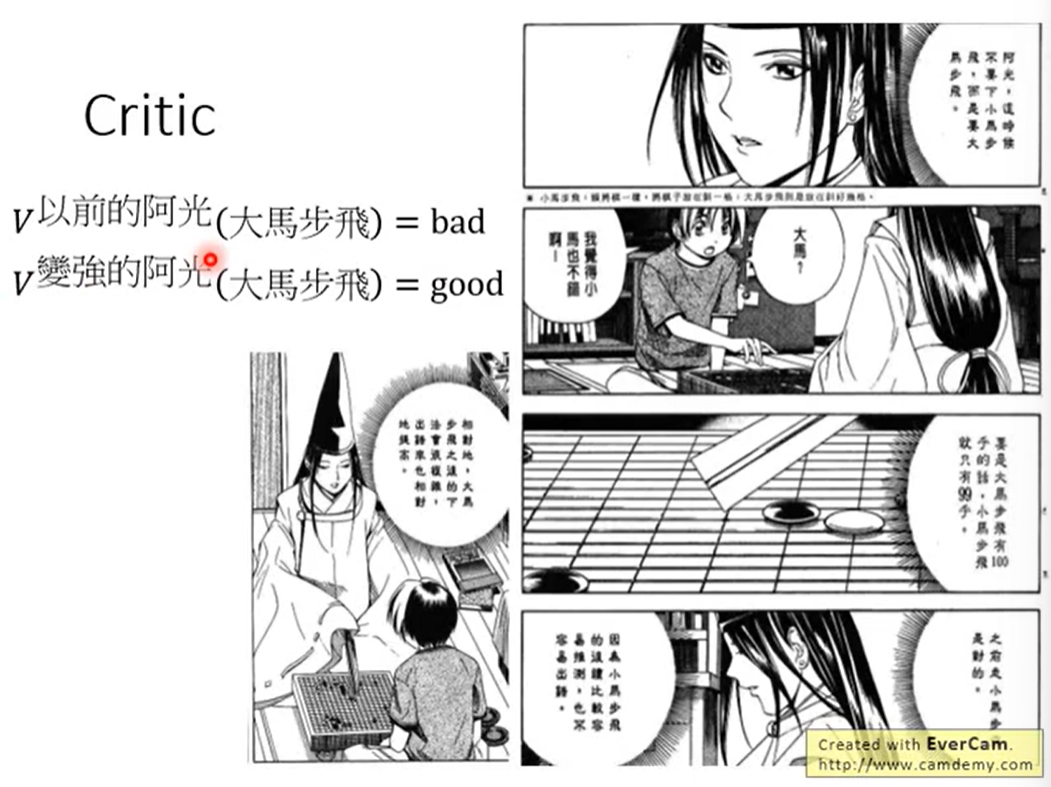
例子:
在不同的时期对相同的状态有不同的评价。
如何去计算 ?
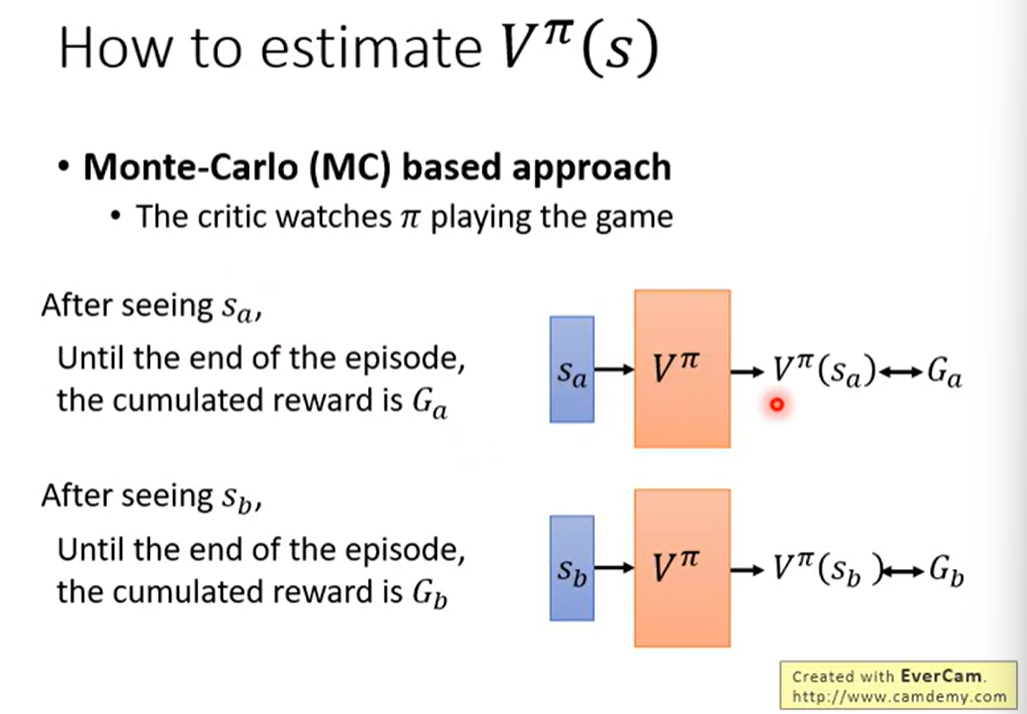
- Monte-Carlo蒙特卡洛方法(MC)
- Temporal-Difference时间差分方法(TD)
MC:
回归到  。
。
TD:
由序列  即可应用TD方法计算。
即可应用TD方法计算。

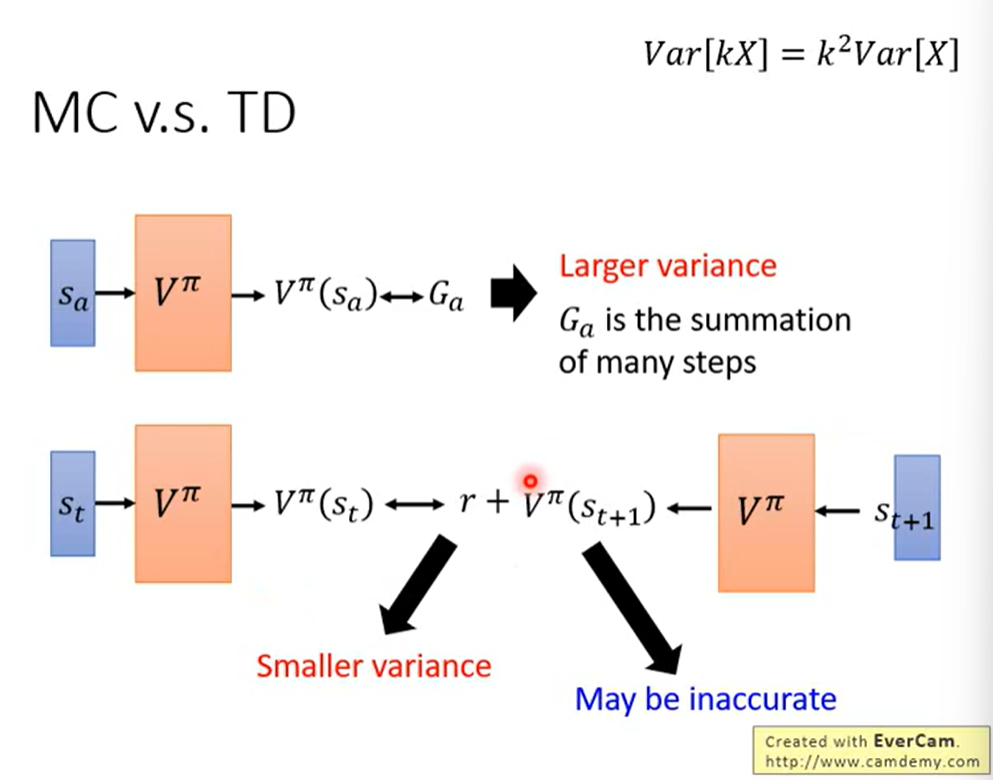
MC v.s. TD:
MC的方差较大,但是较为准确。(常用)
因为G是由多步累加得到的。
TD的方差较小,但不太准确。
例子:
我们互动了8个episodes。
计算期望值:
依据不同的计算方法,计算的结果是不同的。

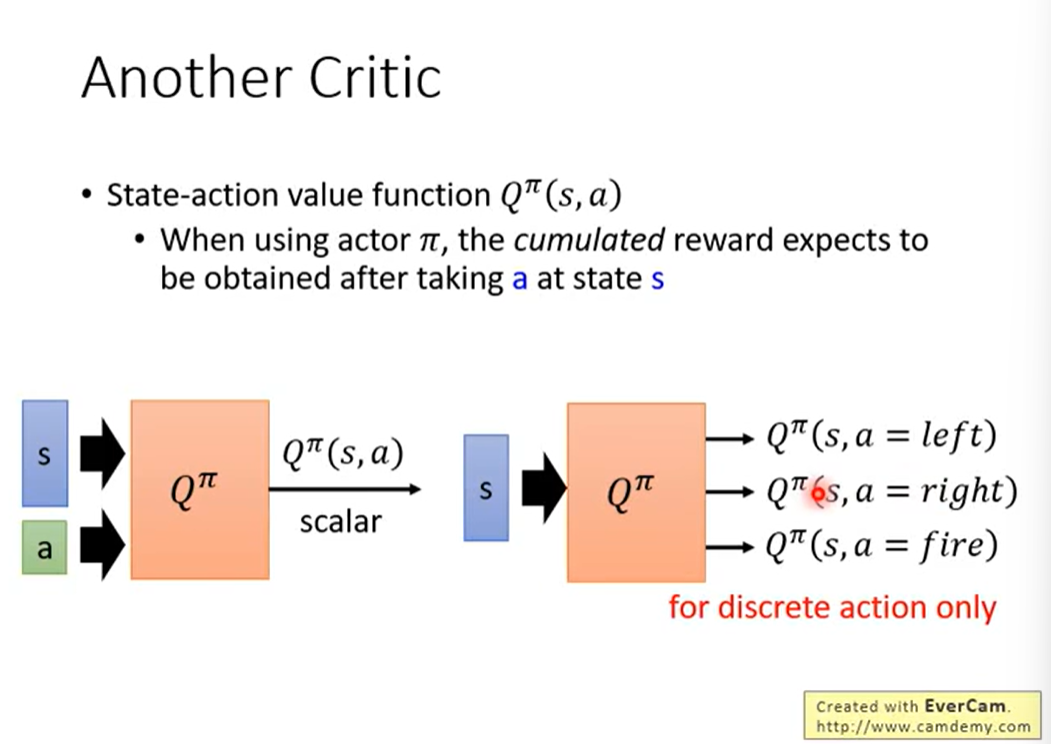
除了上边的Critic之外,还有Q-Learning值函数用作Critic。
即状态行动值函数  。
。
某一个状态 s 采取某一个行动 a ,接下来都是Actor π来采取行动,最终得到的Reward的期望值。
Q函数有两种写法:
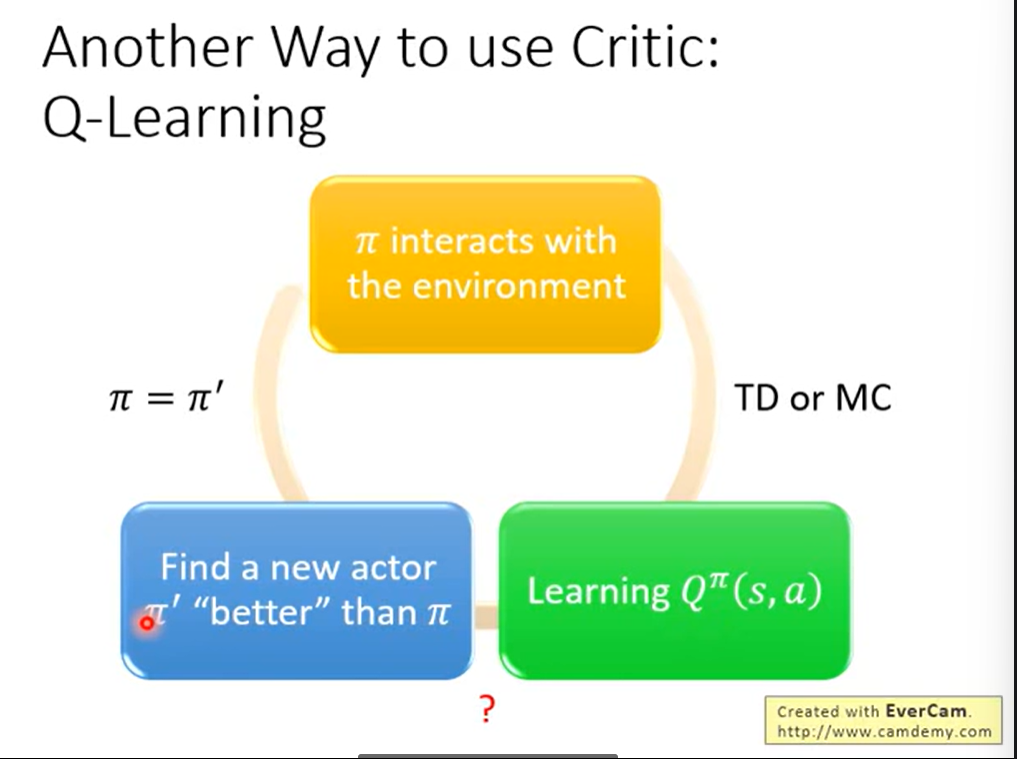
我们Q函数得到的最大值去更新原本的Actor会比原来的好。
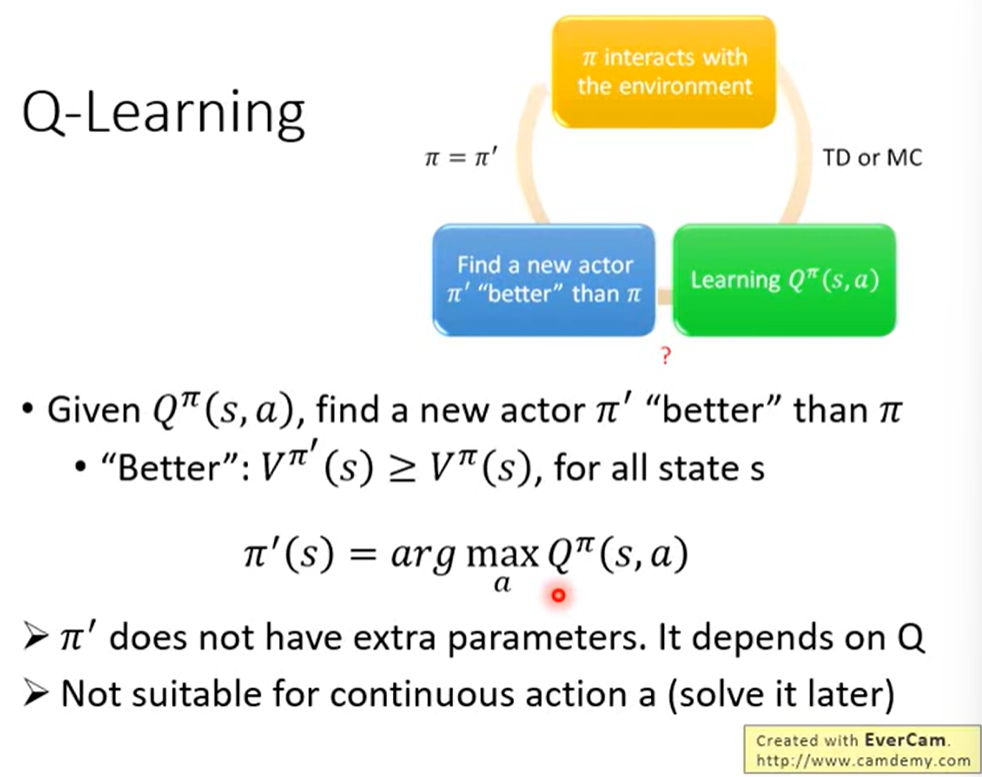
证明:

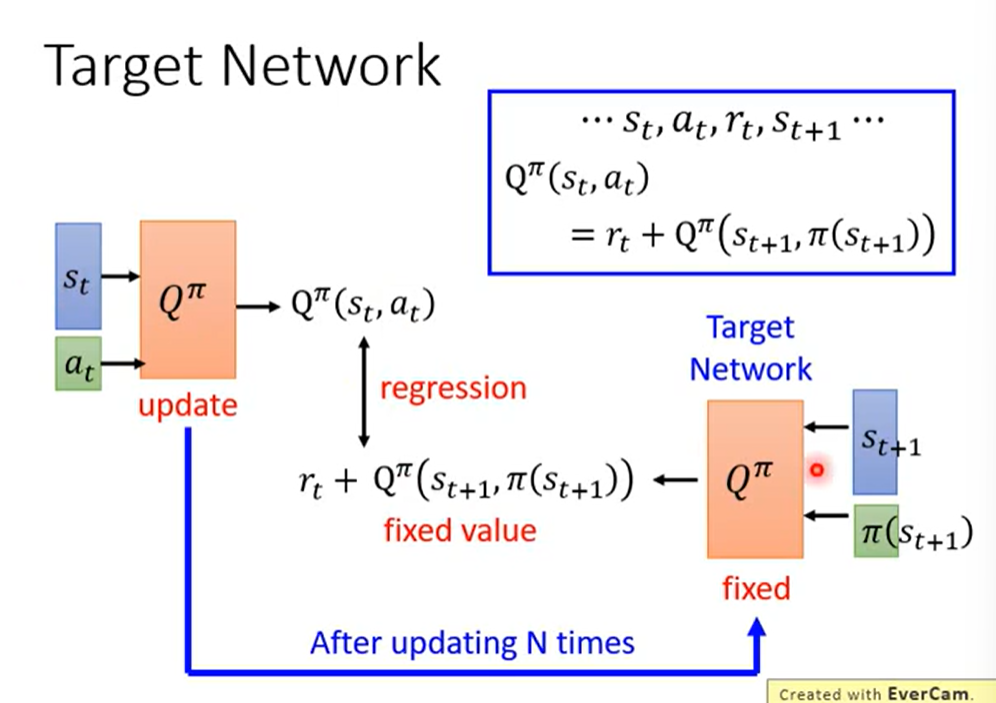
Tip1: Q+TD = Target Network:
Tip2:Exploration
 -贪心策略、玻尔兹曼探索:
-贪心策略、玻尔兹曼探索:

Tip3:Replay Buffer
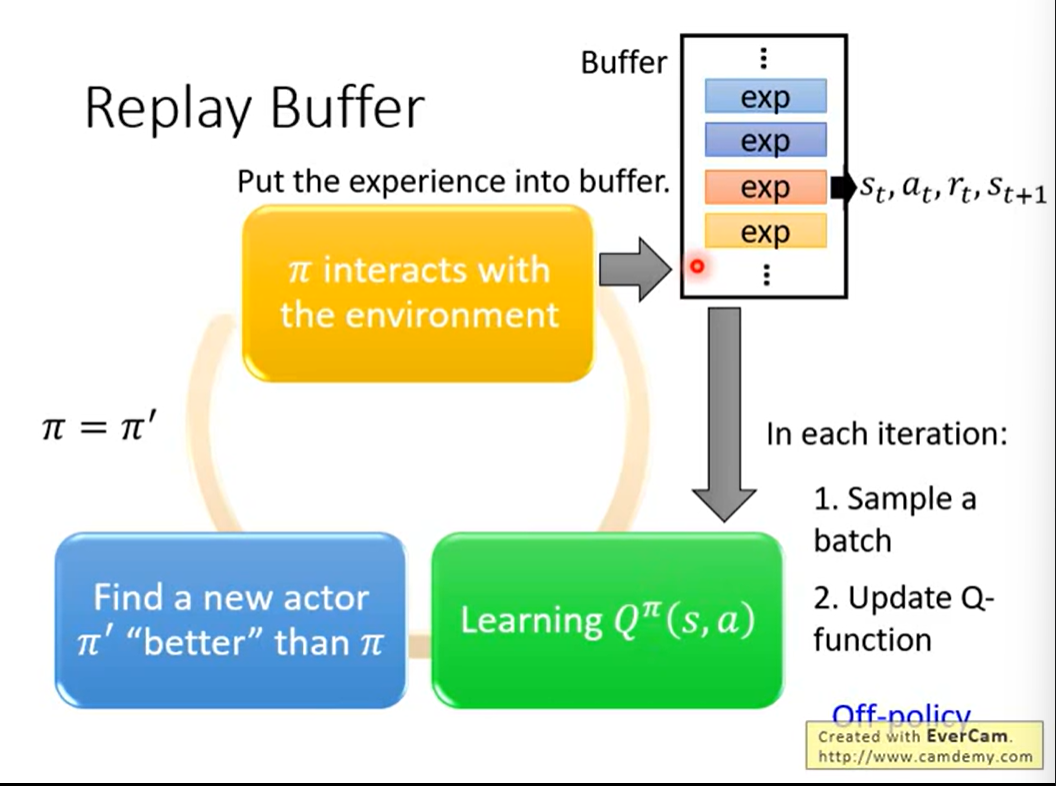
算法:

二、Q-Learning的小技巧
2.1 Double DQN
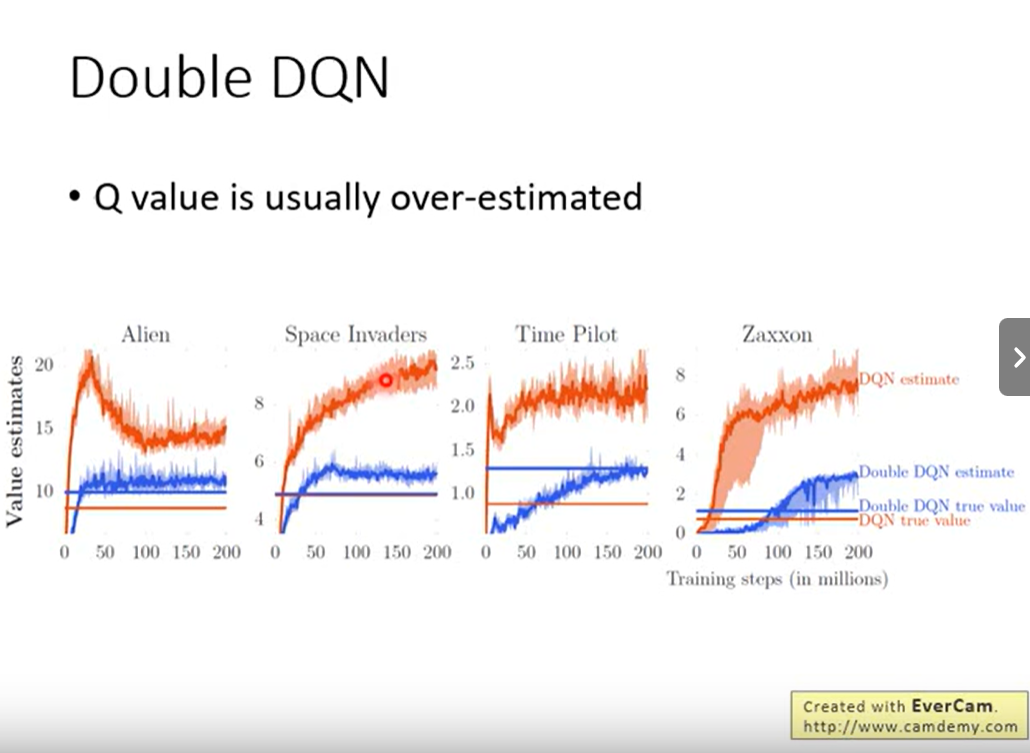
两个Q-Network。

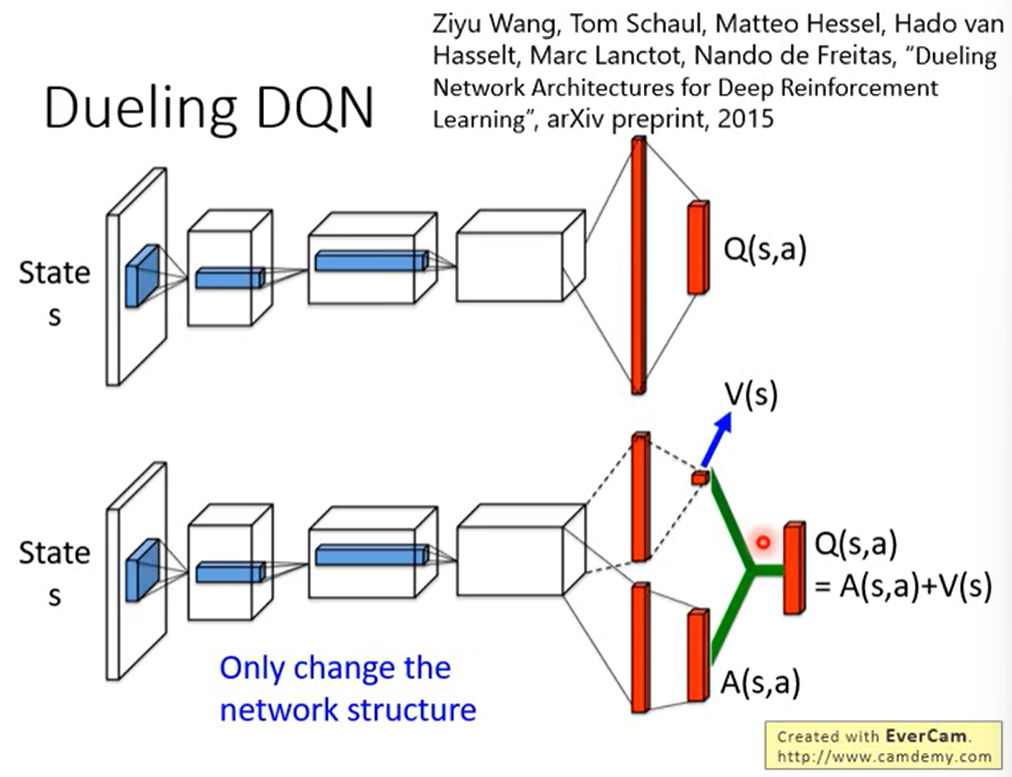
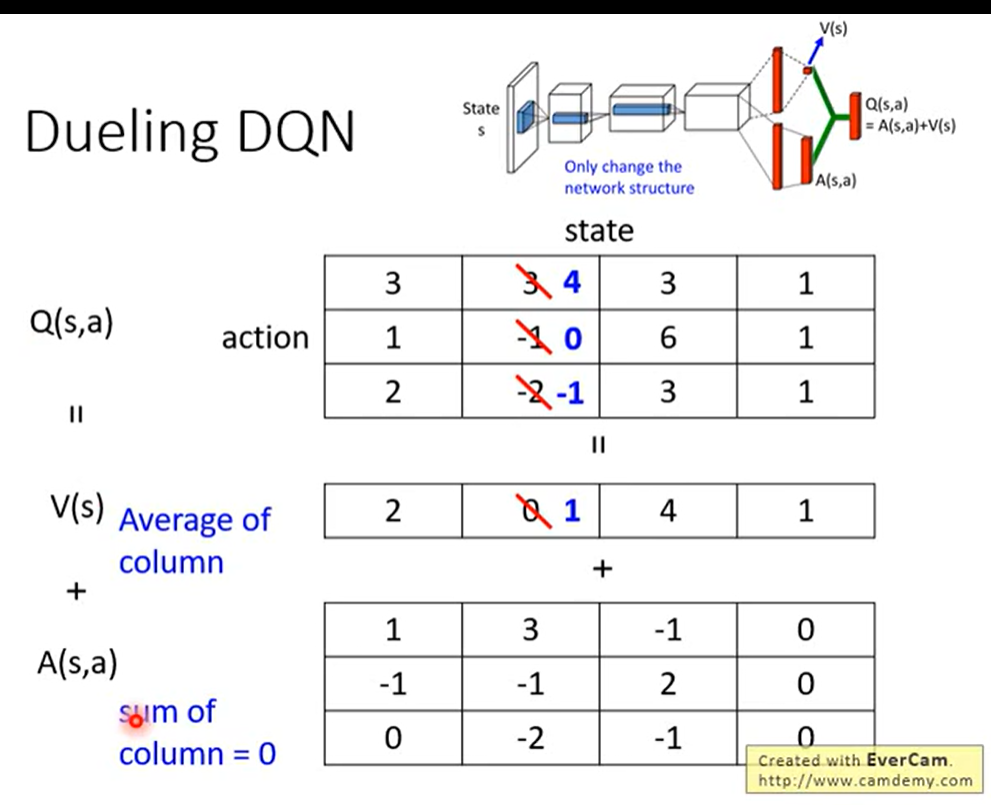
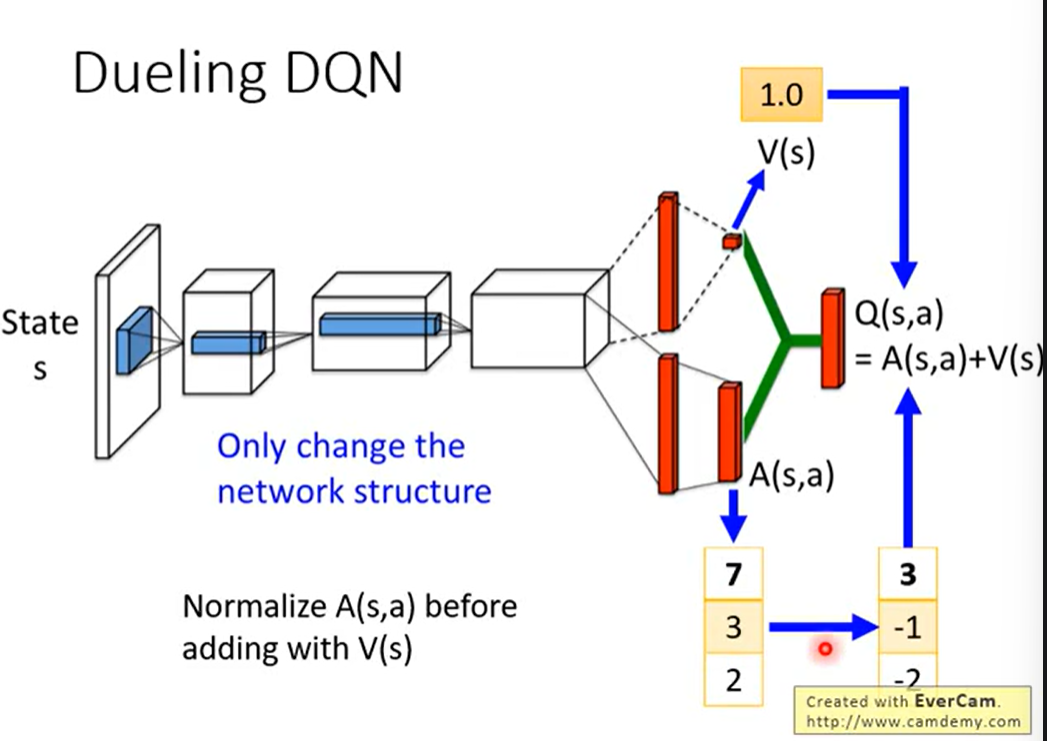
2.2 Dueling DQN
改变Network的架构。
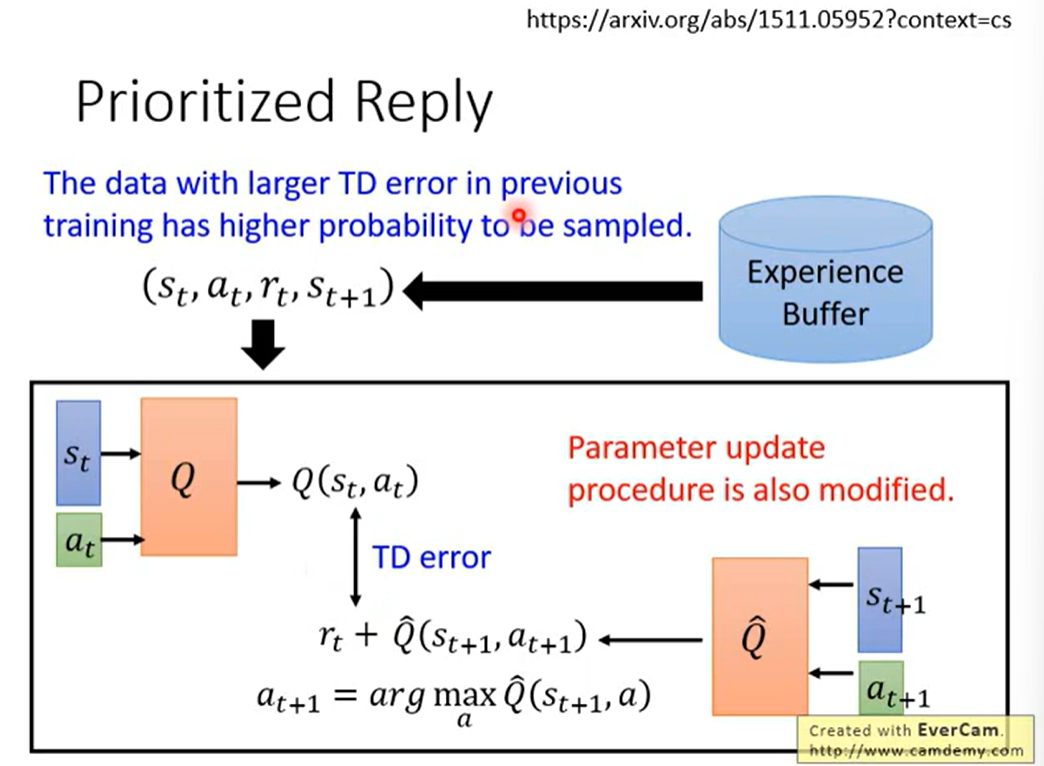
2.3 Prioritized Reply
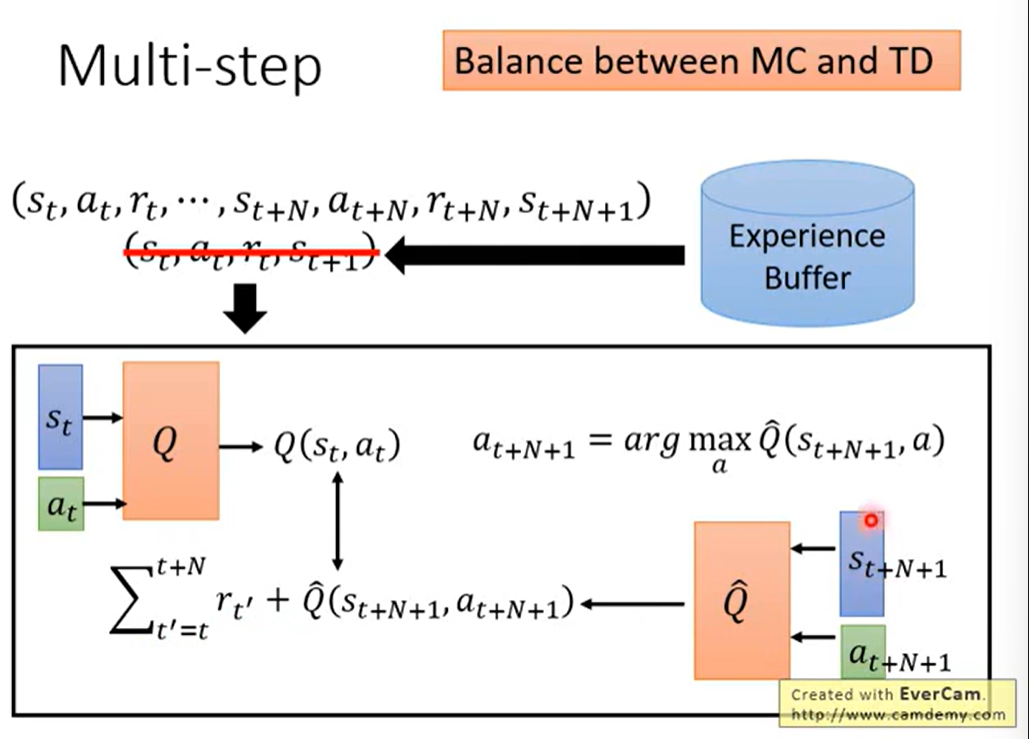
2.4 Multi-Step
2.5 Noisy Net


2.6 Distributional Q-Function
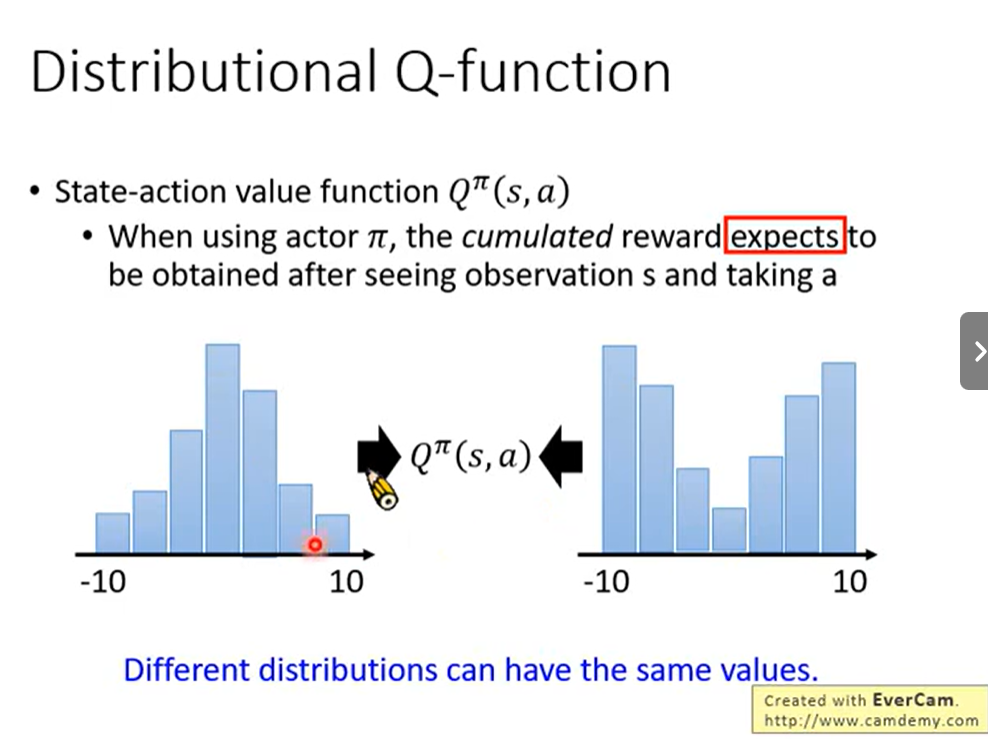
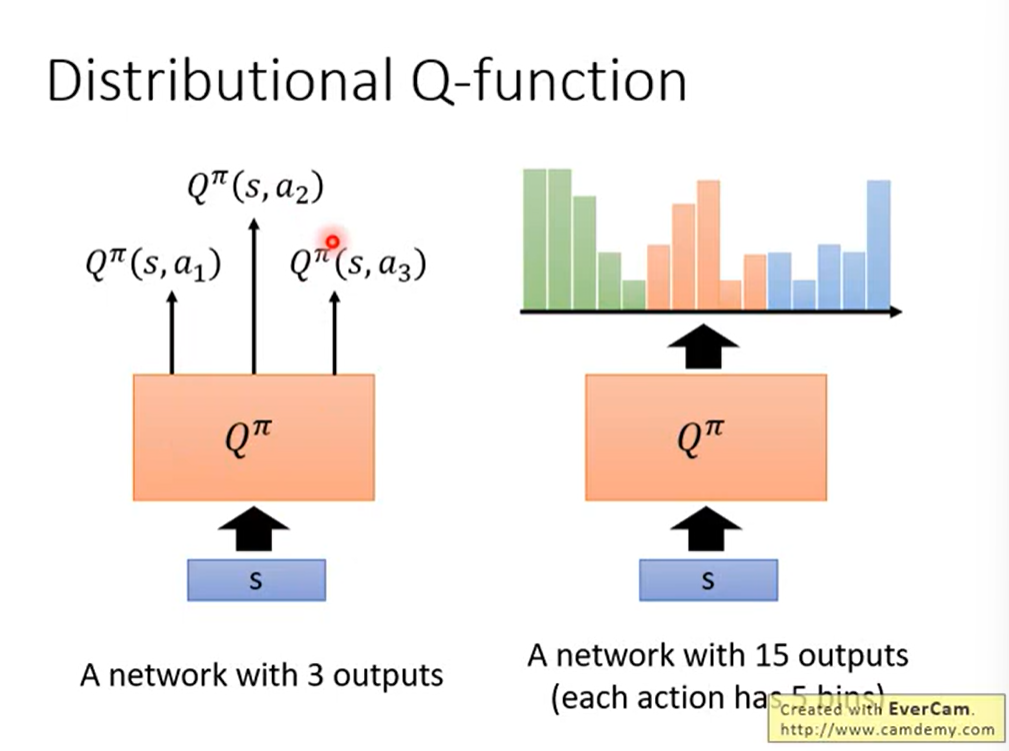
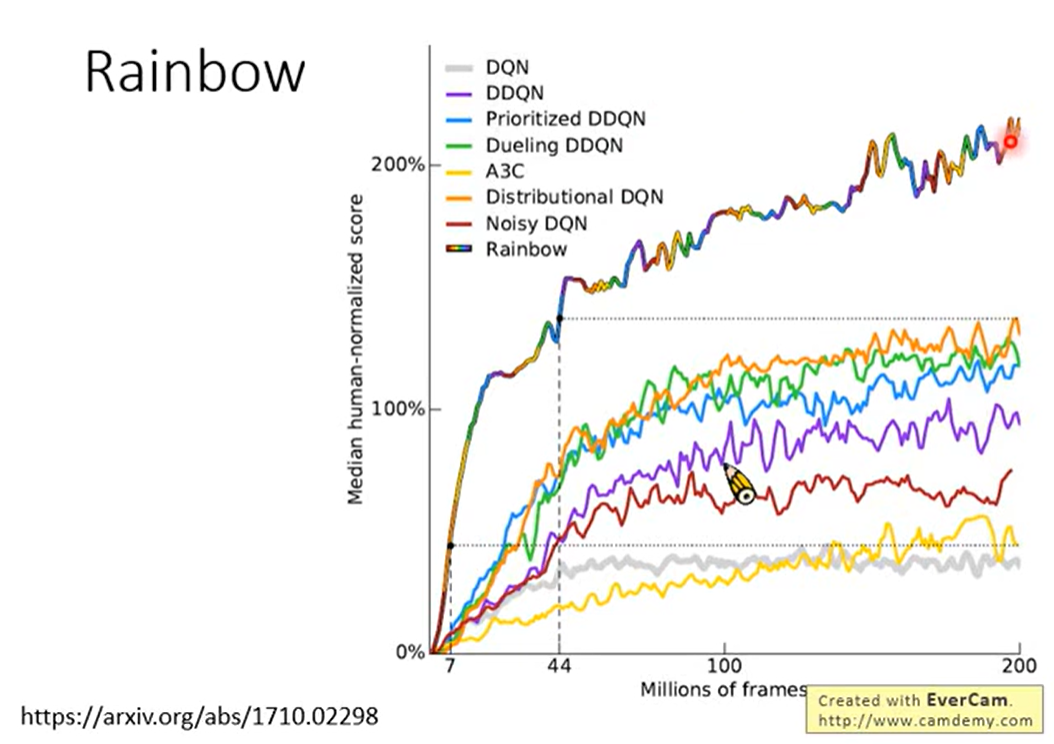
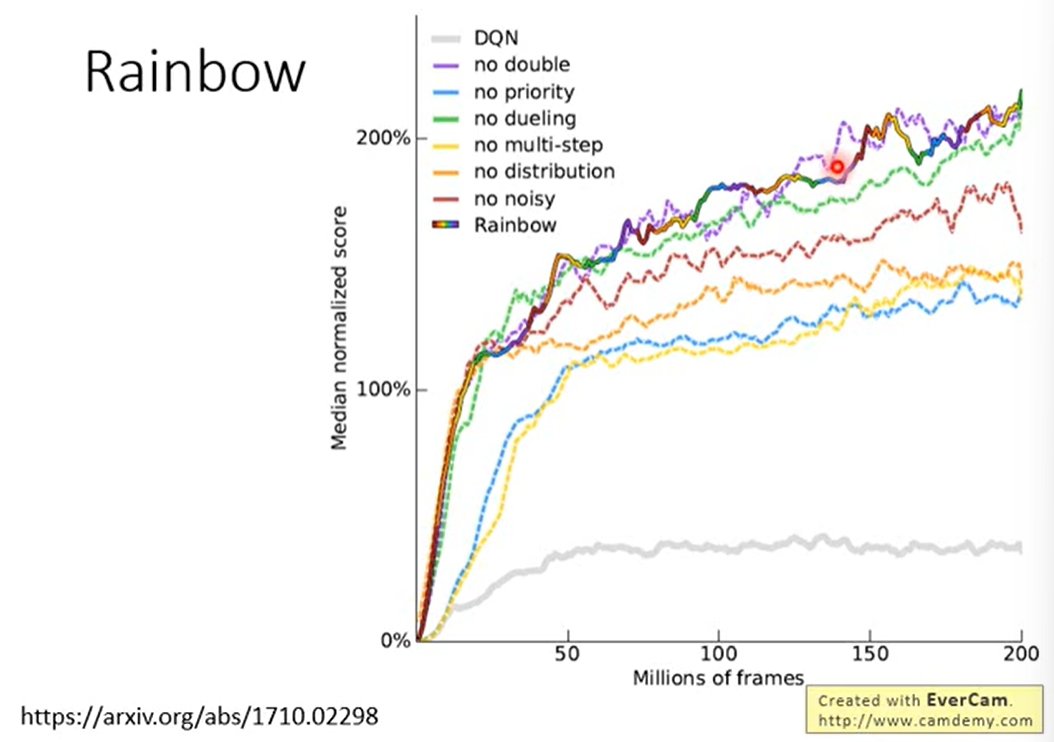
2.7 Rainbow