一、Transformer
Seq2Seq 的模型。
输出长度取决于模型。
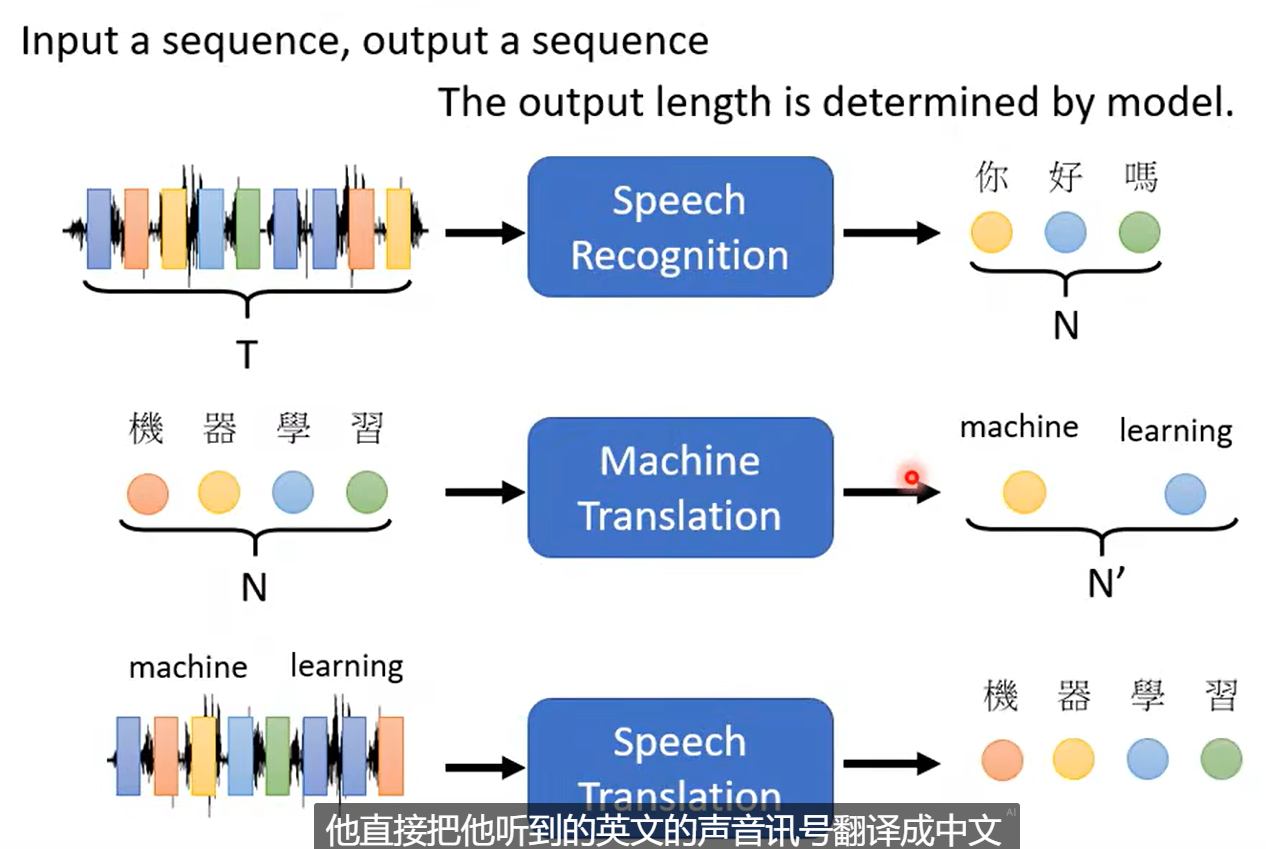
Text-to-Speech、Speech-to-Text、Chatbot。
二、EncoderDecoder
- Encoder
给定一排向量,输出一排向量。
可以使用RNN、CNN、Attention。
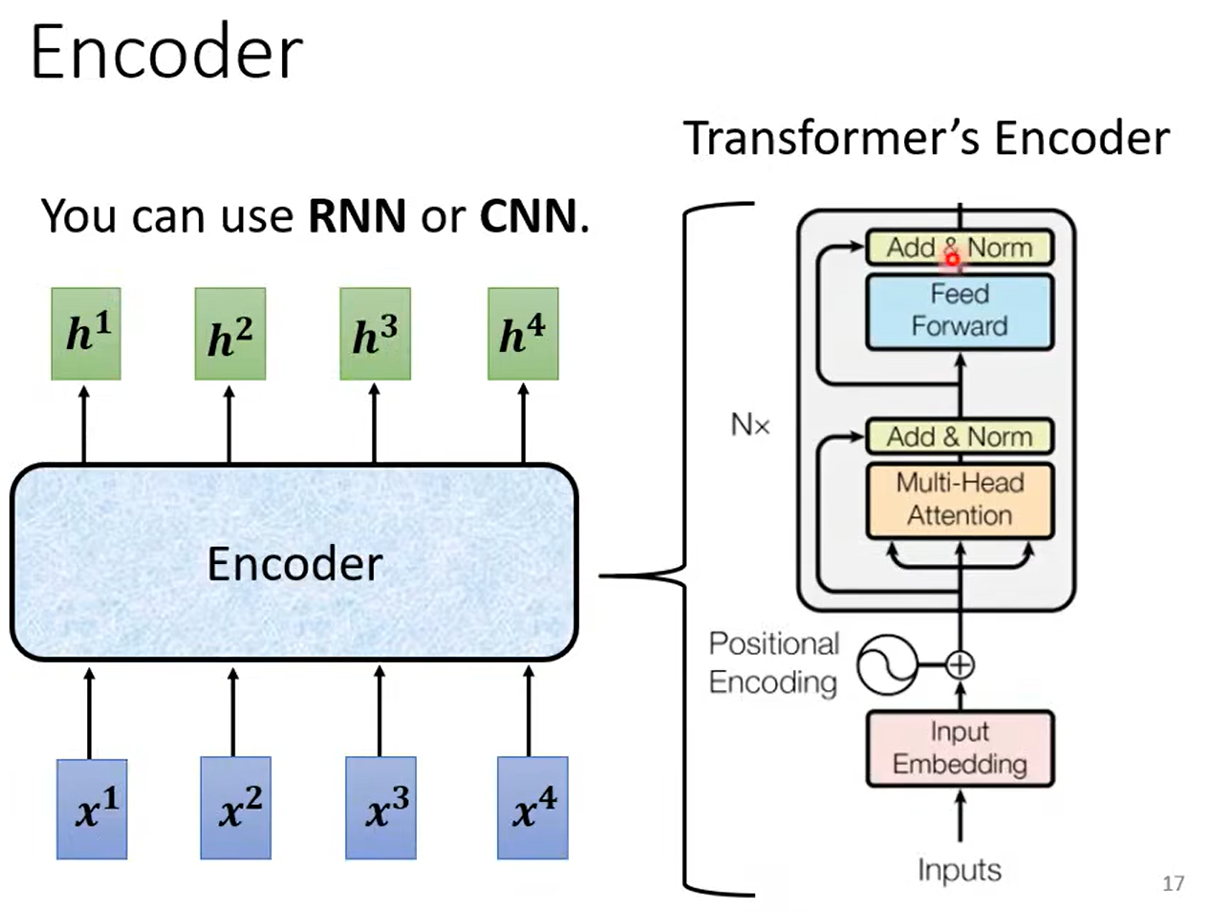
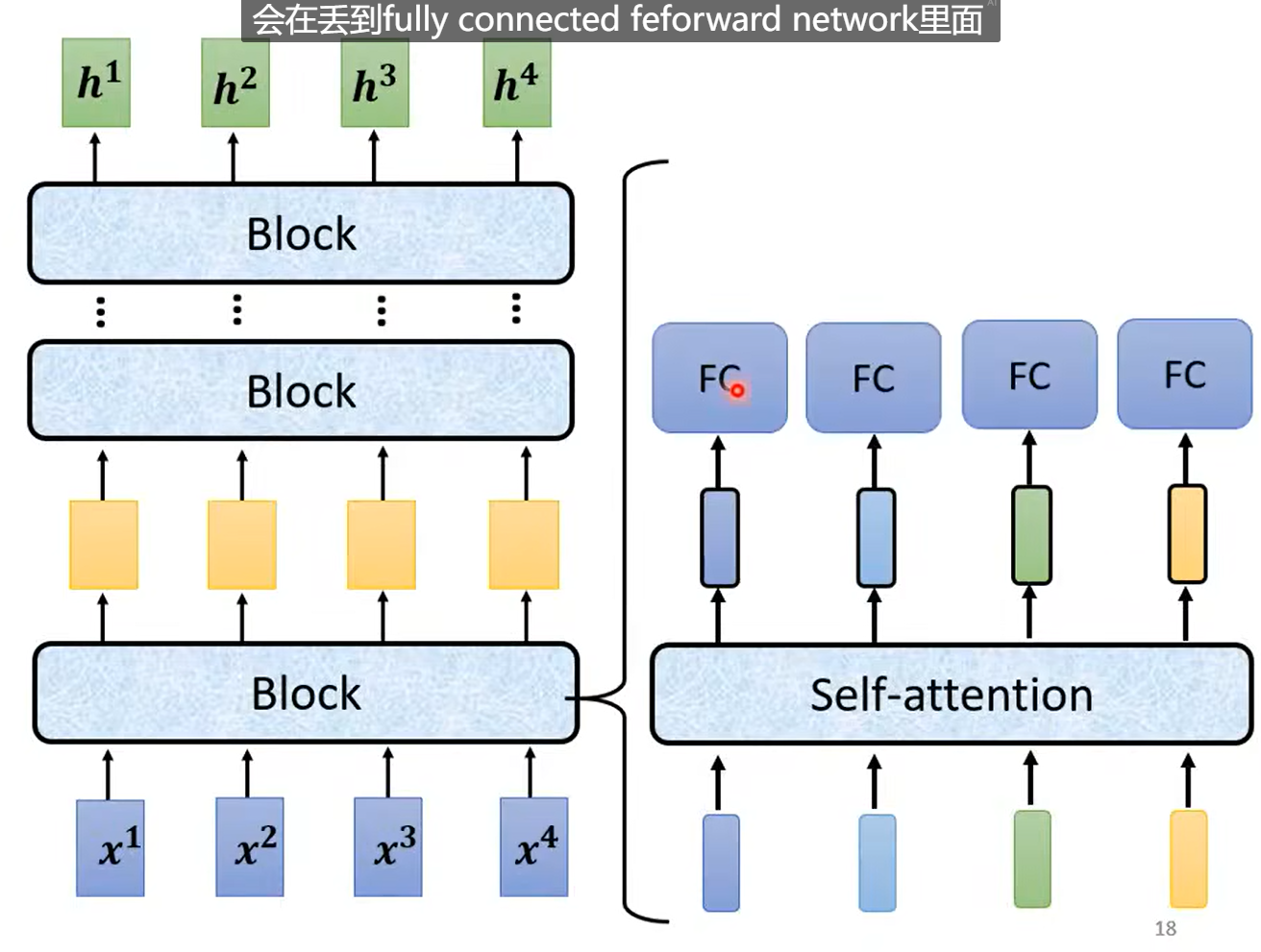
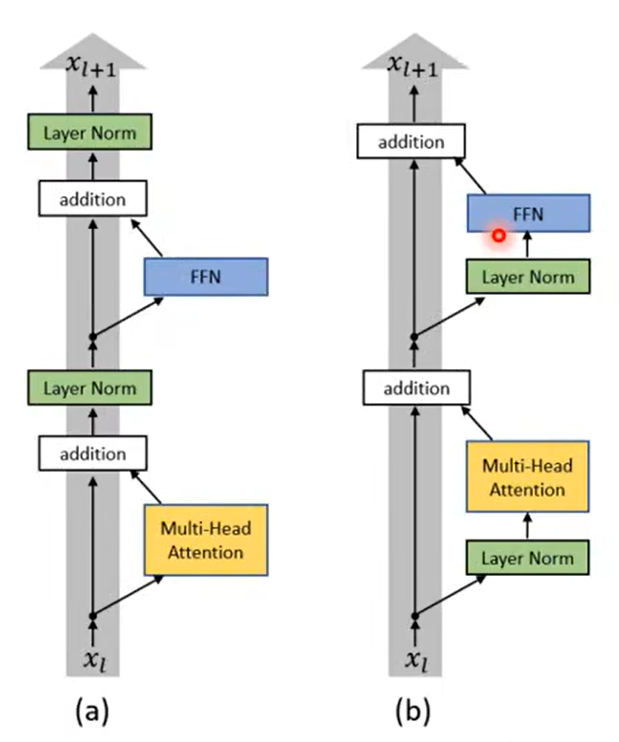
Transformer中的Block:
引入残差网络。
使用层归一化Layer Norm。(计算mean、std)
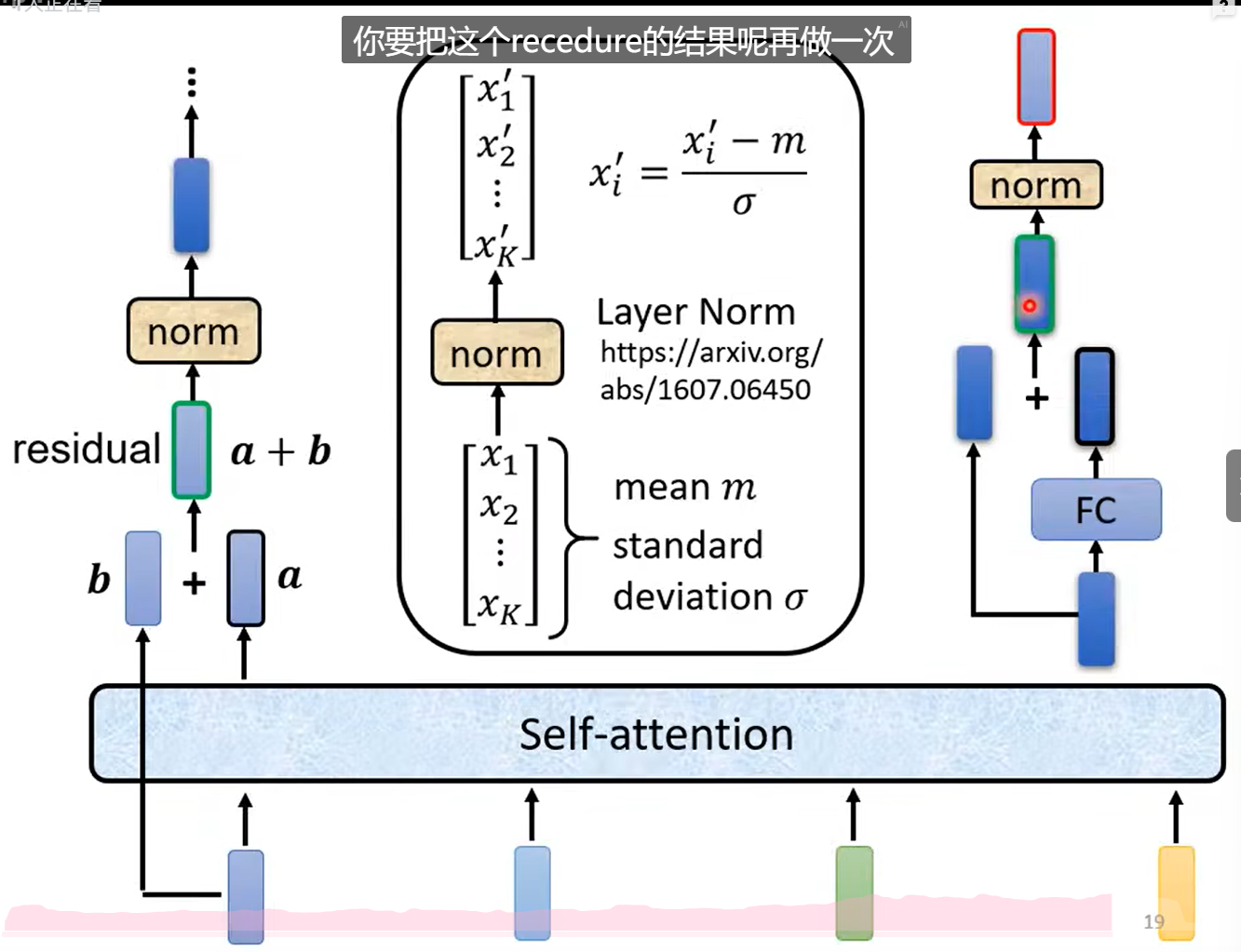
Transformer更改。
- Decoder
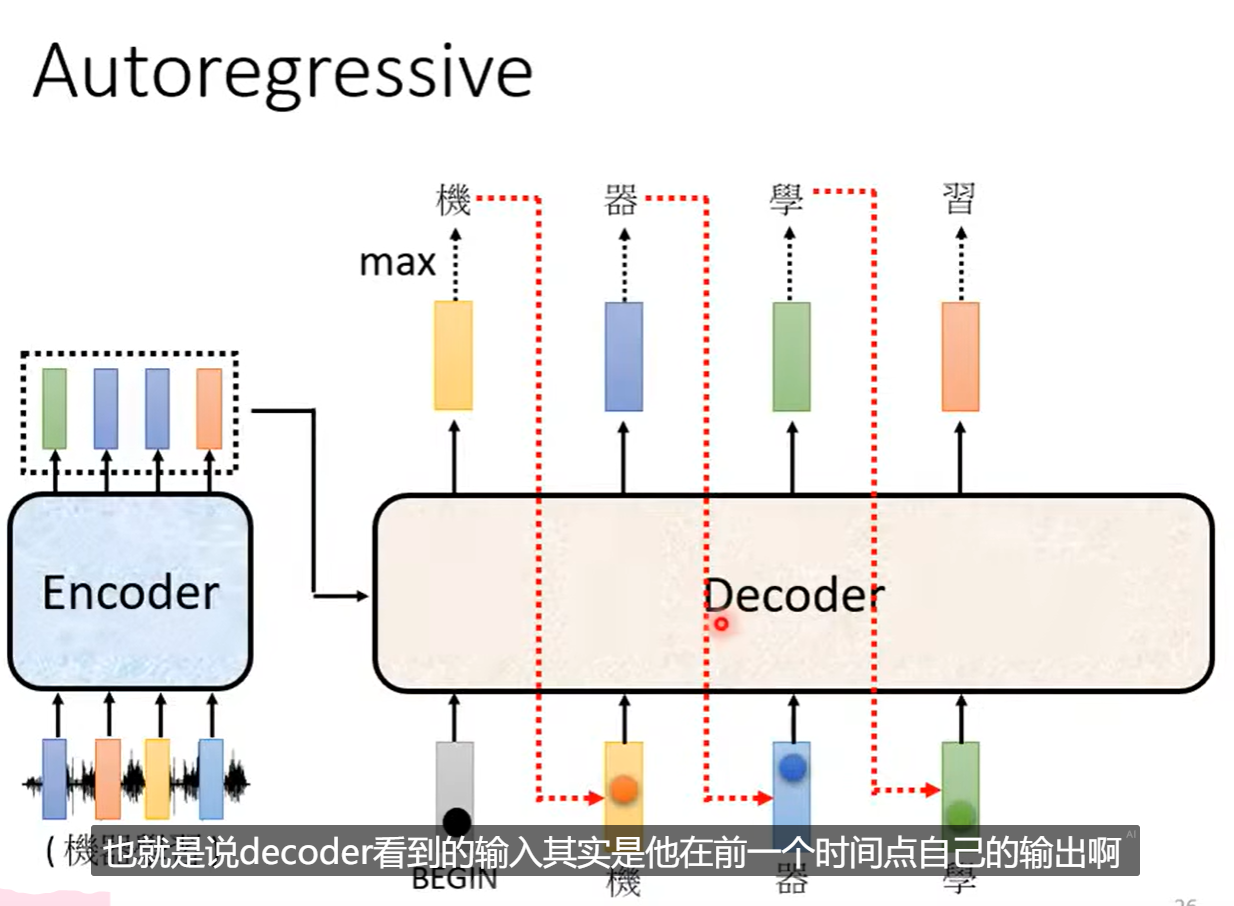
2.1 Autoregressive
从
输出文字的概率softmax。
取最高分数的文字。
接着使用预测出来的和
以此类推。
问题:当一步预测错误,后续的都会在错误之上进行预测。
Decoder:
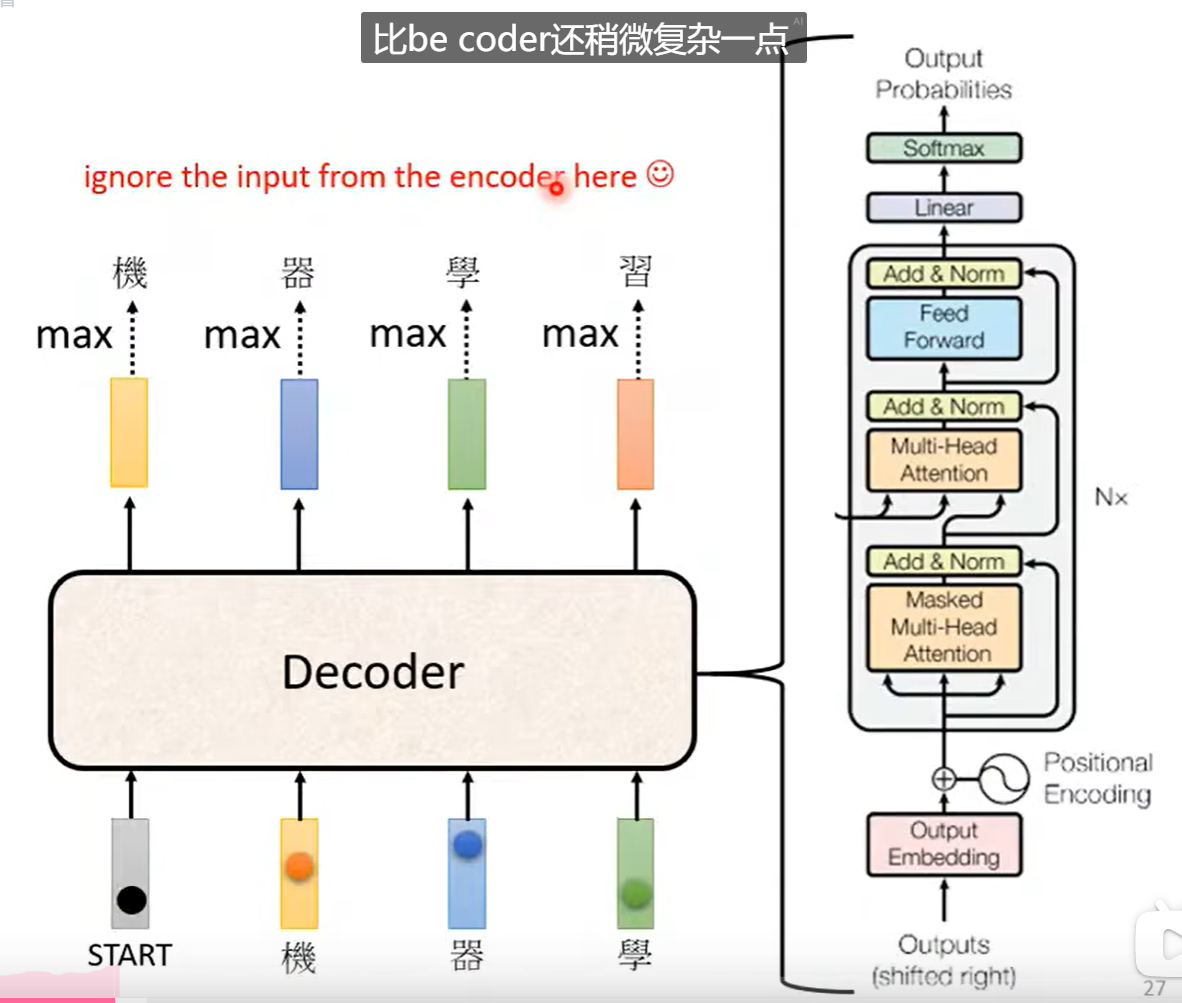
其实Encoder和Decoder差不多:
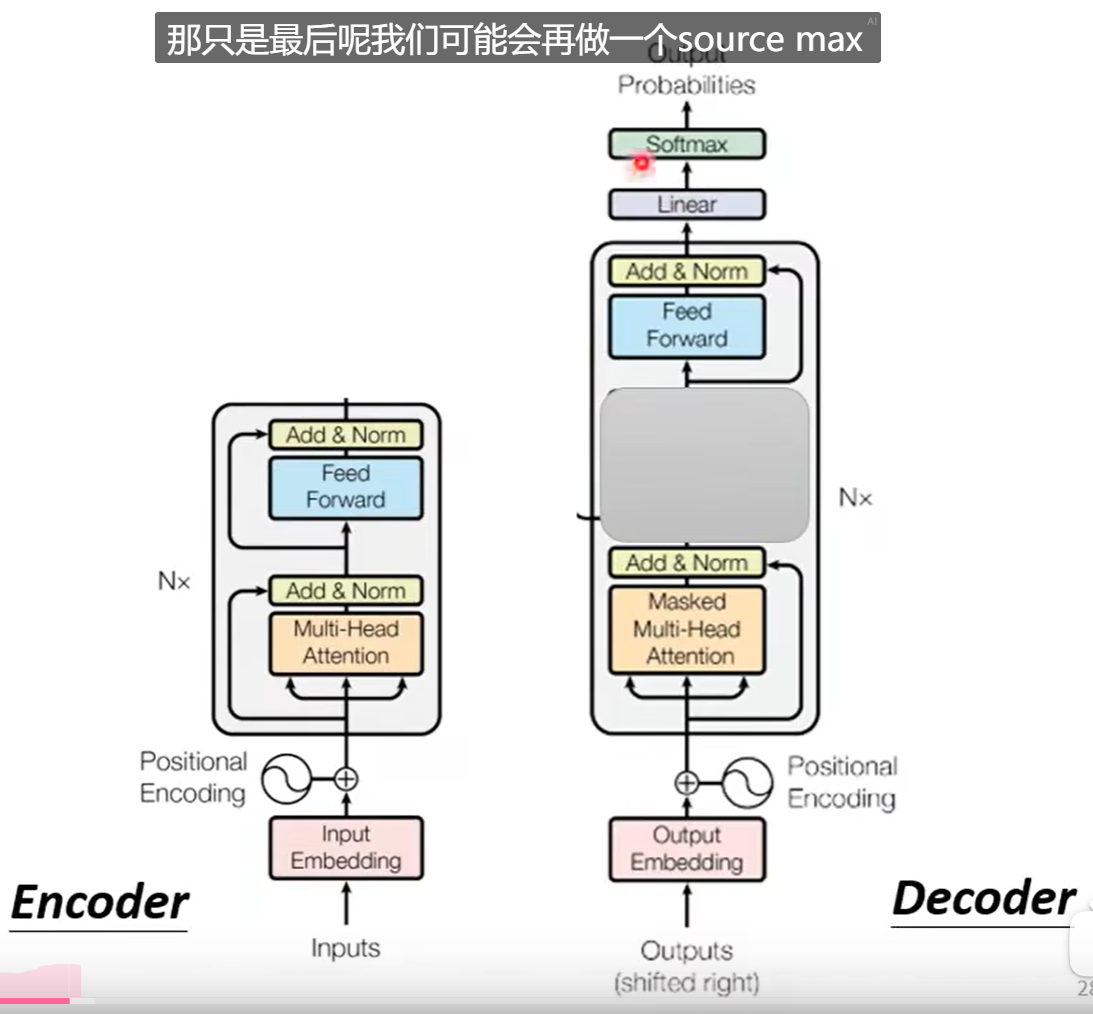
其中不一样的地方在于:
1.1 Masked 掩码机制
掩码机制就是说我们不继续考虑全局的资讯,而是专注于在此之前的资讯。
就是Masked Self-attention
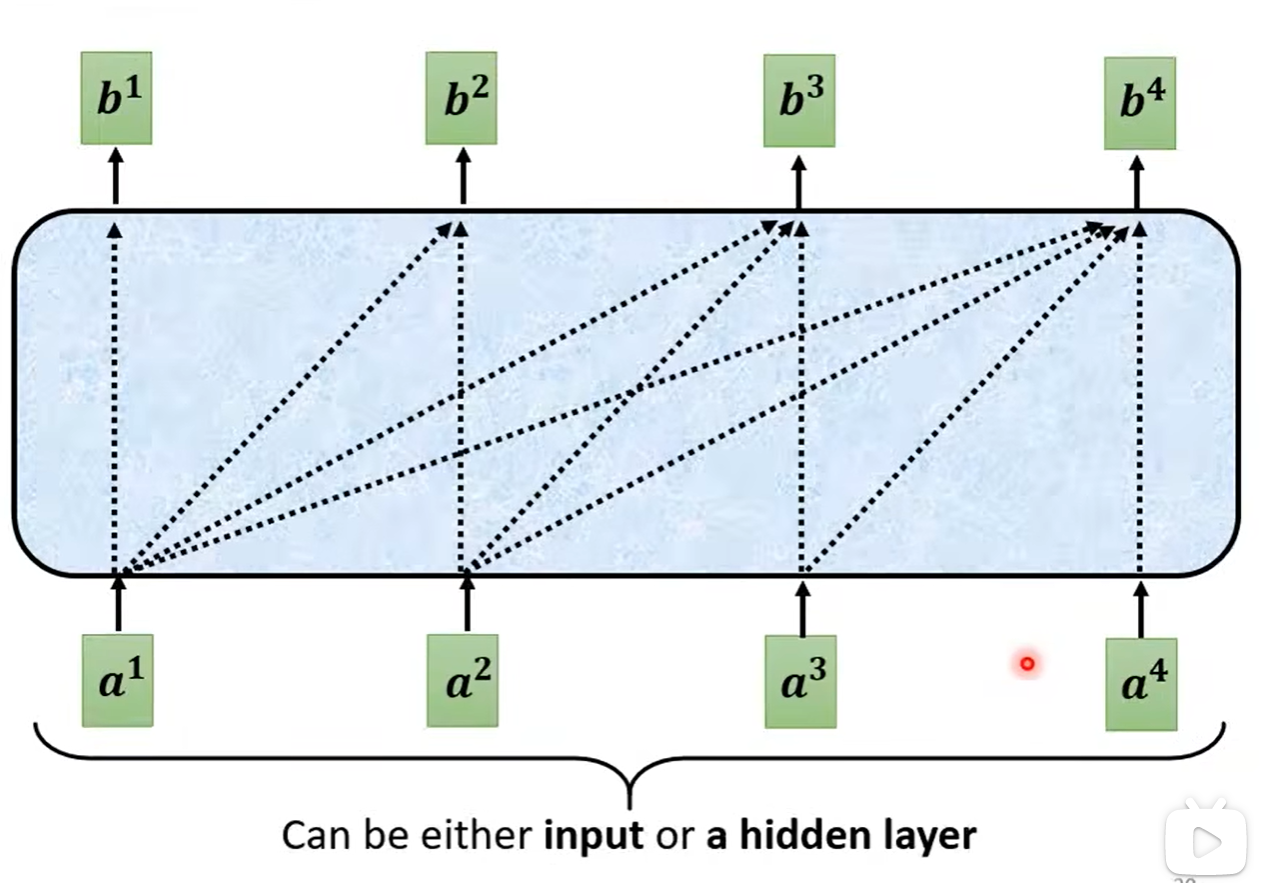
输出的长度是不定的。
输出
2.2 Non Autoregressive(NAT)
一次产生整个句子。
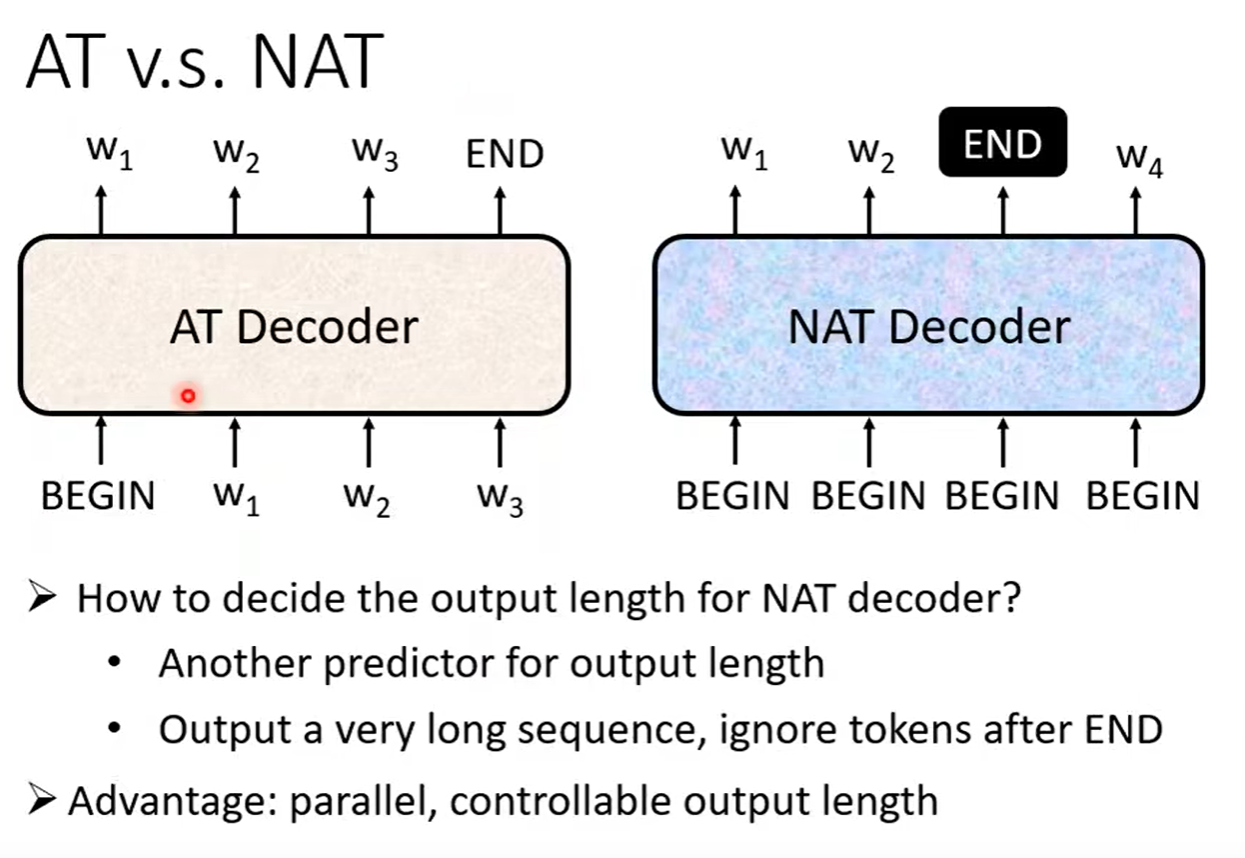
优点:平行化、控制输出的长度。
缺点:表现不好
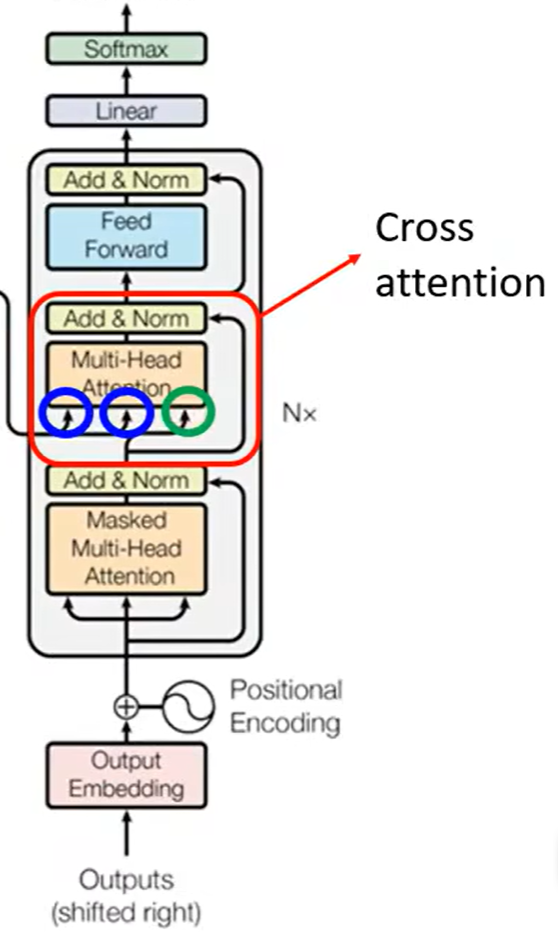
- Transformer
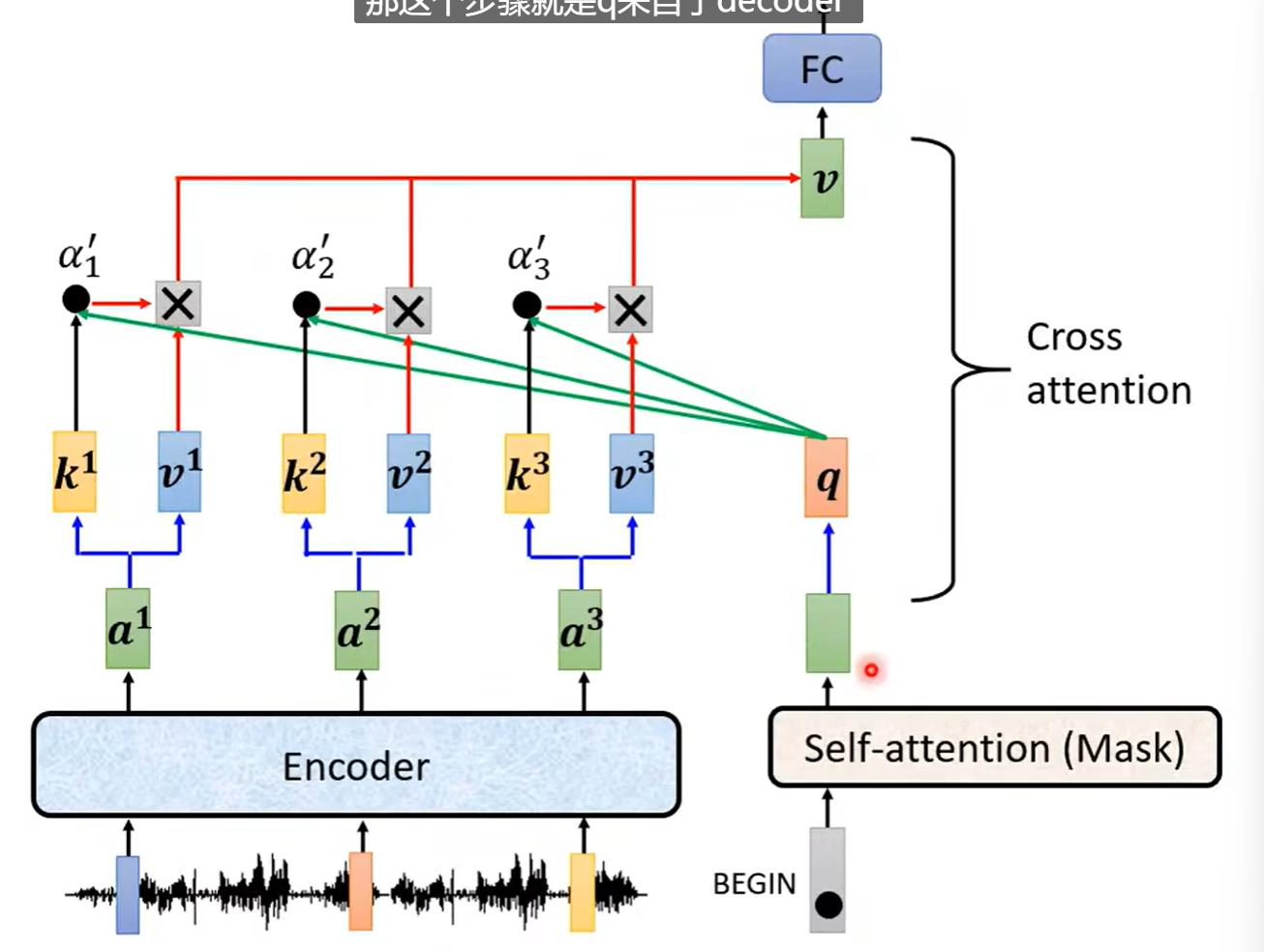
Decoder和Encoder的交互。
通过交叉注意力。
Decoder以
进行掩码自注意力得到输出。
接着乘以q查询矩阵、k键矩阵。
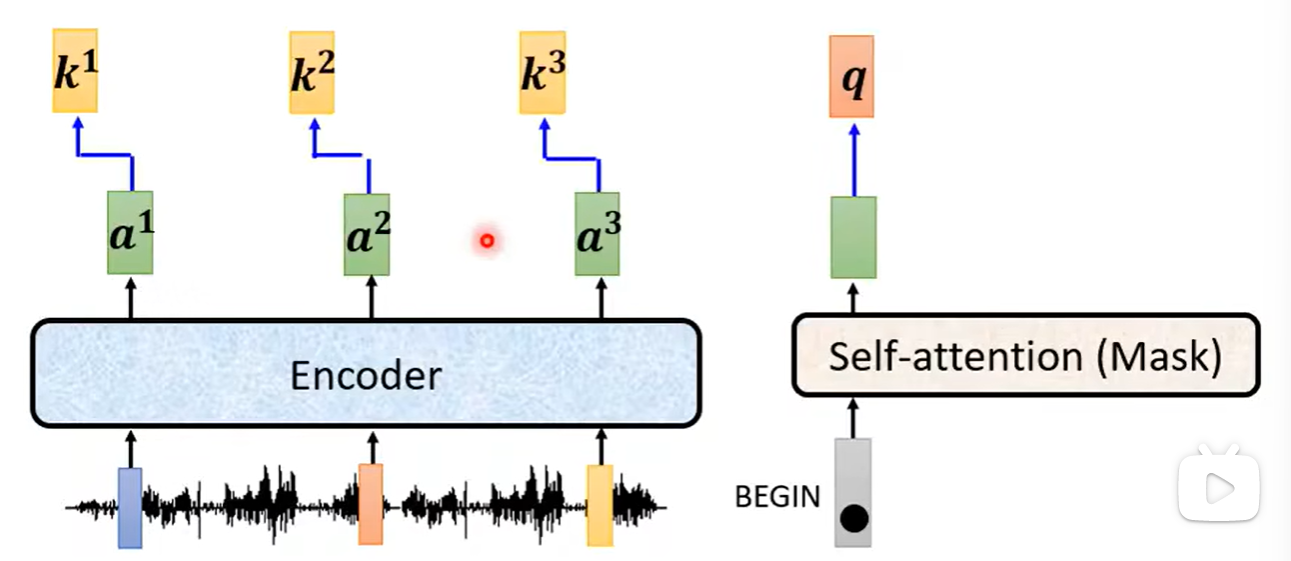
计算注意力分数。
接着乘以v值矩阵。
三、训练
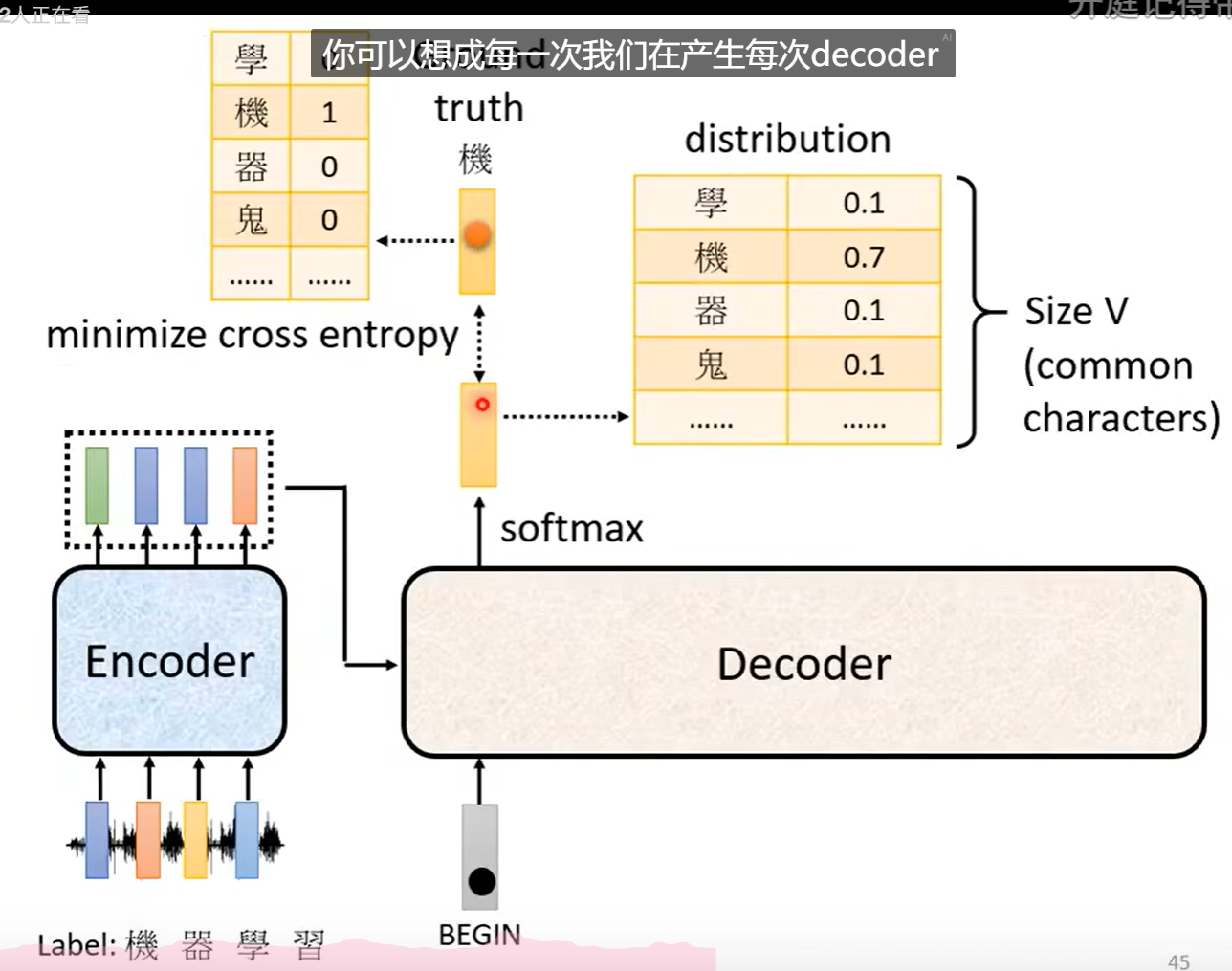
计算交叉熵损失。
再训练的时候会给予正确的答案。这样的操作叫做强制教学Teacher Forcing。
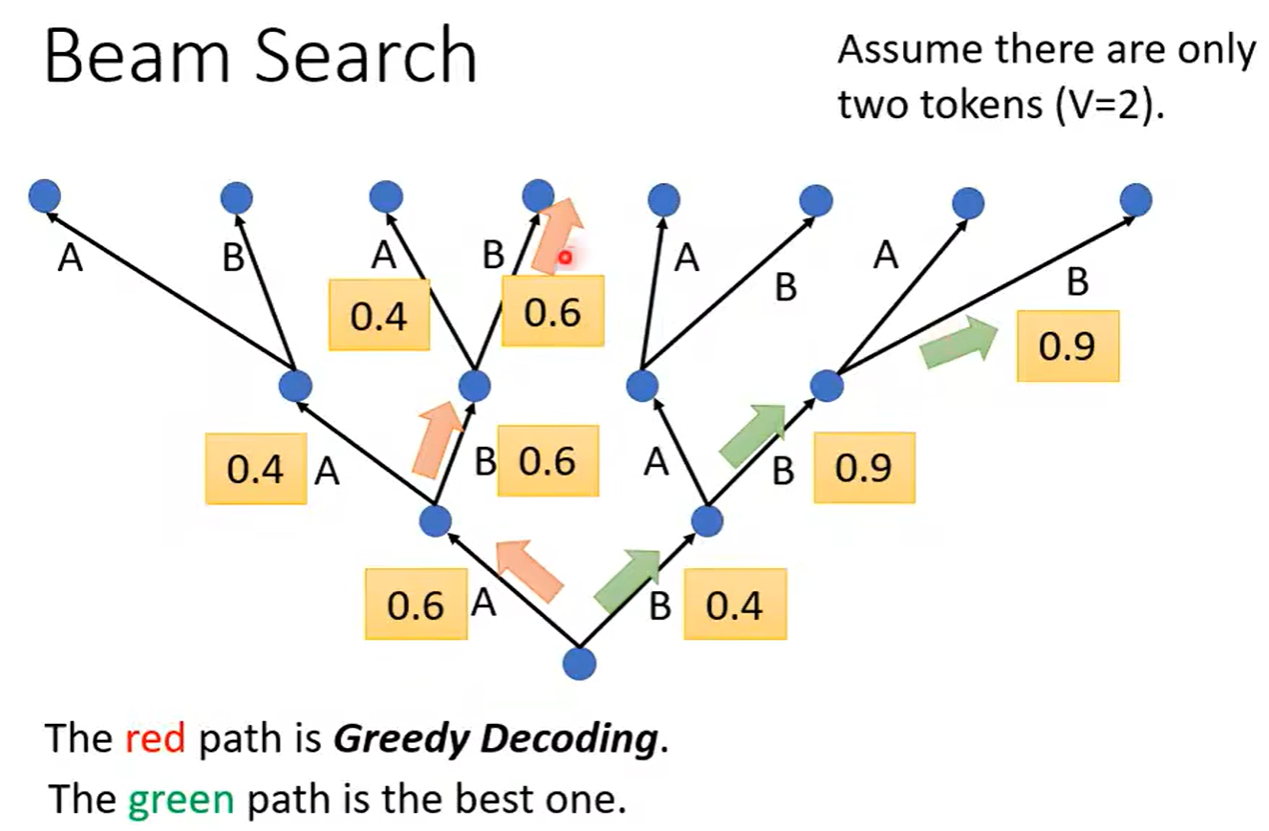
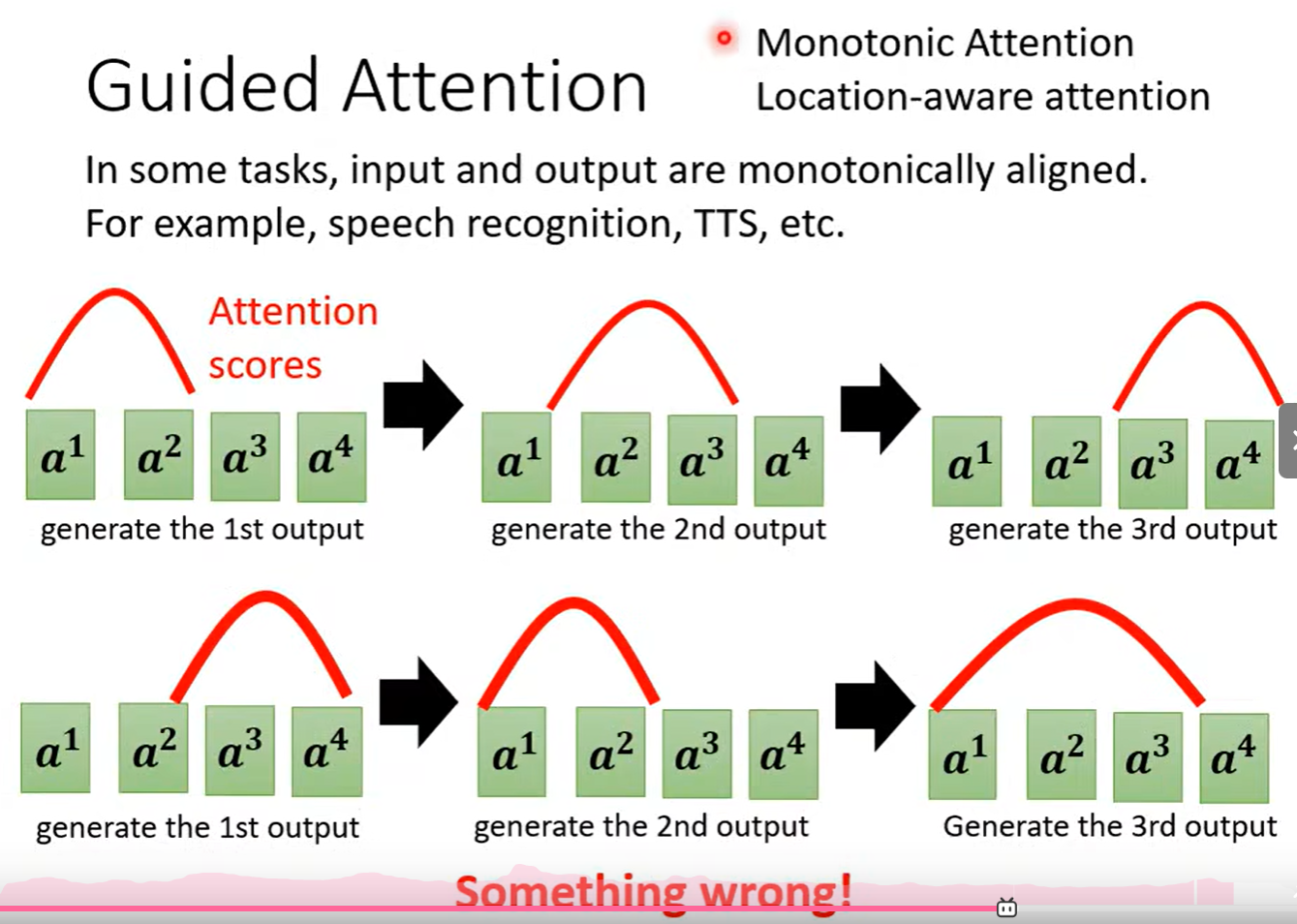
四、束搜索、Guided Attention
五、评估
Bleu分数。
当我们不知道如何优化的时候,我们使用强化学习RL。
曝光偏差:
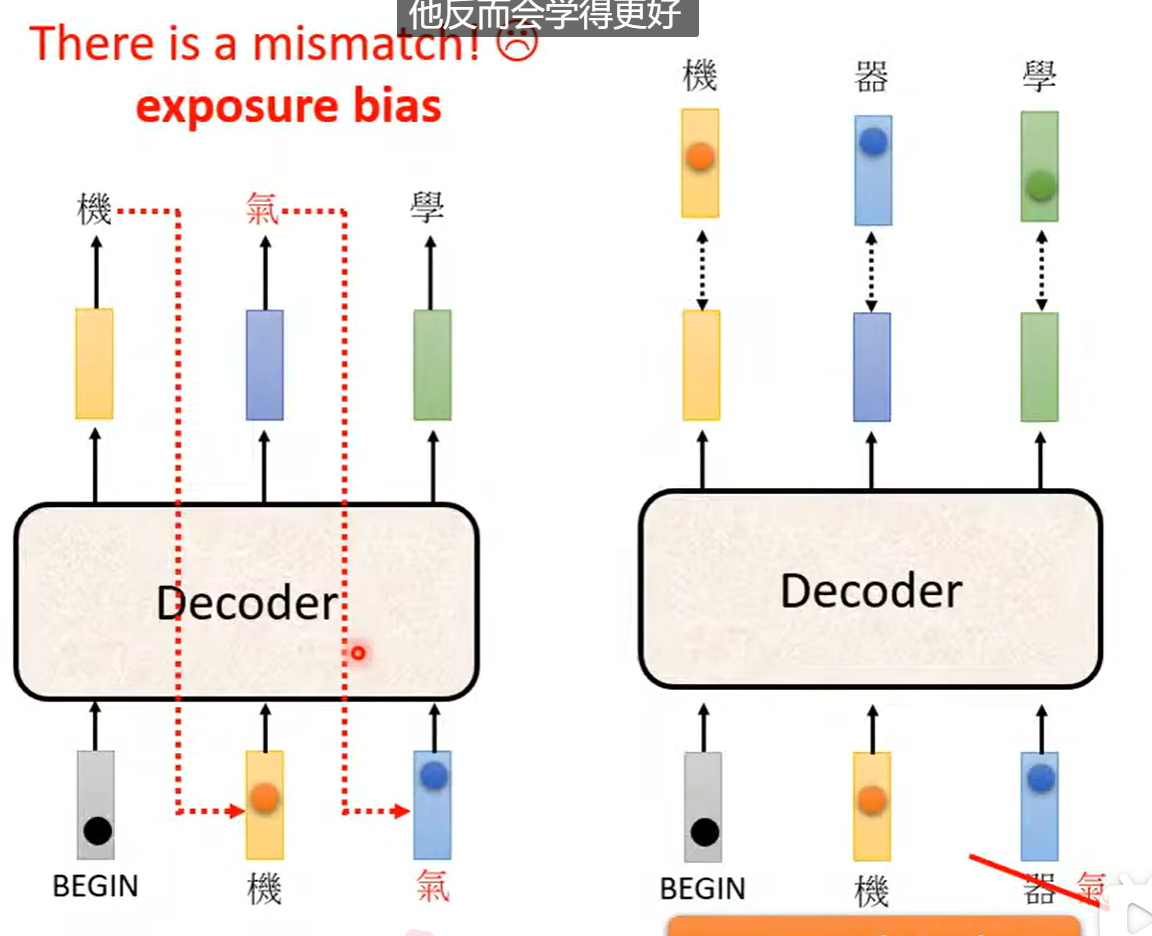
训练的时候又不要全部给定正确的,加入部分的错误。
Scheduled Sampling。
Encoder可以做并行。