一、模型家族
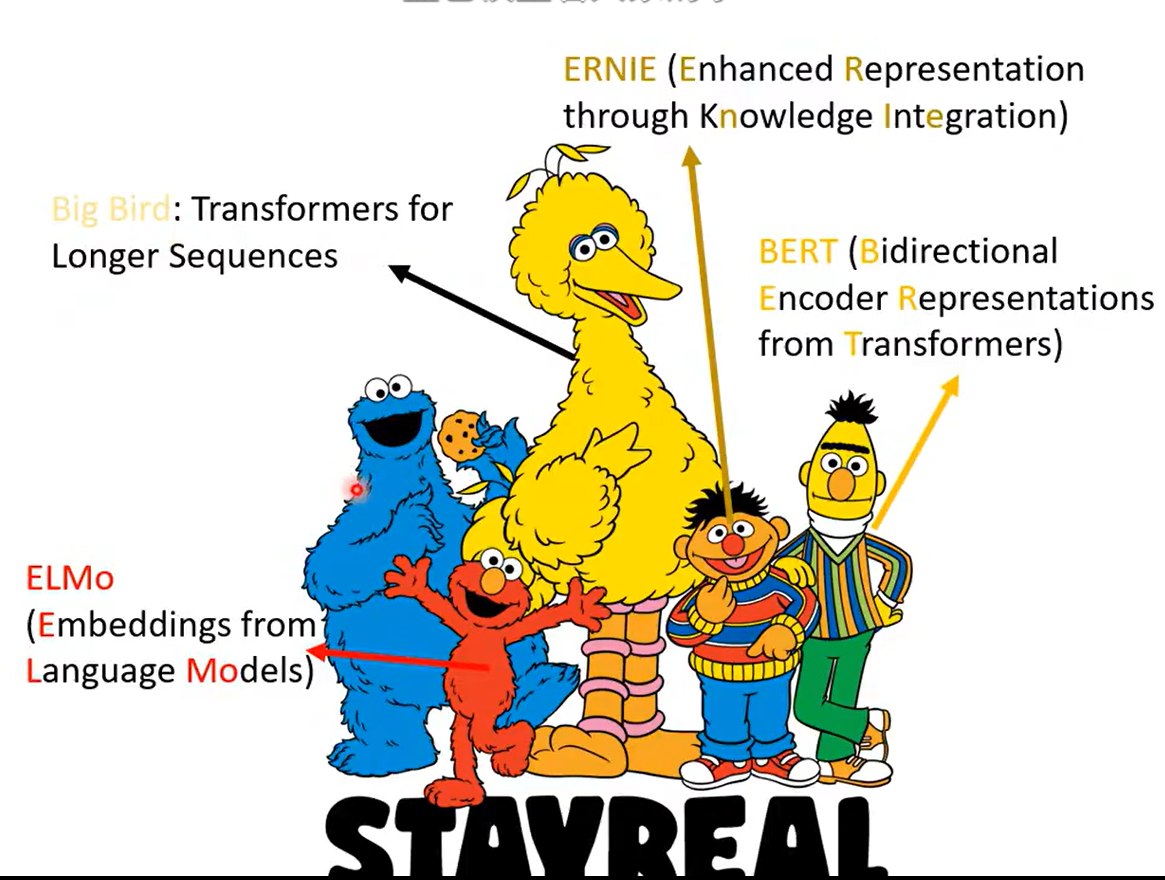
巨大的参数:


二、自监督学习
监督学习的做法:
我们是有标签的
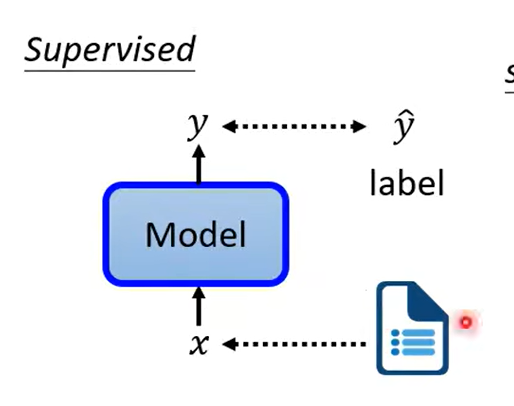
而自监督学习:
在没有标签的情况下,自己做标注。
将原本数据分成两部分,一部分做输入,一部分作为标签。
三、BERT
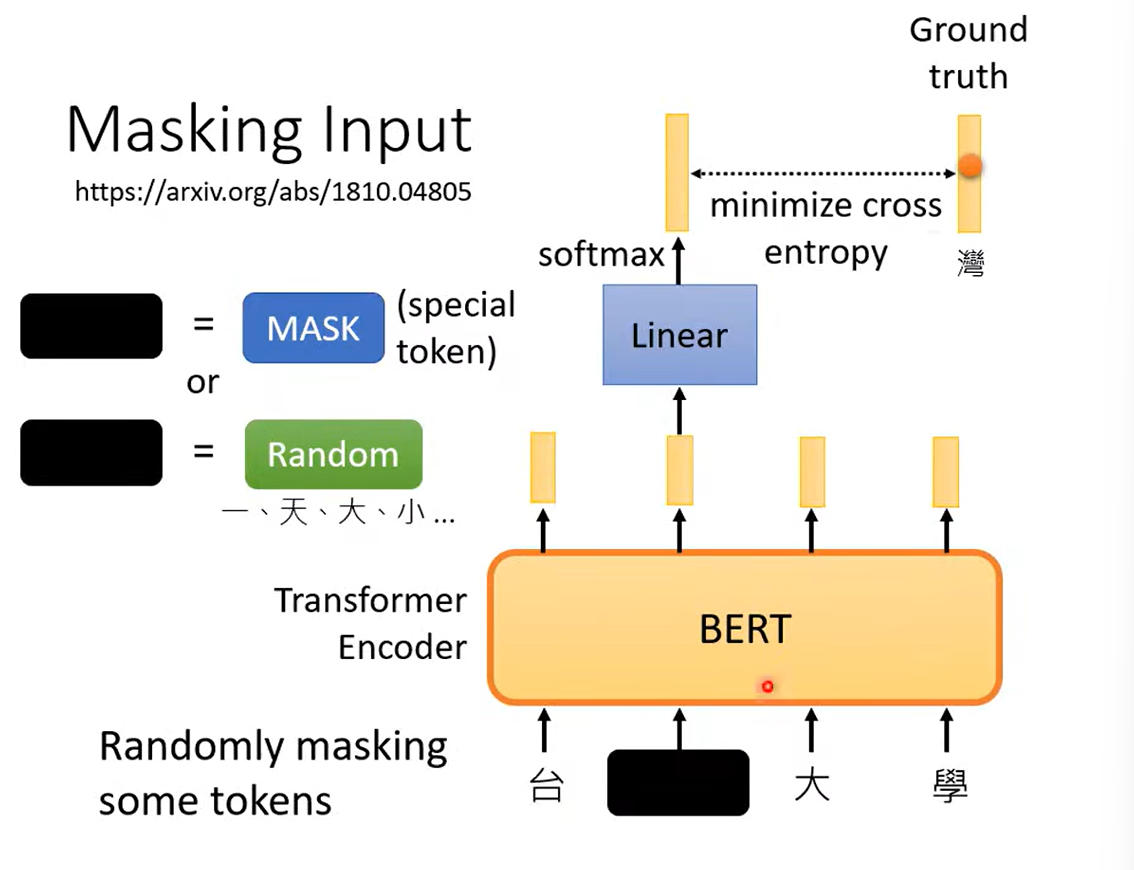
BERT就是Transformer的Encoder。
输入一个Seq。
然后将输入随机掩盖。
指的是:1. MASK 2.随机
学会做填空题。
预测两个句子是否相接。
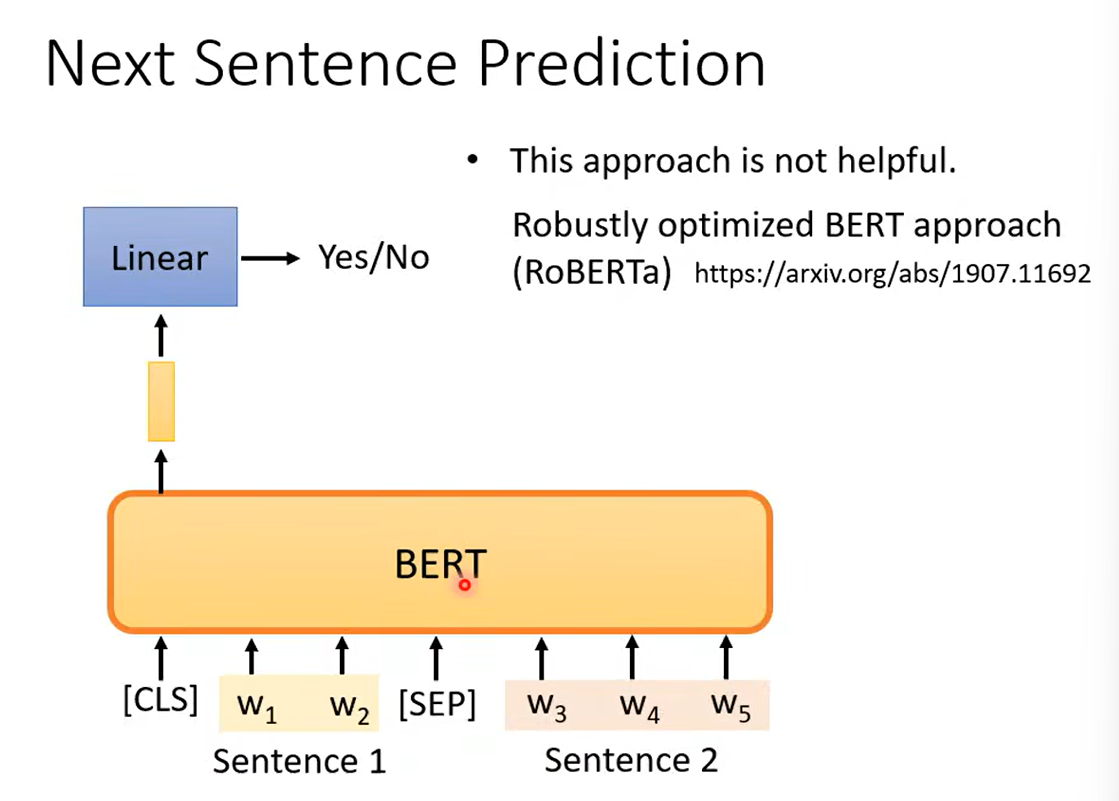
对BERT进行微调,满足下游任务:
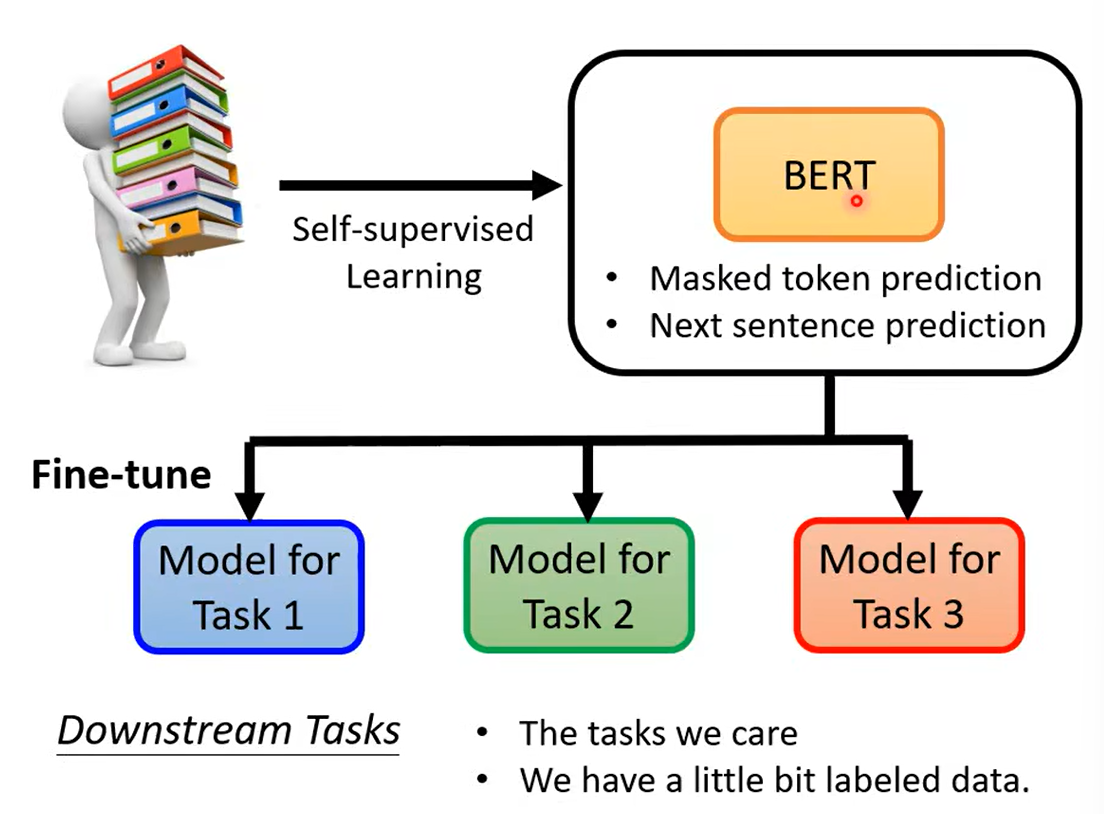
下游任务:

半监督学习说的是,我们BERT的训练是(自监督学习)无监督的学习,而做下游任务的时候是监督学习。
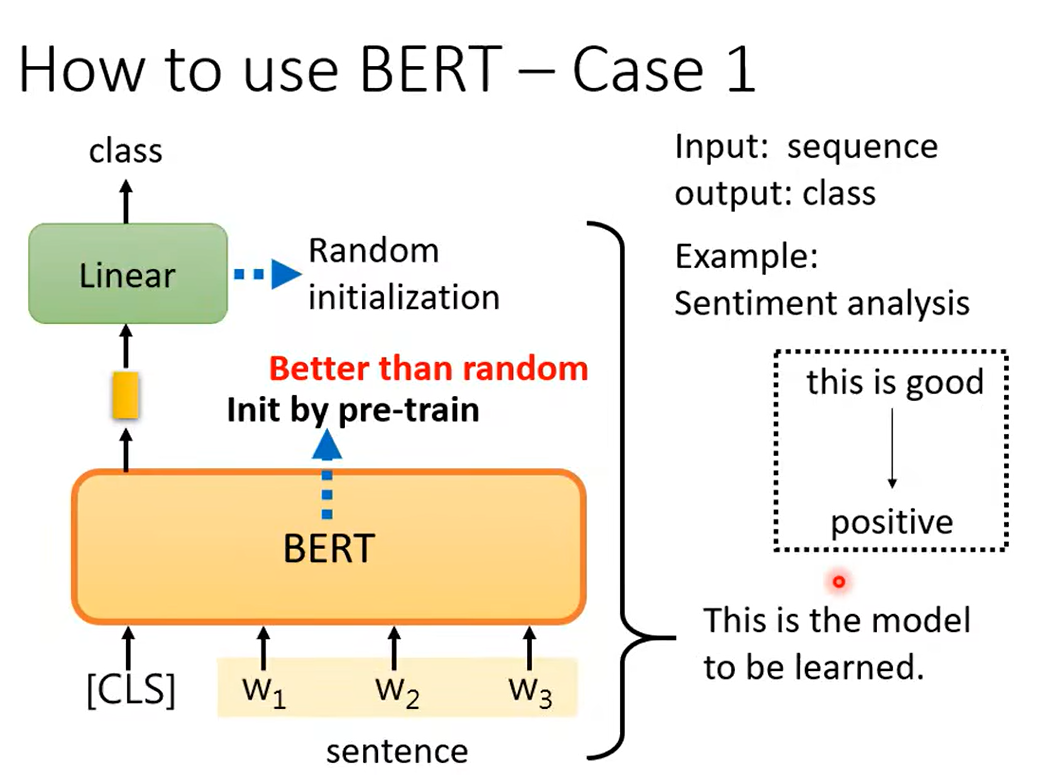
情感分类
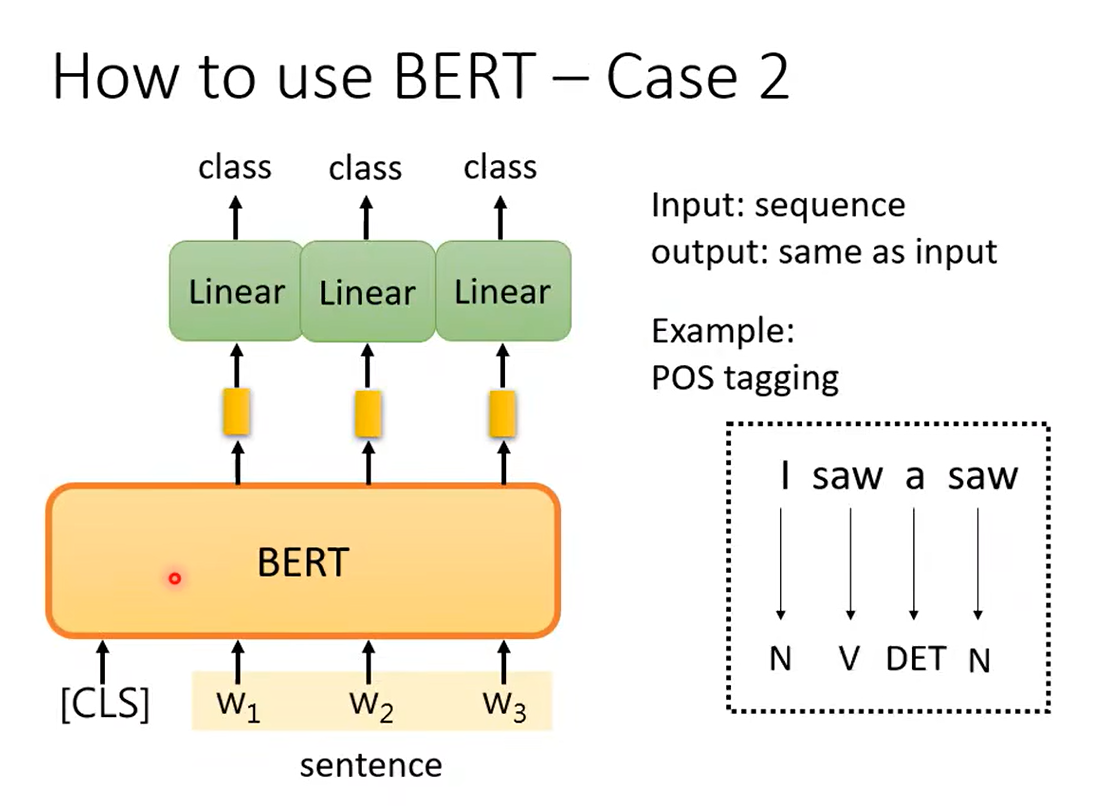
词性标注
前提、假设推断
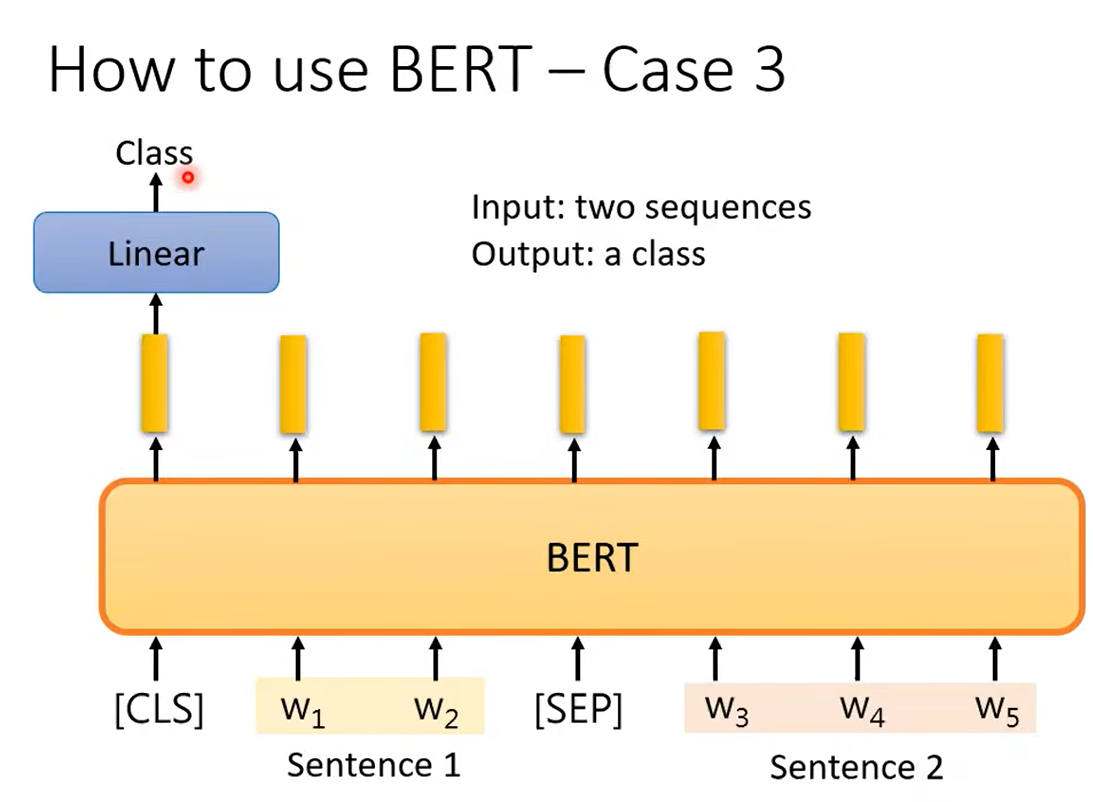
问答
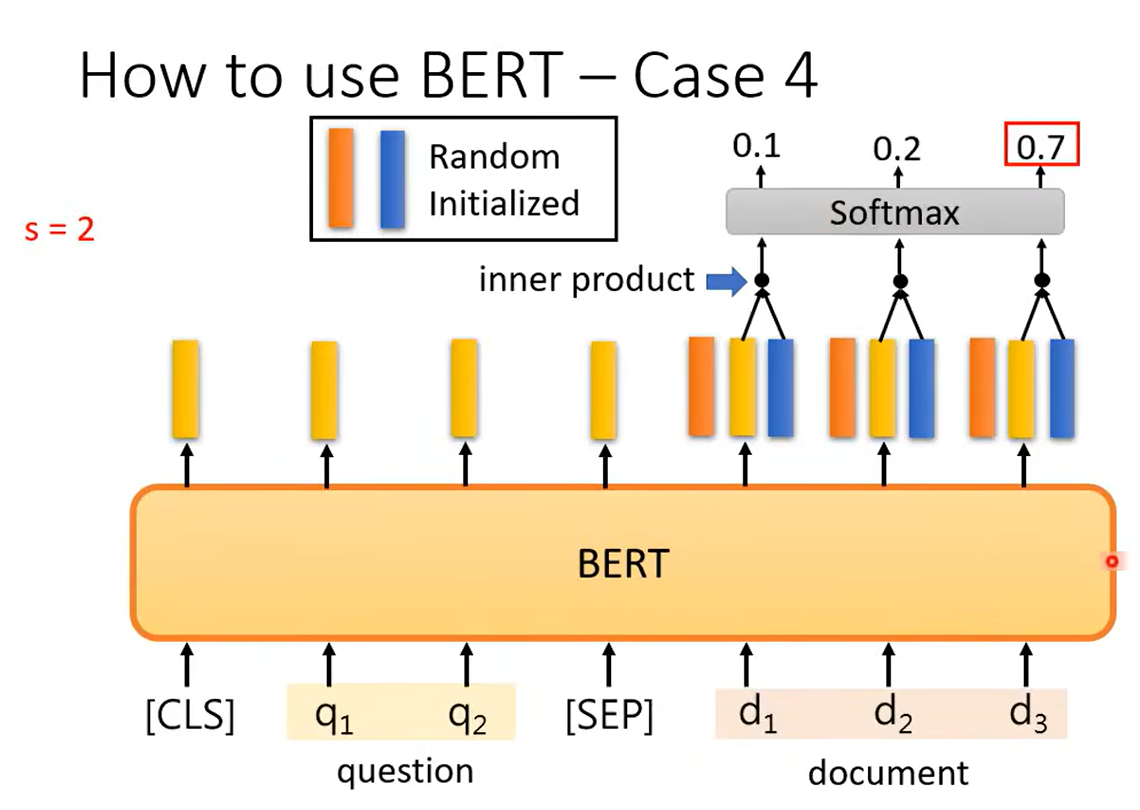
Seq2Seq
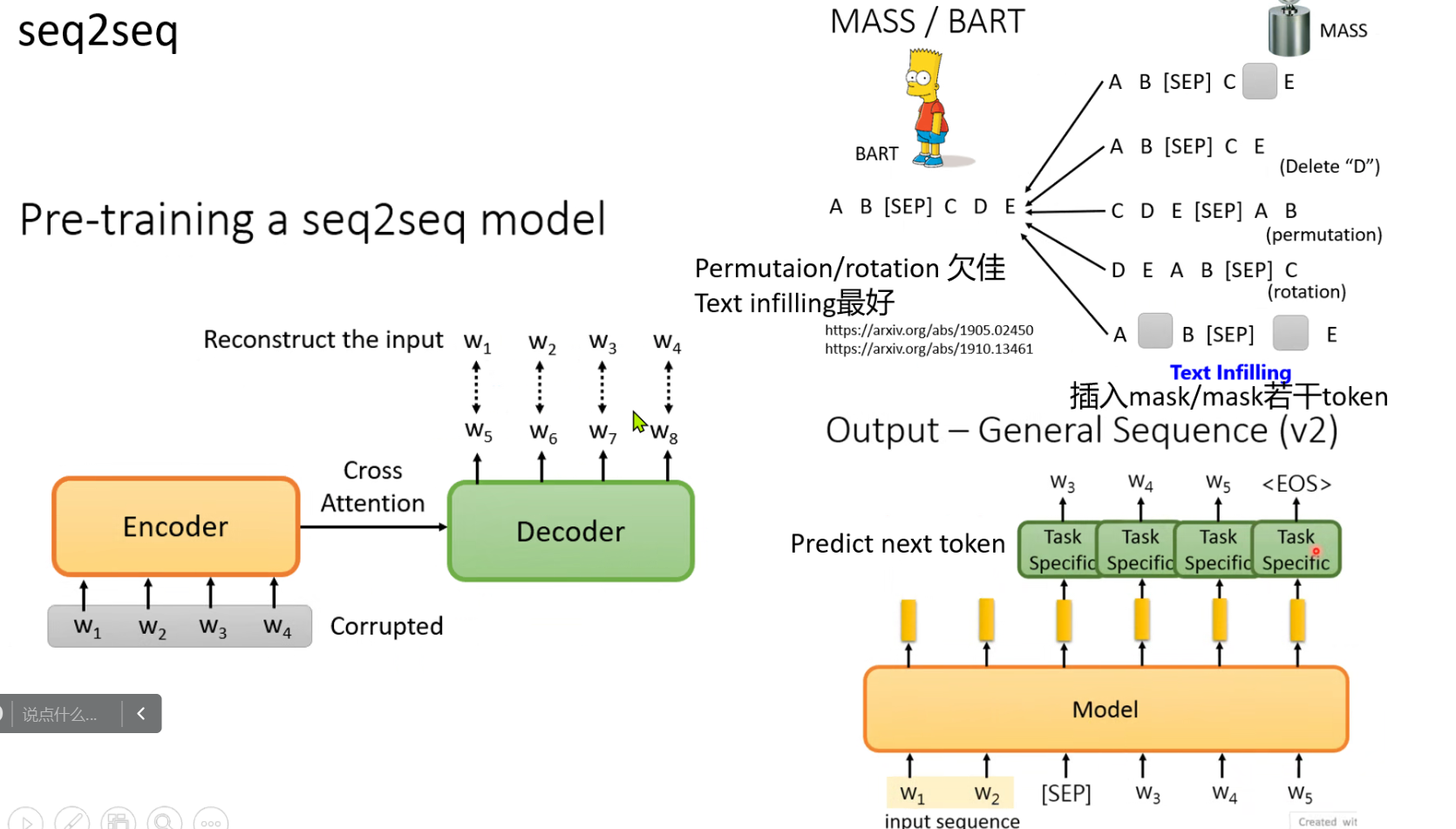
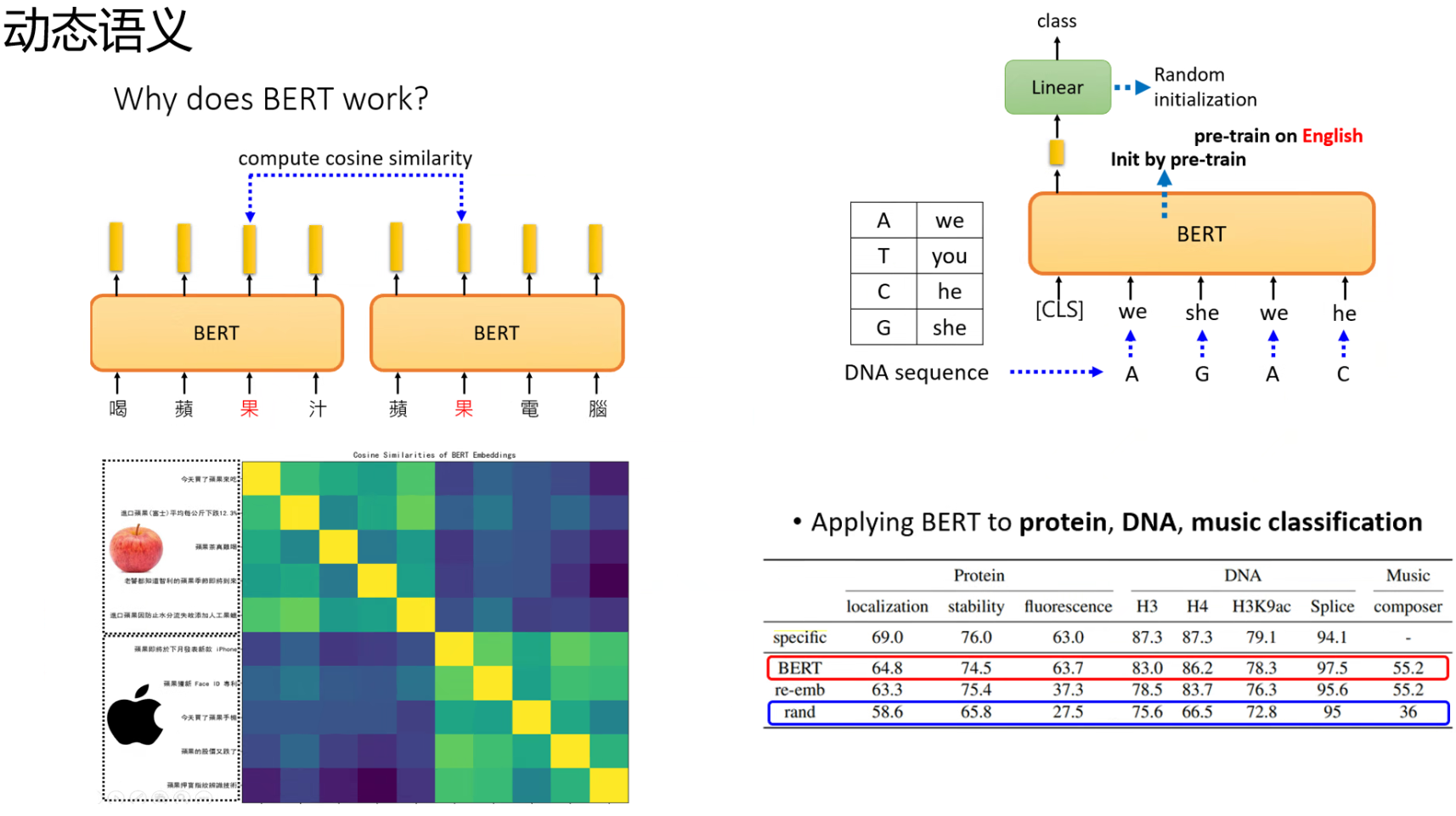
四、为什么BERT有用?
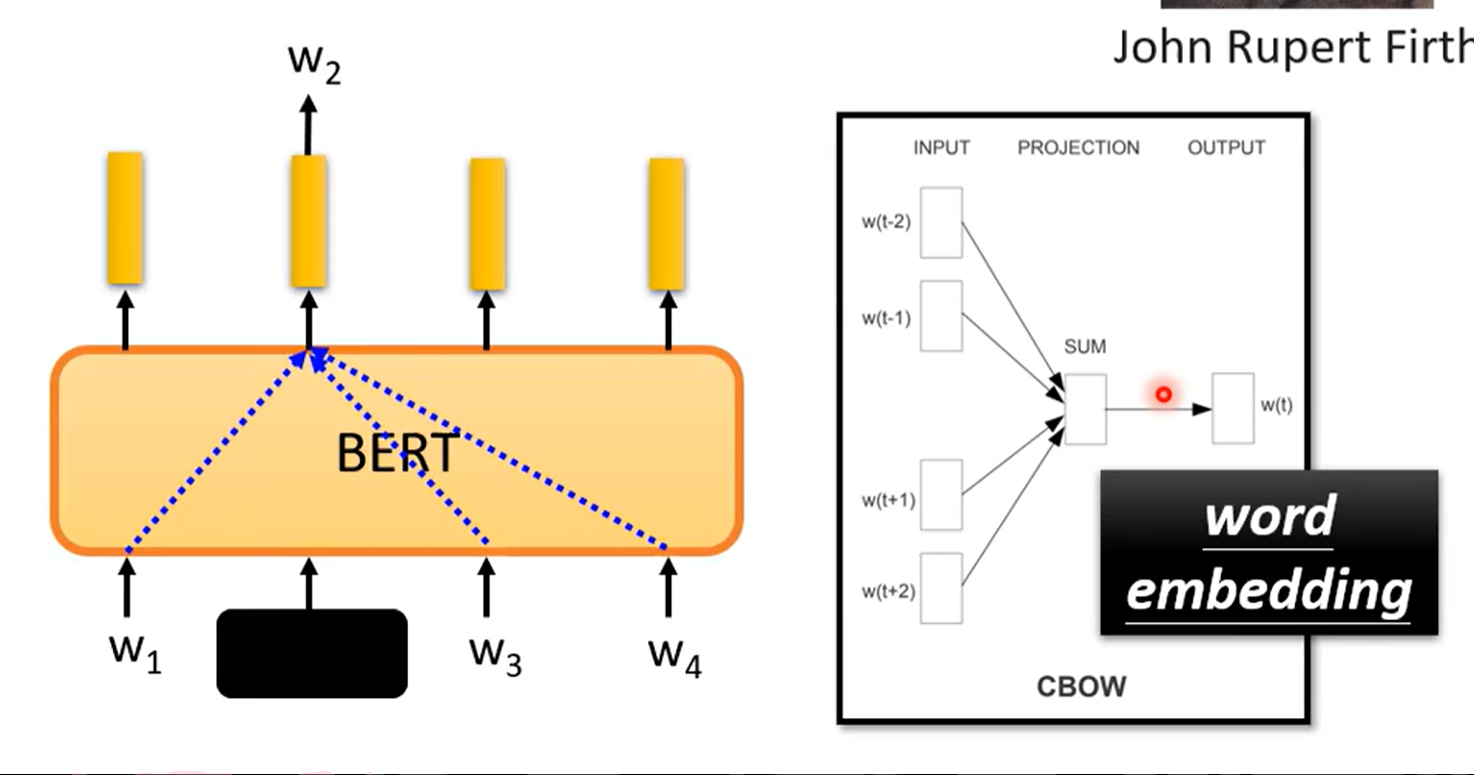
词嵌入。考虑上下文将token向量化。
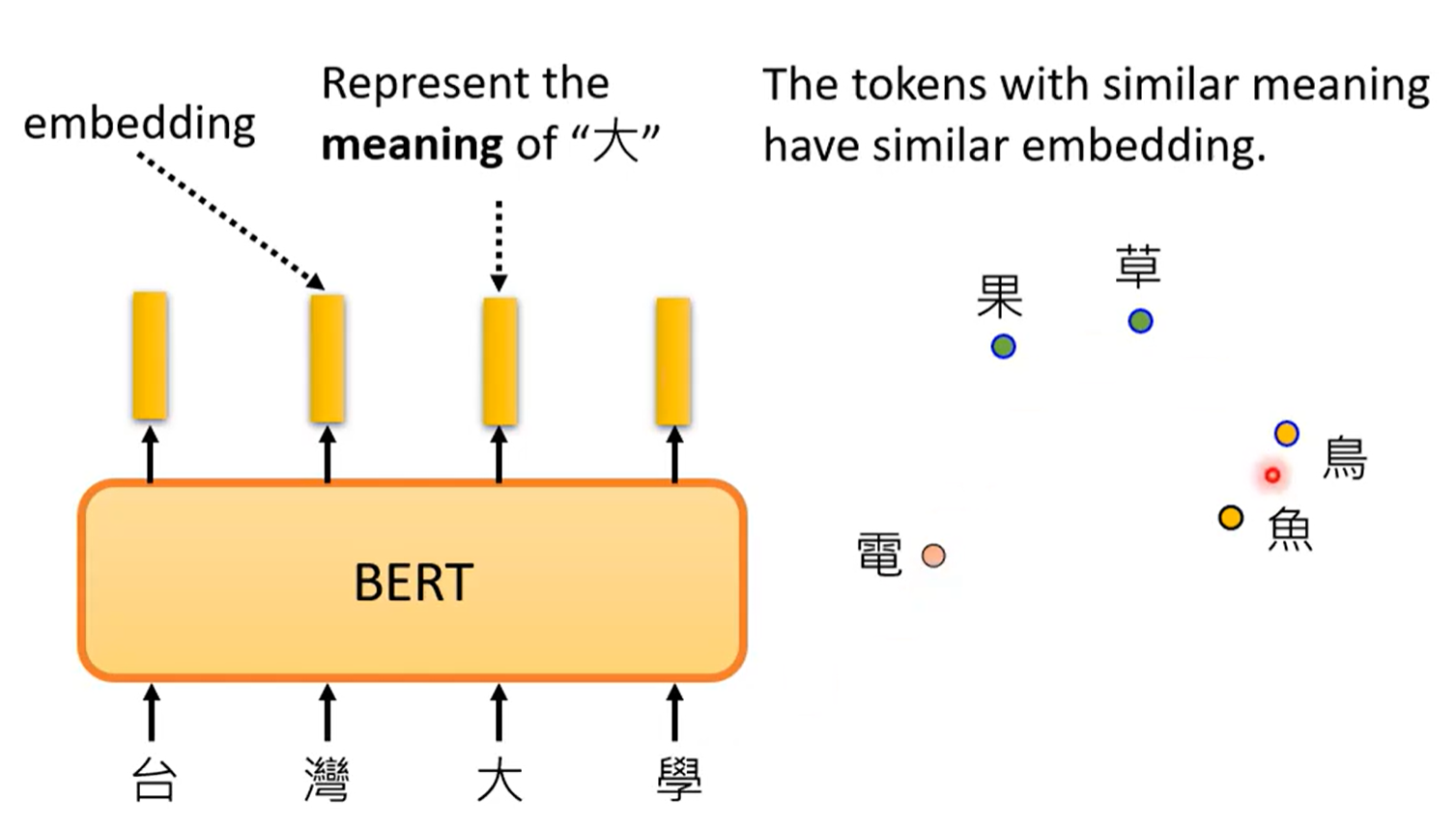
计算一下余弦相似度:即学会饿了区分“果”的不同。
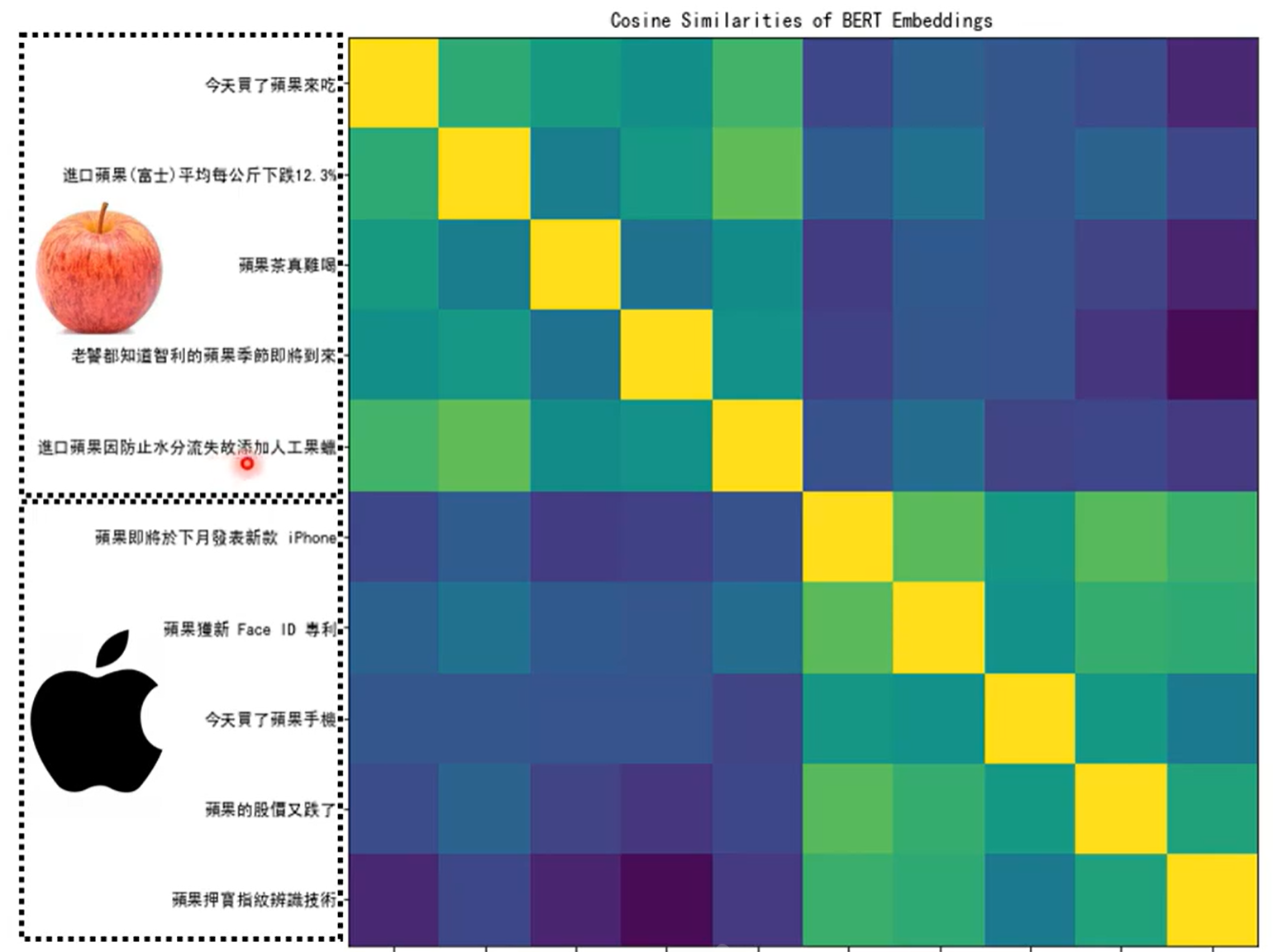
学会了文字的意思。
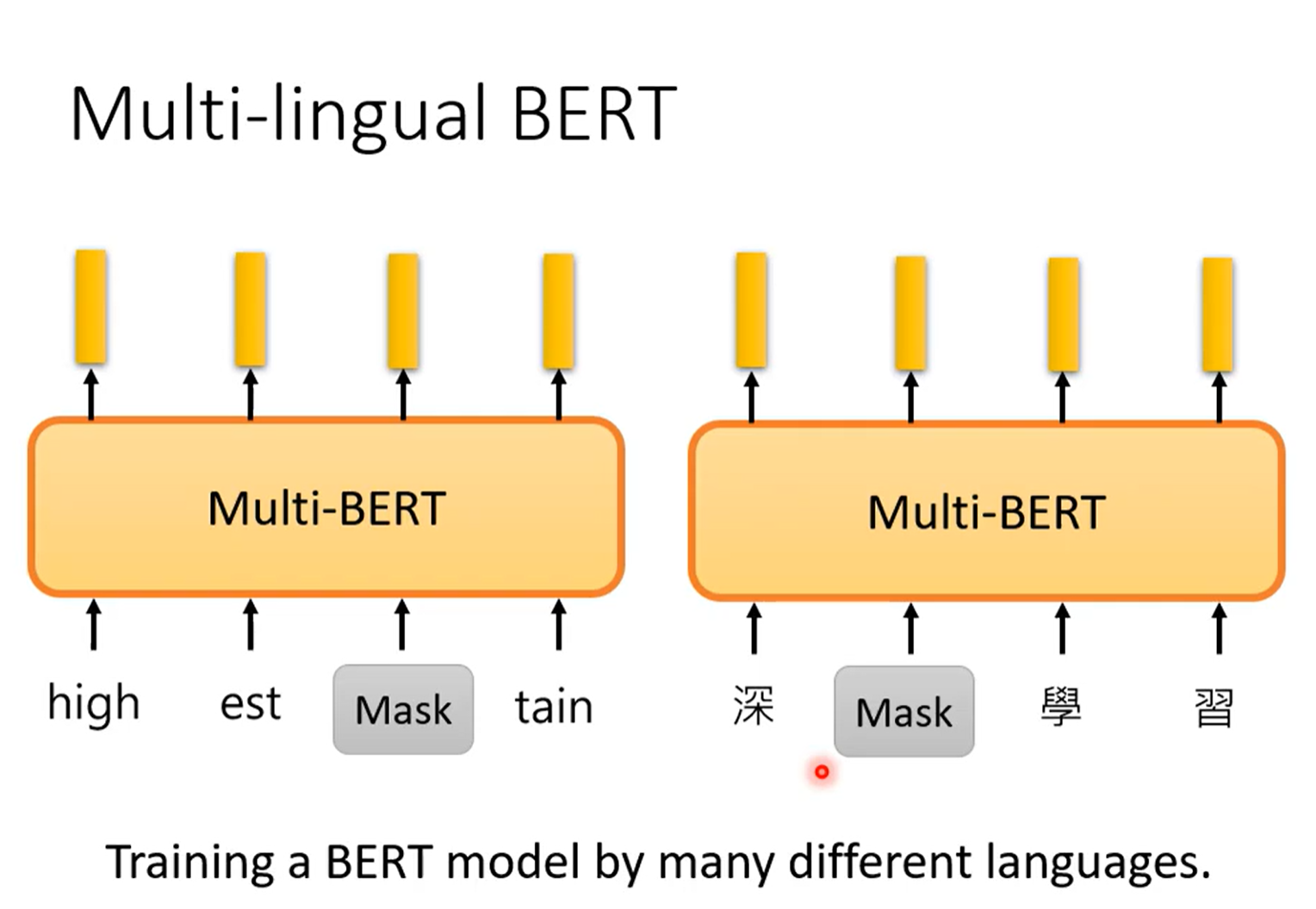
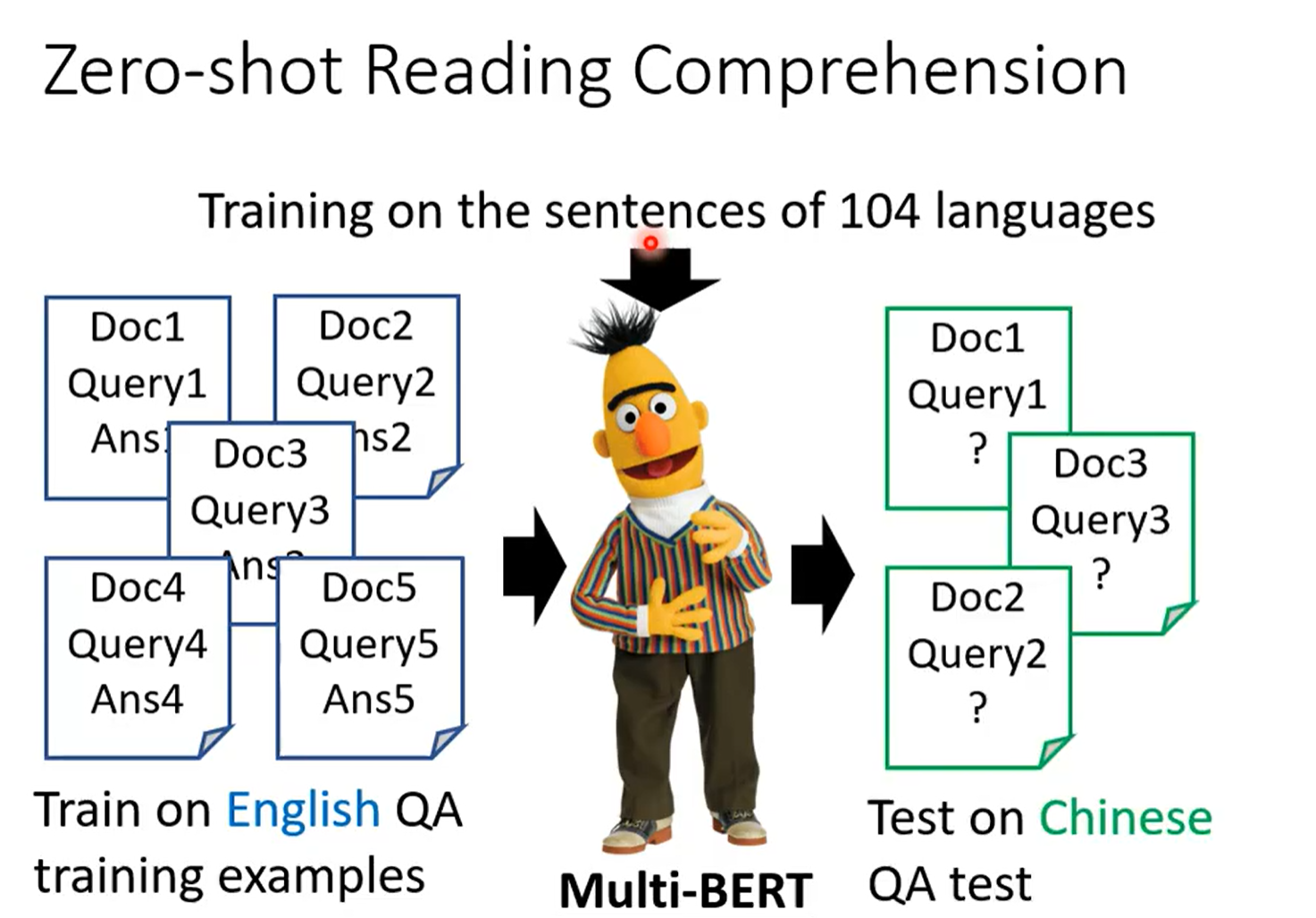
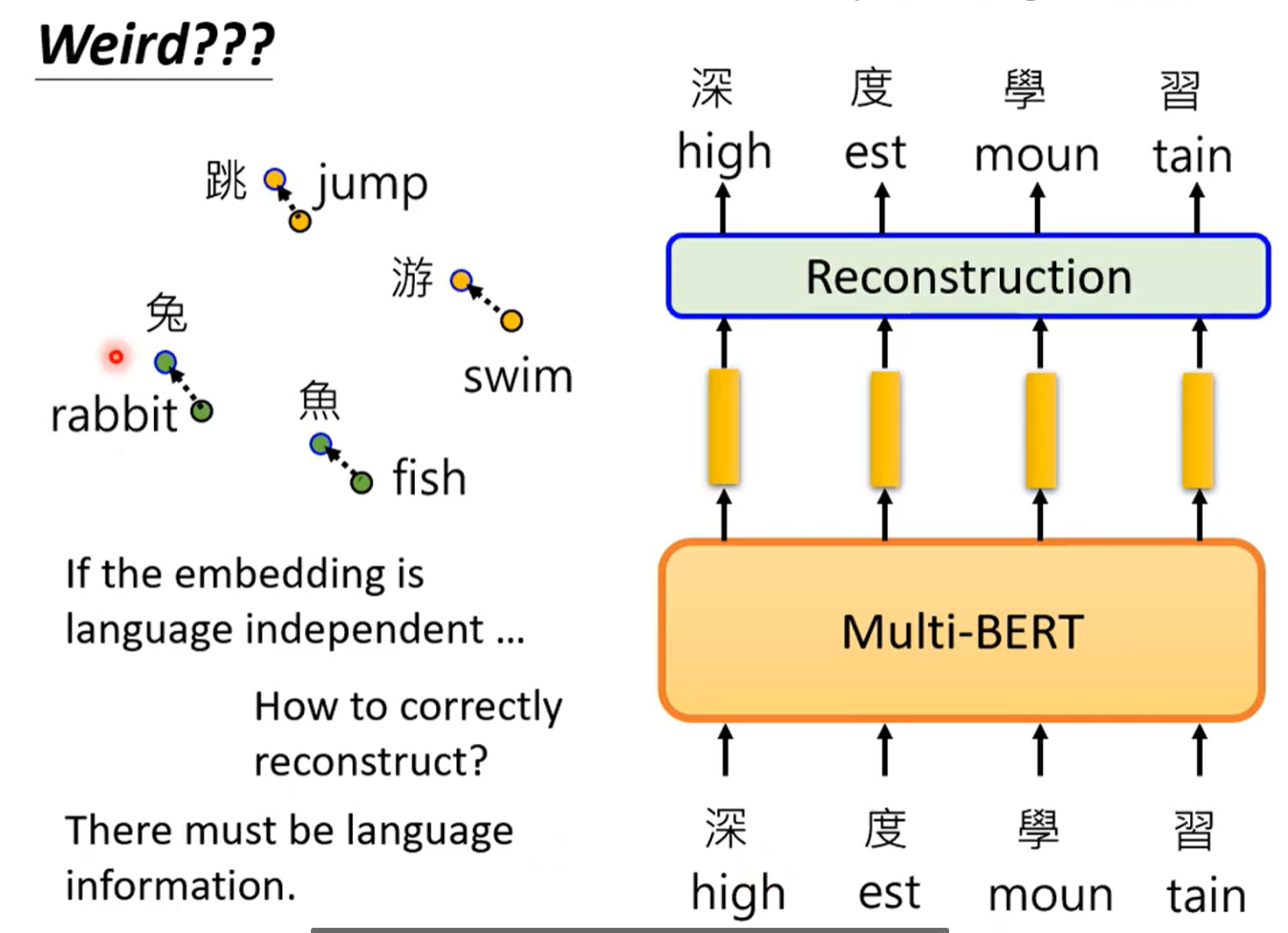
五、GPT
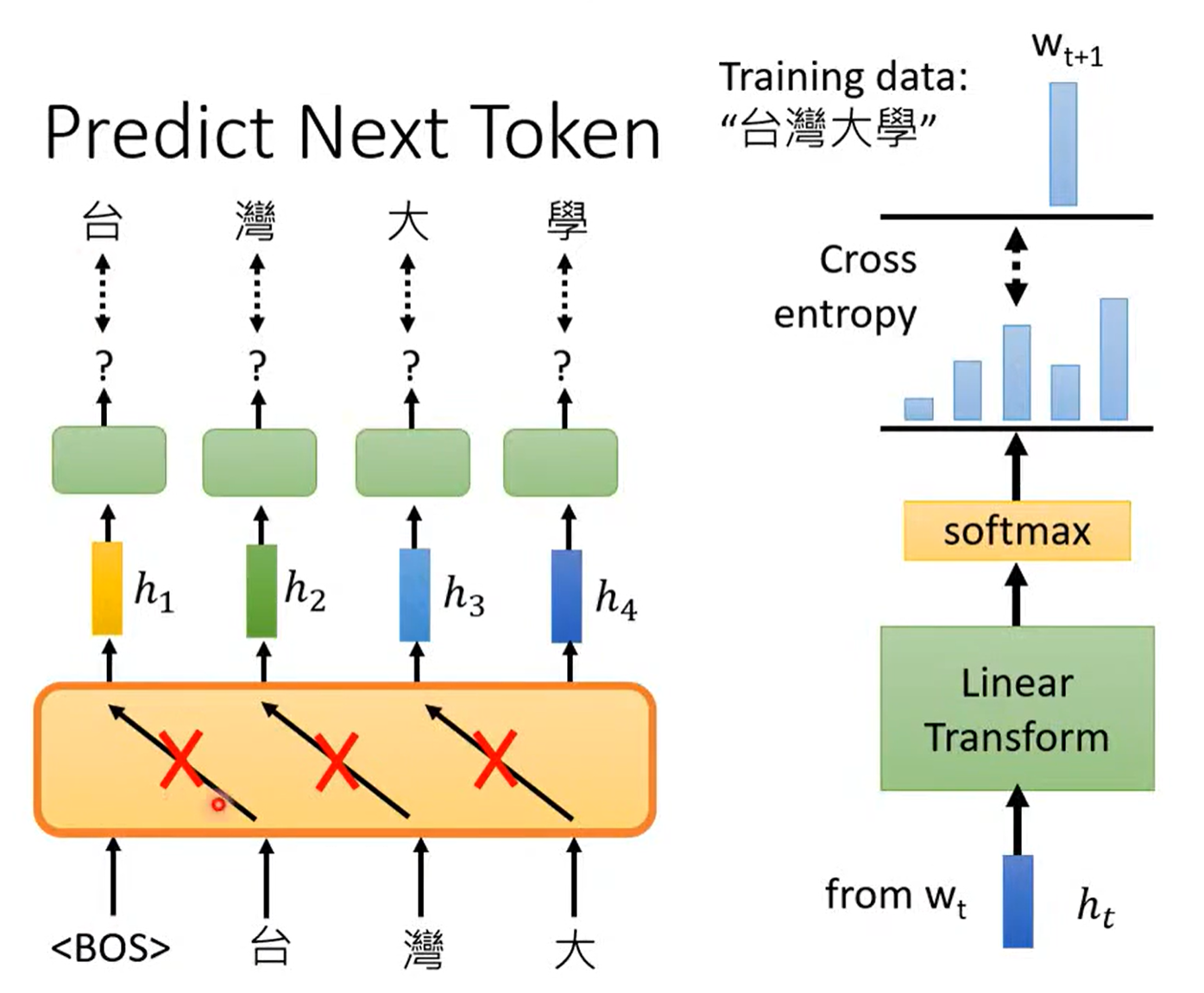
预测接下来的token。
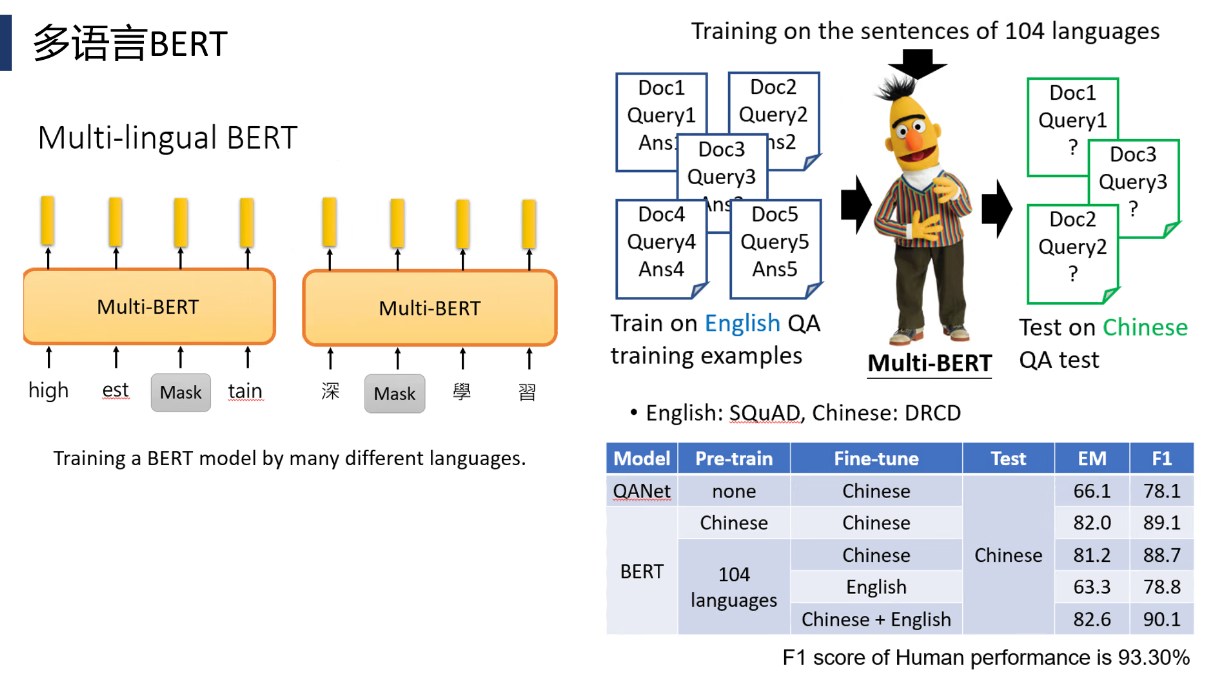
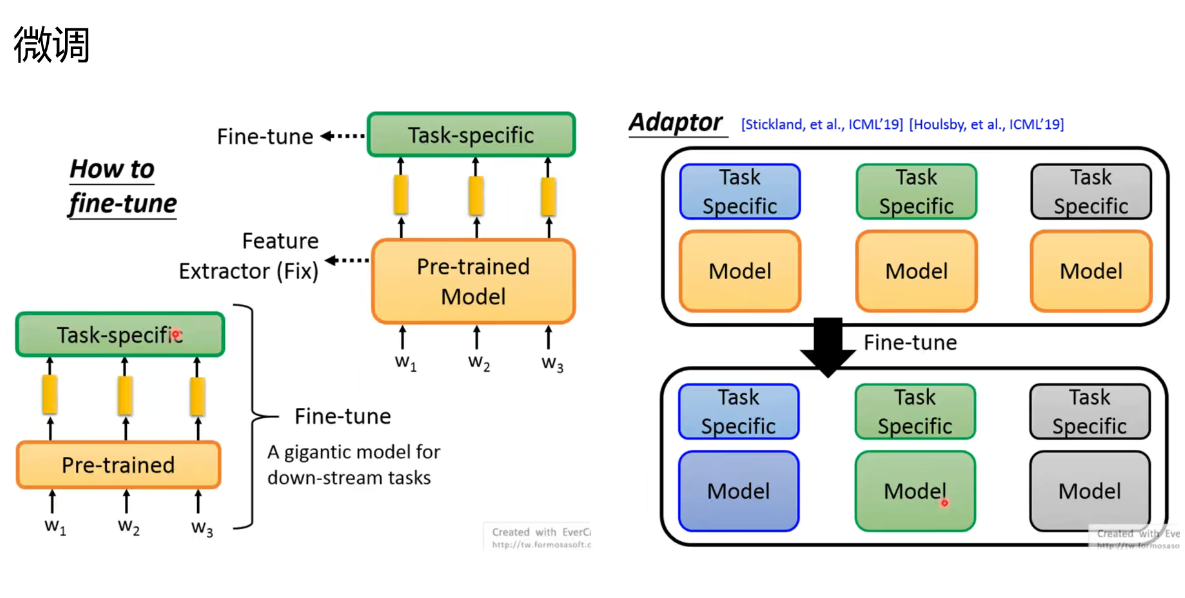
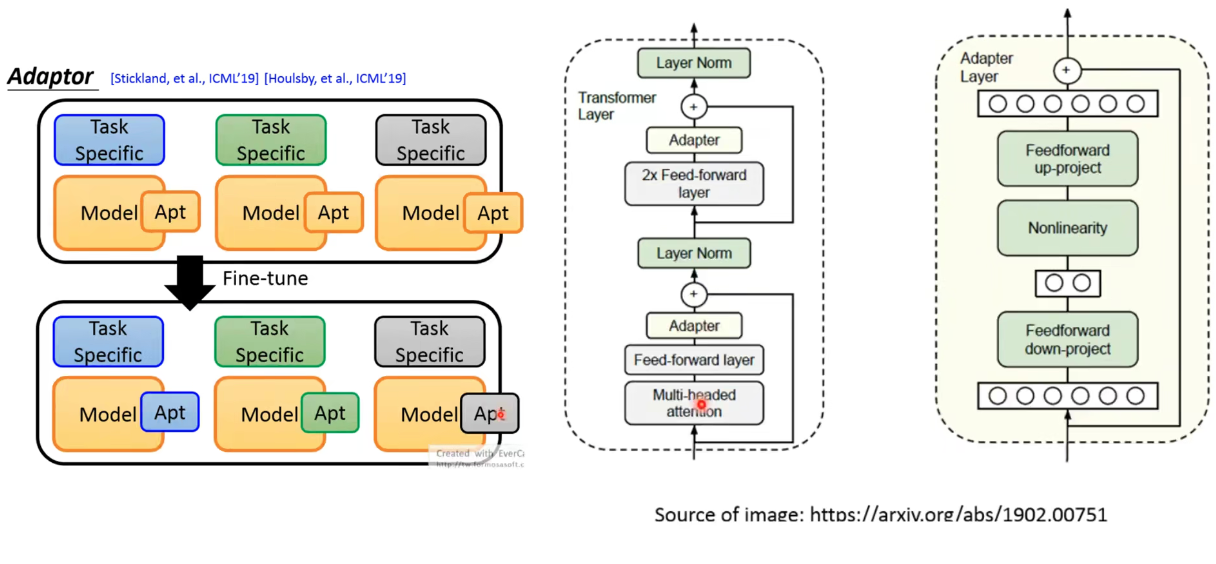
BERT和GPT区别:
Encoder和Decoder